Hive的JDBC连接
首相要安装好hive
1.首先修改配置文件文件为hive 路径下的 conf/hive-sit.xml
将内容增加
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
<description>Port number of HiveServer2 Thrift interface.
Can be overridden by setting $HIVE_SERVER2_THRIFT_PORT</description>
</property> <property>
<name>hive.server2.thrift.bind.host</name>
<value>0.0.0.0</value>
<description>Bind host on which to run the HiveServer2 Thrift interface.
Can be overridden by setting $HIVE_SERVER2_THRIFT_BIND_HOST</description>
</property>
这个是hiveserver2需要的端口等内容
2.进入hive目录执行

如果没有日志的话可能什么都不输出
然后打开新的终端输入

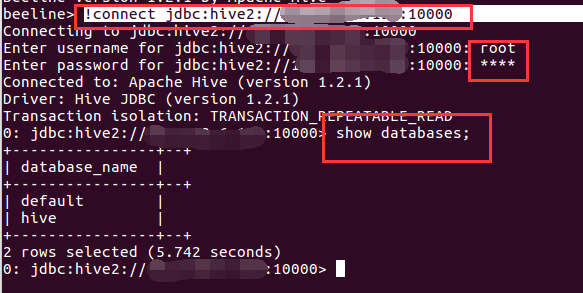
3.然后输入连接信息
执行命令
!connect jdbc:hive2://127.0.0.1:10000
然后输入之前设置的用户名密码(我的是mysql的用户名密码)
然后回车即连接成功。
可以输入sql进行测试
Hive的JDBC连接的更多相关文章
- 通过JDBC连接hive
hive是大数据技术簇中进行数据仓库应用的基础组件,是其它类似数据仓库应用的对比基准.基础的数据操作我们可以通过脚本方式以hive-client进行处理.若需要开发应用程序,则需要使用hive的jdb ...
- 基于CDH5.x 下面使用eclipse 操作hive 。使用java通过jdbc连接HIVESERVICE 创建表
基于CDH5.x 下面使用eclipse 操作hive .使用java通过jdbc连接HIVESERVICE 创建表 import java.sql.Connection; import java.s ...
- Kettle jdbc连接hive出现问题
jdbc连接时报如下错误: Error connecting to database [k] : org.pentaho.di.core.exception.KettleDatabaseExcepti ...
- 大数据系列之数据仓库Hive命令使用及JDBC连接
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- Hive(3)-meta store和hdfs详解,以及JDBC连接Hive
一. Meta Store 使用mysql客户端登录hadoop100的mysql,可以看到库中多了一个metastore 现在尤其要关注这三个表 DBS表,存储的是Hive的数据库 TBLS表,存储 ...
- Hive:用Java代码通过JDBC连接Hiveserver
参考https://www.iteblog.com/archives/846.html 1.hive依赖hadoop,将hdfs当作文件存储介质,那是否意味着hive需要知道namenode的地址? ...
- Java使用JDBC连接Hive
最近一段时间,处理过一个问题,那就是hive jdbc的连接问题,其实也不是大问题,就是url写的不对,导致无法连接.问题在于HiveServer2增加了别的安全验证,导致正常的情况下,传递的参数无法 ...
- 大数据学习day28-----hive03------1. null值处理,子串,拼接,类型转换 2.行转列,列转行 3. 窗口函数(over,lead,lag等函数) 4.rank(行号函数)5. json解析函数 6.jdbc连接hive,企业级调优
1. null值处理,子串,拼接,类型转换 (1) 空字段赋值(null值处理) 当表中的某个字段为null时,比如奖金,当你要统计一个人的总工资时,字段为null的值就无法处理,这个时候就可以使用N ...
- Hive(三):SQuirrel连接hive配置
熟悉了Sqlserver的sqlserver management studio.Oracle的PL/SQL可视化数据库查询分析工具,在刚开始使用hive.phoenix等类sql组件时,一直在苦苦搜 ...
随机推荐
- kibana 设置登录认证
kibana 设置登录认证 SlowGO 2018.11.21 14:56 字数 59 阅读 658评论 0喜欢 0 kibana 本身没有用户名密码的设置,可以使用 nginx 来实现. 步骤 (1 ...
- POJ1149 PIGS 【最大流 + 构图】
题目链接:http://poj.org/problem?id=1149 PIGS Time Limit: 1000MS Memory Limit: 10000K Total Submissions ...
- UWP笔记-边框背景虚化效果
这是一个简单的UI外观 1.添加Negut包: Microsoft.Toolkit.Uwp.UI.Controls 2.xaml:命名空间中引用 xmlns:controls="using: ...
- uva 1400 "Ray, Pass me the dishes!" (区间合并 最大子段和+输出左右边界)
题目链接:https://vjudge.net/problem/UVA-1400 题意:给一串序列,求最大子段,如果有多个,输出字典序最小的那个的左右端点 思路: 之前写过类似的,这个麻烦点需要输出左 ...
- 【AtCoder】Mujin Programming Challenge 2017
Mujin Programming Challenge 2017 A - Robot Racing 如果每个数都是一个一个间隔开的,那么答案是\(n!\) 考虑把一个数挪到1,第二个数挪到3,以此类推 ...
- css走马灯,一步一停(专家介绍类型)
<div class="CON--cen-pd3 clear aniview slow" data-av-animation="fadeIn"> & ...
- 【Python基础】14_Python中的TODO注释
# TODO XXX... IDE中右键左下角,可显示当前项目所有的TODO
- 【第一季】CH09_FPGA多路分频器设计
[第一季]CH09_FPGA多路分频器设计 在第七节的学习中,笔者带大家通过一个入门必学的流水灯实验实现,快速掌握了VIVADO基于FPGA开发板的基本流程.考虑到很多初学者并没有掌握好Vivado ...
- Thinkphp解决phpExcel导出数据量大导致内存溢出
工作需要导出几万的数据量.操作比较频繁.之前数据在七八千是数据导出很慢.phpExcel是方便但是性能一般.现在改为使用csv导出数据:可以缓解内存压力,一次导出两三万是没问题的.当然服务器内存给力, ...
- 《深入理解 Java 虚拟机》学习 -- 类加载机制
<深入理解 Java 虚拟机>学习 -- 类加载机制 1. 概述 虚拟机把描述类的数据从 Class 文件加载到内存,并对数据进行校验.转换解析和初始化,最终形成可以被虚拟机直接使用的 J ...