理解Spark运行模式(二)(Yarn Cluster)
上一篇说到Spark的yarn client运行模式,它与yarn cluster模式的主要区别就是前者Driver是运行在客户端,后者Driver是运行在yarn集群中。yarn client模式一般用在交互式场景中,比如spark shell, spark sql等程序,但是该模式下运行在客户端的Driver与Yarn集群有大量的网络交互,如果客户端与集群之间的网络不是很好,可能会导致性能问题。因此一般在生产环境中,大部分还是采用yarn cluster模式运行spark程序。
下面具体还是用计算PI的程序来说明,examples中该程序有三个版本,分别采用Scala、Python和Java语言编写。本次用Python程序pi.py做说明。
from __future__ import print_function import sys
from random import random
from operator import add from pyspark.sql import SparkSession if __name__ == "__main__":
"""
Usage: pi [partitions]
"""
spark = SparkSession\
.builder\
.appName("PythonPi")\
.getOrCreate() partitions = int(sys.argv[1]) if len(sys.argv) > 1 else 2
n = 100000 * partitions def f(_):
x = random() * 2 - 1
y = random() * 2 - 1
return 1 if x ** 2 + y ** 2 <= 1 else 0 count = spark.sparkContext.parallelize(range(1, n + 1), partitions).map(f).reduce(add)
print("Pi is roughly %f" % (4.0 * count / n)) spark.stop()
程序逻辑与上一篇Scala程序一样,就不再多做说明了。
下面来以yarn cluster方式来执行这个程序,注意执行程序前先要启动hdfs和yarn,最好同时启动spark的history server,这样即使在程序运行完以后也可以从Web UI中查看到程序运行情况。
输入以下命令:
[root@BruceCentOS4 ~]# $SPARK_HOME/bin/spark-submit --master yarn --deploy-mode cluster $SPARK_HOME/examples/src/main/python/pi.py
以下是程序运行输出信息部分截图,
开始部分:
中间部分:
结束部分:
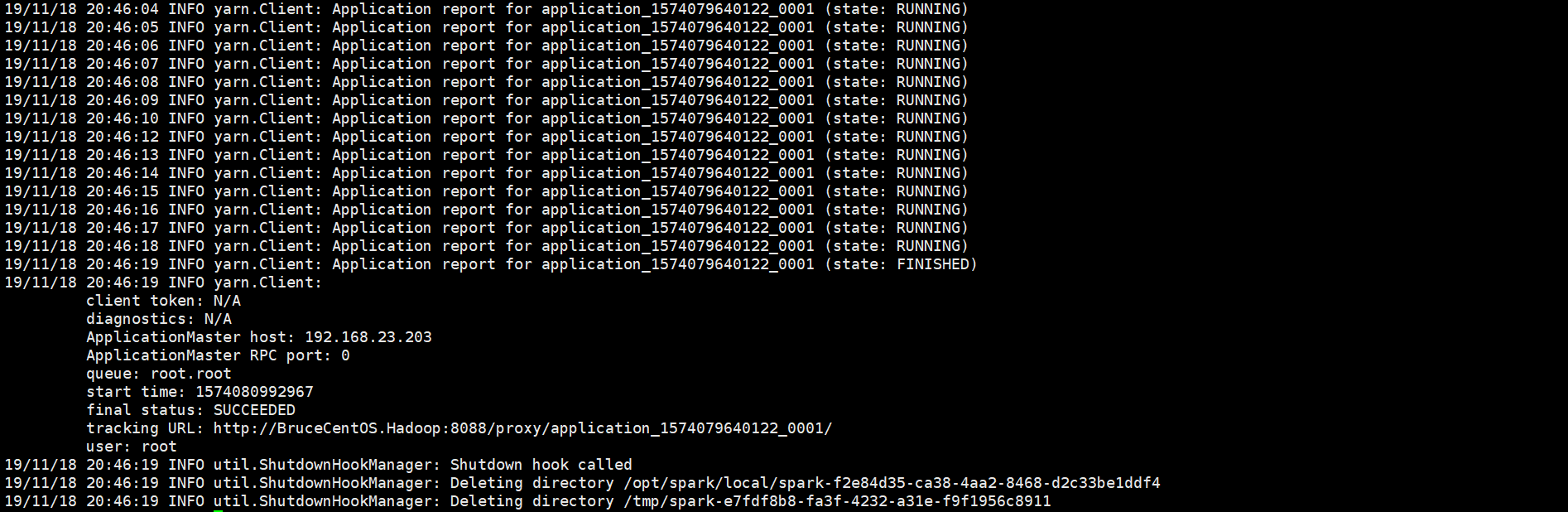
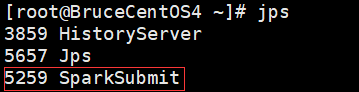
由于程序是以yarn cluster方式运行的,因此Driver是运行在Yarn集群当中(在BruceCentOS3上的ApplicationMaster进程当中),同时在BruceCentOS和BruceCentOS2上各运行了1个Executor进程(进程名字:CoarseGrainedExecutorBackend),而BruceCentOS4上的SparkSubmit进程仅仅作为yarn client向yarn集群提交spark程序。作为对比,在yarn client模式当中,客户端SparkSubmit进程不仅作为yarn client提交程序,而且同时还会运行Driver,并启动SparkContext,并且向Executor分配和管理Task,最后收集运行结果,因此yarn client模式程序输出信息会显示最终的打印结果。然而在yarn cluster模式当中,由于Driver运行在yarn集群的ApplicationMaster中,因此最终结果需要到ApplicationMaster进程的日志中取查看。可以通过如下命令查看。

