理解Spark运行模式(三)(STANDALONE和Local)
前两篇介绍了Spark的yarn client和yarn cluster模式,本篇继续介绍Spark的STANDALONE模式和Local模式。
下面具体还是用计算PI的程序来说明,examples中该程序有三个版本,分别采用Scala、Python和Java语言编写。本次用Java程序JavaSparkPi做说明。
package org.apache.spark.examples; import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.SparkSession; import java.util.ArrayList;
import java.util.List; /**
* Computes an approximation to pi
* Usage: JavaSparkPi [partitions]
*/
public final class JavaSparkPi { public static void main(String[] args) throws Exception {
SparkSession spark = SparkSession
.builder()
.appName("JavaSparkPi")
.getOrCreate(); JavaSparkContext jsc = new JavaSparkContext(spark.sparkContext()); int slices = (args.length == 1) ? Integer.parseInt(args[0]) : 2;
int n = 100000 * slices;
List<Integer> l = new ArrayList<>(n);
for (int i = 0; i < n; i++) {
l.add(i);
} JavaRDD<Integer> dataSet = jsc.parallelize(l, slices); int count = dataSet.map(integer -> {
double x = Math.random() * 2 - 1;
double y = Math.random() * 2 - 1;
return (x * x + y * y <= 1) ? 1 : 0;
}).reduce((integer, integer2) -> integer + integer2); System.out.println("Pi is roughly " + 4.0 * count / n); spark.stop();