SparkUI上的Executor信息:

BruceCentOS4上的客户端进程:
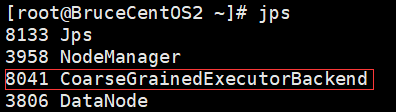
BruceCentOS3上的ApplicationMaster进程(包含Spark Driver):
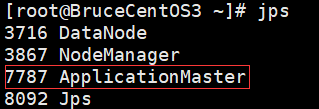
BruceCentOS上的Executor:
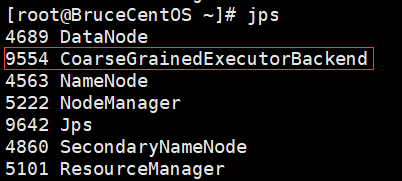
BruceCentOS2上的Executor:
下面具体描述下Spark程序在yarn cluster模式下运行的具体流程。
这里是一个流程图:
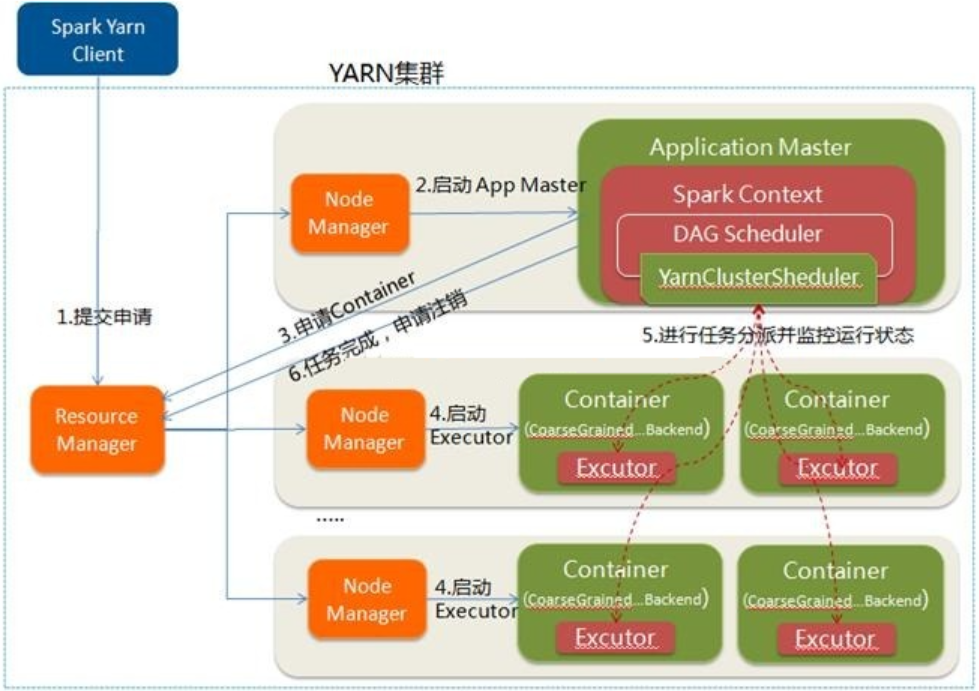
- Spark Yarn Client向YARN提交应用程序,类似于MapReduce向Yarn提交程序,会将程序文件、库文件和配置文件等上传到HDFS。
- ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,其中ApplicationMaster中会运行Spark Driver,并进行SparkContext的初始化。
- ApplicationMaster向ResourceManager注册,这样用户可以直接通过ResourceManager查看应用程序的运行状态,然后它将采用轮询的方式通过RPC协议为各个任务申请资源,并监控它们的运行状态直到运行结束。
- 一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向ApplicationMaster中的SparkContext注册并申请Task。这一点和Standalone模式一样,只不过SparkContext在Spark Application中初始化时,使用CoarseGrainedSchedulerBackend配合YarnClusterScheduler进行任务的调度。
- ApplicationMaster中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向ApplicationMaster汇报运行的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。
- 应用程序运行完成后,ApplicationMaster向ResourceManager申请注销并关闭自己。
以上就是个人对Spark运行模式(yarn cluster)的一点理解,其中参考了“求知若渴 虚心若愚”博主的“Spark(一): 基本架构及原理”的部分内容(其中基于Spark2.3.0对某些细节进行了修正),在此表示感谢。
理解Spark运行模式(二)(Yarn Cluster)的更多相关文章
- 理解Spark运行模式(一)(Yarn Client)
Spark运行模式有Local,STANDALONE,YARN,MESOS,KUBERNETES这5种,其中最为常见的是YARN运行模式,它又可分为Client模式和Cluster模式.这里以Spar ...
- 理解Spark运行模式(三)(STANDALONE和Local)
前两篇介绍了Spark的yarn client和yarn cluster模式,本篇继续介绍Spark的STANDALONE模式和Local模式. 下面具体还是用计算PI的程序来说明,examples中 ...
- spark运行模式之二:Spark的Standalone模式安装部署
Spark运行模式 Spark 有很多种模式,最简单就是单机本地模式,还有单机伪分布式模式,复杂的则运行在集群中,目前能很好的运行在 Yarn和 Mesos 中,当然 Spark 还有自带的 Stan ...
- Spark运行模式:cluster与client
When run SparkSubmit --class [mainClass], SparkSubmit will call a childMainClass which is 1. client ...
- Spark运行模式与Standalone模式部署
上节中简单的介绍了Spark的一些概念还有Spark生态圈的一些情况,这里主要是介绍Spark运行模式与Spark Standalone模式的部署: Spark运行模式 在Spark中存在着多种运行模 ...
- spark运行模式
一.Spark运行模式 Spark有以下四种运行模式: local:本地单进程模式,用于本地开发测试Spark代码; standalone:分布式集群模式,Master-Worker架构,Master ...
- spark运行模式之一:Spark的local模式安装部署
Spark运行模式 Spark 有很多种模式,最简单就是单机本地模式,还有单机伪分布式模式,复杂的则运行在集群中,目前能很好的运行在 Yarn和 Mesos 中,当然 Spark 还有自带的 Stan ...
- Spark运行模式概述
Spark编程模型的回顾 spark编程模型几大要素 RDD的五大特征 Application program的组成 运行流程概述 具体流程(以standalone模式为例) 任务调度 DAGSche ...
- Spark运行模式_spark自带cluster manager的standalone cluster模式(集群)
这种运行模式和"Spark自带Cluster Manager的Standalone Client模式(集群)"还是有很大的区别的.使用如下命令执行应用程序(前提是已经启动了spar ...
随机推荐
- Redis未授权访问写Webshell和公私钥认证获取root权限
0x01 什么是Redis未授权访问漏洞 Redis 默认情况下,会绑定在 0.0.0.0:,如果没有进行采用相关的策略,比如添加防火墙规则避免其他非信任来源 ip 访问等,这样将会将 Redis 服 ...
- Oracle报错注入总结
0x00 前言 在oracle注入时候出现了数据库报错信息,可以优先选择报错注入,使用报错的方式将查询数据的结果带出到错误页面中. 使用报错注入需要使用类似 1=[报错语句],1>[报错语句], ...
- MySQL生僻函数
0X01 字符串函数 STRCMP STRCMP(expr1,expr2) 若所有的字符串均相同,则返回STRCMP(),若根据当前分类次序,第一个参数小于第二个,则返回 -1,其它情况返回 1 . ...
- cinatra::http框架编译使用
cinatra 一个高效易用的c++ http框架 1.下载源码 https://github.com/qicosmos/cinatra 2. vs2017 编译boost库 [msvc-14.1] ...
- Libevent::evhttp服务器
#include <cstdio> #include <stdio.h> #include <stdlib.h> #include <string.h> ...
- Spring Boot Security And JSON Web Token
Spring Boot Security And JSON Web Token 说明 流程说明 何时生成和使用jwt,其实我们主要是token更有意义并携带一些信息 https://github.co ...
- JVM - 复习
内存模型图 程序计数器(PC) 程序计数器的特点 PC是一小块内存空间,用于记录当前线程执行的字节码指令的地址.如果执行的是本地方法(native),PC里此时显示Undefined 优点: 控制程序 ...
- JVM学习记录2--垃圾回收算法
首先要明确,垃圾回收管理jvm的堆内存,方法区是堆内存的一部分,所以也是. 而本地方法栈,虚拟机栈,程序计数器随着线程开始而产生,线程的结束而消亡,是不需要垃圾回收的. 1. 判断对象是否可以被回收 ...
- 类和对象(day19整理)
目录 面对对象和面对过程编程 什么是面向对象 什么是面向过程编程 什么是面对对象编程 类 类的定义 定义类时发生的事情 __dict__和. 对象 名称空间 __init__函数 调用类发生的事情 对 ...
- 【Java必修课】通过Value获取Map中的键值Key的四种方法
1 简介 我们都知道Map是存放键值对<Key,Value>的容器,知道了Key值,使用方法Map.get(key)能快速获取Value值.然而,有的时候我们需要反过来获取,知道Value ...