}
}
程序逻辑与之前的Scala和Python程序一样,就不再多做说明了。对比Scala、Python和Java程序,同样计算PI的逻辑,程序分别是26行、30行和43行,可以看出编写Spark程序,使用Scala或者Python比Java来得更加简洁,因此推荐使用Scala或者Python编写Spark程序。
下面来以STANDALONE方式来执行这个程序,执行前需要启动Spark自带的集群服务(在master上执行$SPARK_HOME/sbin/start-all.sh),最好同时启动spark的history server,这样即使在程序运行完以后也可以从Web UI中查看到程序运行情况。启动Spark的集群服务后,会在master主机和slave主机上分别出现Master守护进程和Worker守护进程。而在Yarn模式下,就不需要启动Spark的集群服务,只需要在客户端部署Spark即可,而STANDALONE模式需要在集群每台机器都部署Spark。
输入以下命令:
[root@BruceCentOS4 jars]# $SPARK_HOME/bin/spark-submit --class org.apache.spark.examples.JavaSparkPi --master spark://BruceCentOS.Hadoop:7077 $SPARK_HOME/examples/jars/spark-examples_2.11-2.3.0.jar
以下是程序运行输出信息部分截图,
开始部分:
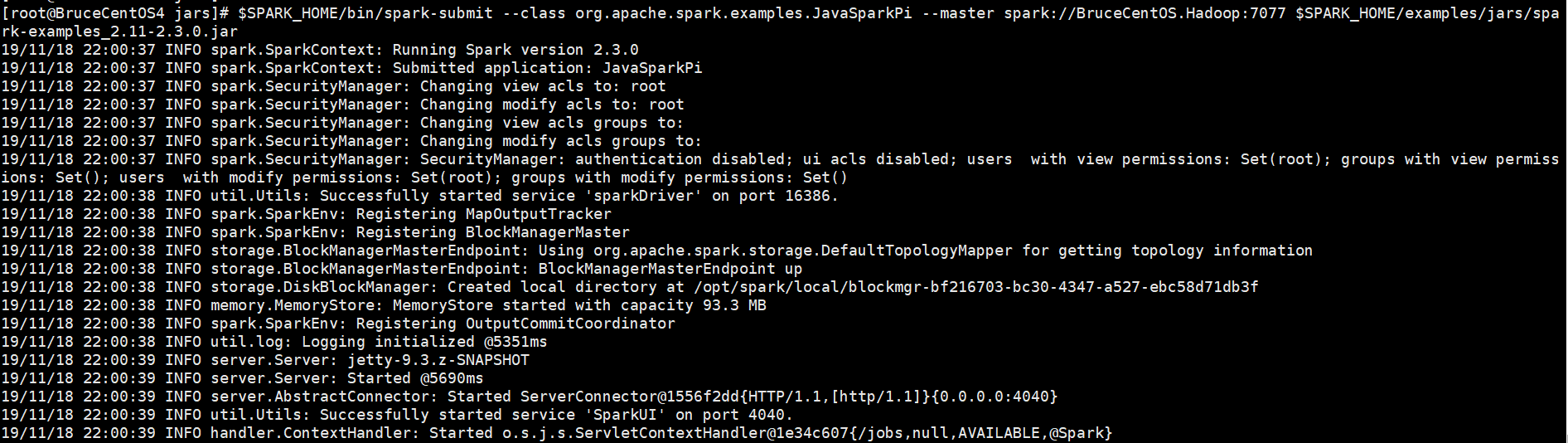
中间部分:
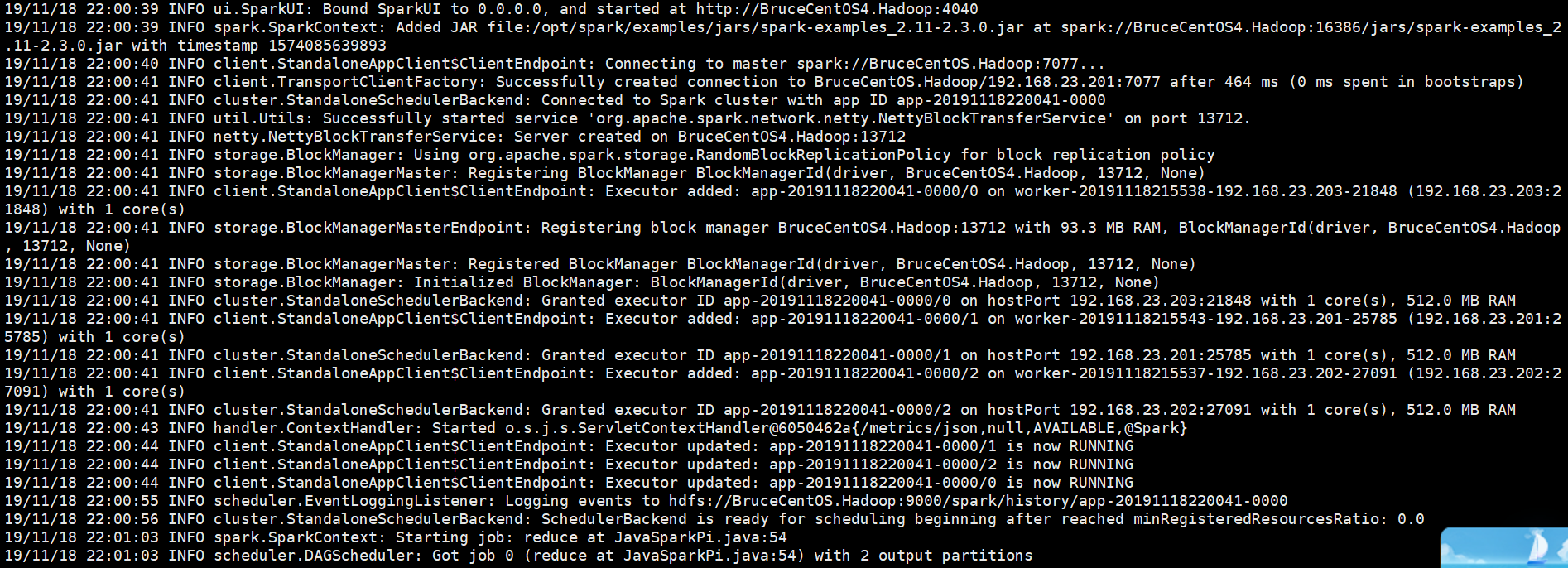
结束部分:
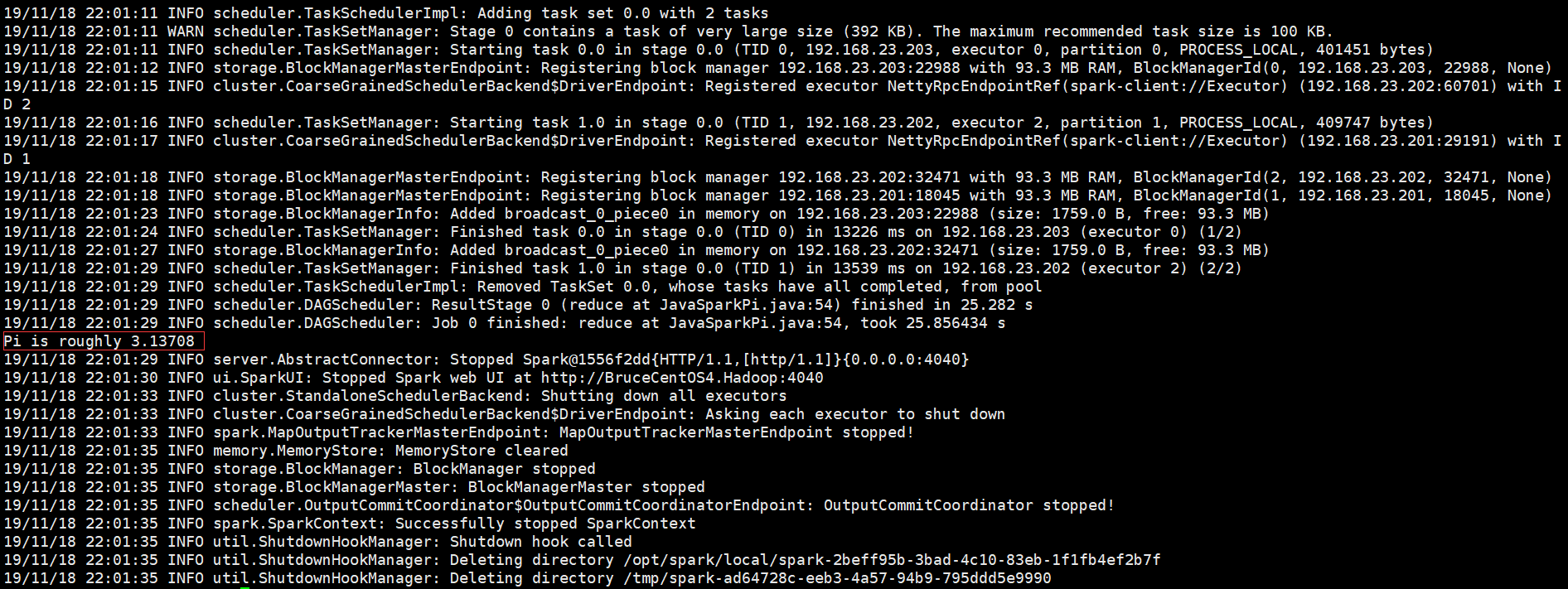
从上面的程序输出信息科看出,Spark Driver是运行在客户端BruceCentOS4上的SparkSubmit进程当中的,集群是Spark自带的集群。
SparkUI上的Executor信息:

BruceCentOS4上的客户端进程(包含Spark Driver):
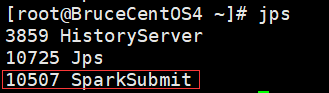
BruceCentOS3上的Executor进程:
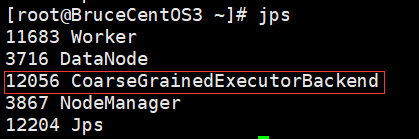
BruceCentOS上的Executor进程:
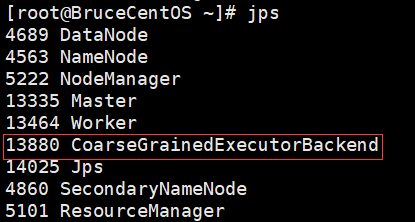
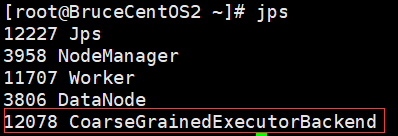
BruceCentOS2上的Executor进程:
下面具体描述下Spark程序在standalone模式下运行的具体流程。
这里是一个流程图:

- SparkContext连接到Master,向Master注册并申请资源(CPU Core 和Memory)。
- Master根据SparkContext的资源申请要求和Worker心跳周期内报告的信息决定在哪个Worker上分配资源,然后在该Worker上获取资源,然后启动CoarseGrainedExecutorBackend。
- CoarseGrainedExecutorBackend向SparkContext注册。
- SparkContext将Applicaiton代码发送给CoarseGrainedExecutorBackend;并且SparkContext解析Applicaiton代码,构建DAG图,并提交给DAG Scheduler分解成Stage(当碰到Action操作时,就会催生Job;每个Job中含有1个或多个Stage,Stage一般在获取外部数据和shuffle之前产生),然后以Stage(或者称为TaskSet)提交给Task Scheduler,Task Scheduler负责将Task分配到相应的Worker,最后提交给CoarseGrainedExecutorBackend执行。
- CoarseGrainedExecutorBackend会建立Executor线程池,开始执行Task,并向SparkContext报告,直至Task完成。
- 所有Task完成后,SparkContext向Master注销,释放资源。
最后来看Local运行模式,该模式就是在单机本地环境执行,主要用于程序测试。程序的所有部分,包括Client、Driver和Executor全部运行在客户端的SparkSubmit进程当中。Local模式有三种启动方式。
#启动1个Executor运行任务(1个线程)
[root@BruceCentOS4 ~]#$SPARK_HOME/bin/spark-submit --class org.apache.spark.examples.JavaSparkPi --master local $SPARK_HOME/examples/jars/spark-examples_2.11-2.3.0.jar
#启动N个Executor运行任务(N个线程),这里N=2
[root@BruceCentOS4 ~]#$SPARK_HOME/bin/spark-submit --class org.apache.spark.examples.JavaSparkPi --master local[2] $SPARK_HOME/examples/jars/spark-examples_2.11-2.3.0.jar
#启动*个Executor运行任务(*个线程),这里*指代本地机器上的CPU核的个数。
[root@BruceCentOS4 ~]#$SPARK_HOME/bin/spark-submit --class org.apache.spark.examples.JavaSparkPi --master local[*] $SPARK_HOME/examples/jars/spark-examples_2.11-2.3.0.jar
以上就是个人对Spark运行模式(STANDALONE和Local)的一点理解,其中参考了“求知若渴 虚心若愚”博主的“Spark(一): 基本架构及原理”的部分内容(其中基于Spark2.3.0对某些细节进行了修正),在此表示感谢。
理解Spark运行模式(三)(STANDALONE和Local)的更多相关文章
- Spark运行模式与Standalone模式部署
上节中简单的介绍了Spark的一些概念还有Spark生态圈的一些情况,这里主要是介绍Spark运行模式与Spark Standalone模式的部署: Spark运行模式 在Spark中存在着多种运行模 ...
- 理解Spark运行模式(二)(Yarn Cluster)
上一篇说到Spark的yarn client运行模式,它与yarn cluster模式的主要区别就是前者Driver是运行在客户端,后者Driver是运行在yarn集群中.yarn client模式一 ...
- 理解Spark运行模式(一)(Yarn Client)
Spark运行模式有Local,STANDALONE,YARN,MESOS,KUBERNETES这5种,其中最为常见的是YARN运行模式,它又可分为Client模式和Cluster模式.这里以Spar ...
- spark运行模式之二:Spark的Standalone模式安装部署
Spark运行模式 Spark 有很多种模式,最简单就是单机本地模式,还有单机伪分布式模式,复杂的则运行在集群中,目前能很好的运行在 Yarn和 Mesos 中,当然 Spark 还有自带的 Stan ...
- spark运行模式之一:Spark的local模式安装部署
Spark运行模式 Spark 有很多种模式,最简单就是单机本地模式,还有单机伪分布式模式,复杂的则运行在集群中,目前能很好的运行在 Yarn和 Mesos 中,当然 Spark 还有自带的 Stan ...
- spark运行模式
一.Spark运行模式 Spark有以下四种运行模式: local:本地单进程模式,用于本地开发测试Spark代码; standalone:分布式集群模式,Master-Worker架构,Master ...
- Scala进阶之路-Spark独立模式(Standalone)集群部署
Scala进阶之路-Spark独立模式(Standalone)集群部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们知道Hadoop解决了大数据的存储和计算,存储使用HDFS ...
- Spark运行模式概述
Spark编程模型的回顾 spark编程模型几大要素 RDD的五大特征 Application program的组成 运行流程概述 具体流程(以standalone模式为例) 任务调度 DAGSche ...
- Vsftpd运行的两种模式-xinetd运行模式和 standalone模式
vsftpd运行的两种模式-xinetd运行模式和 standalone模式 vsftpd提供了standalone和inetd(inetd或xinetd)两种运行模式. standalone一次性启 ...
随机推荐
- 单引号、双引号与定界符——PHP
单引号与双引号 单引号和双引号在echo输出时的区别 echo输出时,如果使用单引号,那么echo会把单引号之间的全部内容当成普通字符串输出,不能识别变量和转义字符(单引号串中的内容总被认为是普通字符 ...
- 代码审计-MetInfo 6.0.0 sql注入漏洞
首先漏洞存在于app\system\message\web\message.class.php文件中,变量{$_M[form][id]} 直接拼接在SQL语句中,且验证码检测函数是在SQL语句查询之后 ...
- PMP涉及的几个工作系统
PMP涉及的几个工作系统 工作系统作为事业环境因素,提高或限制项目管理的灵活性,并可能对项目结果产生积极或消极影响,包括项目管理系统.项目管理信息系统PMIS.配置管理系统.变更控制系统.合同变更 ...
- 初识mpvue
听说mpvue可以实现H5和小程序的同时开发 对使用过vue的选手几乎是0难度 忍不住搓搓小手手 看了文 唔~ 似乎不是很难的样子 然后实际上手操作了一下 老规矩:新建项目 npm install ...
- vue——前端跨域
***针对的是不同域名.不同协议的跨域: 1.找到config文件中开发环境的配置文件——dev.env.js,在里面将要跨域的域名配置进去 2.找到config文件中线上环境的配置文件——prod. ...
- Electron开发跨平台桌面程序入门教程
最近一直在学习 Electron 开发桌面应用程序,在尝试了 java swing 和 FXjava 后,感叹还是 Electron 开发桌面应用上手最快.我会在这一篇文章中实现一个HelloWord ...
- url中常见符号说明
如:http://10.1.1.71:9999/auditcenter/api/v1/auditPlanList?pageSize=20&page=1 ?:分隔实际的url和参数 & ...
- 基础安全术语科普(六)——exploit
exploit (漏洞利用) 利用漏洞存在两种攻击形式: 1.Remote(远程):利用系统漏洞来获得访问权限. 2.local(本地):需要对系统进行物理访问来实现攻击. 如何发现漏洞? 利用逆向工 ...
- Spring Cloud ---- 服务注册与发现(Eureka 找到了!找到了! 嘻嘻)
记录一下吧,为什么接触分布式.因为裸辞之后没有找到工作,好的公司都要求有分布式经验,但是我完全没有.在一次面试的时候,面试官说如果你会分布式架构的话,我可以把工资给你开高2.5,我就考虑着给我点时间, ...
- SpringBoot整合SSM(代码实现Demo)
SpringBoot整合SSM 如图所示: 一.数据准备: 数据库文件:数据库名:saas-export,表名:ss_company 创建表语句: DROP TABLE IF EXISTS ss_co ...