Hive的JDBC连接
首相要安装好hive
1.首先修改配置文件文件为hive 路径下的 conf/hive-sit.xml
将内容增加
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
<description>Port number of HiveServer2 Thrift interface.
Can be overridden by setting $HIVE_SERVER2_THRIFT_PORT</description>
</property> <property>
<name>hive.server2.thrift.bind.host</name>
<value>0.0.0.0</value>
<description>Bind host on which to run the HiveServer2 Thrift interface.
Can be overridden by setting $HIVE_SERVER2_THRIFT_BIND_HOST</description>
</property>
这个是hiveserver2需要的端口等内容
2.进入hive目录执行

如果没有日志的话可能什么都不输出
然后打开新的终端输入

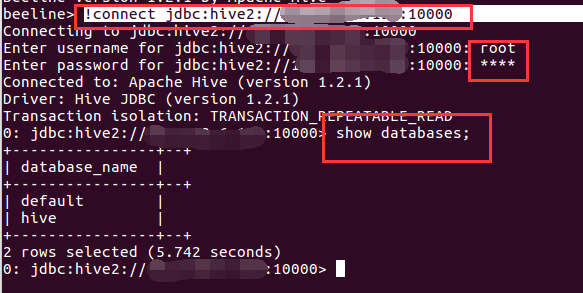
3.然后输入连接信息
执行命令
!connect jdbc:hive2://127.0.0.1:10000
然后输入之前设置的用户名密码(我的是mysql的用户名密码)
然后回车即连接成功。
可以输入sql进行测试
Hive的JDBC连接的更多相关文章
- 通过JDBC连接hive
hive是大数据技术簇中进行数据仓库应用的基础组件,是其它类似数据仓库应用的对比基准.基础的数据操作我们可以通过脚本方式以hive-client进行处理.若需要开发应用程序,则需要使用hive的jdb ...
- 基于CDH5.x 下面使用eclipse 操作hive 。使用java通过jdbc连接HIVESERVICE 创建表
基于CDH5.x 下面使用eclipse 操作hive .使用java通过jdbc连接HIVESERVICE 创建表 import java.sql.Connection; import java.s ...
- Kettle jdbc连接hive出现问题
jdbc连接时报如下错误: Error connecting to database [k] : org.pentaho.di.core.exception.KettleDatabaseExcepti ...
- 大数据系列之数据仓库Hive命令使用及JDBC连接
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- Hive(3)-meta store和hdfs详解,以及JDBC连接Hive
一. Meta Store 使用mysql客户端登录hadoop100的mysql,可以看到库中多了一个metastore 现在尤其要关注这三个表 DBS表,存储的是Hive的数据库 TBLS表,存储 ...
- Hive:用Java代码通过JDBC连接Hiveserver
参考https://www.iteblog.com/archives/846.html 1.hive依赖hadoop,将hdfs当作文件存储介质,那是否意味着hive需要知道namenode的地址? ...
- Java使用JDBC连接Hive
最近一段时间,处理过一个问题,那就是hive jdbc的连接问题,其实也不是大问题,就是url写的不对,导致无法连接.问题在于HiveServer2增加了别的安全验证,导致正常的情况下,传递的参数无法 ...
- 大数据学习day28-----hive03------1. null值处理,子串,拼接,类型转换 2.行转列,列转行 3. 窗口函数(over,lead,lag等函数) 4.rank(行号函数)5. json解析函数 6.jdbc连接hive,企业级调优
1. null值处理,子串,拼接,类型转换 (1) 空字段赋值(null值处理) 当表中的某个字段为null时,比如奖金,当你要统计一个人的总工资时,字段为null的值就无法处理,这个时候就可以使用N ...
- Hive(三):SQuirrel连接hive配置
熟悉了Sqlserver的sqlserver management studio.Oracle的PL/SQL可视化数据库查询分析工具,在刚开始使用hive.phoenix等类sql组件时,一直在苦苦搜 ...
随机推荐
- 磁盘分区知识与linux系统分区实践
一.磁盘存储逻辑结构图 回忆: (1)什么是分区? 磁盘分区就相当于给磁盘打隔断. (2)磁盘在linux里的命名 IDE /dev/hda hdb SCSI sda sdb 分区 ...
- HDU - 2196(树形DP)
题目: A school bought the first computer some time ago(so this computer's id is 1). During the recent ...
- QT 打包exe
QT打包主要方法: 1.把无措的代码进行Release编译 2.在运行完后,找到运行后生成的目录,以下是我的文件,名为result,运行类型有两种,一种是Debug,另一种是Release,我们需要的 ...
- idea 编辑器Git暂存区的使用
平时在开发时候 一般线上环境和线下环境区别会很大,所以一下线下的自己测试环境的代码没有如果提交会影响线上环境,所以一般都会使用git的一个暂存区作为临时存放不需要提交的代码,这样每次提交代码都可以在不 ...
- MySQL Select语句的执行顺序
源文章:How is a query executed in MySQL? 当执行SQL的Select查询语句时,SQL指令的执行顺序如下: FROM 子句 WHERE 子句 GROUP BY 子句 ...
- ideaIU-2019.2.exe-安装目录和设置目录结构的说明
一.查看安装目录结构 bin: 容器,执行文件和启动参数等 help:快捷键文档和其他帮助文档 jbr: 含有java运行环境 lib:idea 依赖的类库 license:各个插件许可 plugin ...
- Js 判断数组中是否包含某个值
includes() 方法用来判断一个数组是否包含一个指定的值,如果是返回 true,否则false. JavaScript Array includes() 方法
- codeblocks 使用汇总
codeblocks 使用汇总 http://www.cnblogs.com/-clq/archive/2012/01/31/2333247.html
- CodeFirst与EntityFramework【续】
3. 实现一对一的关系.在介绍一对多关系和多对多关系时,大家应该已经注意到了只要存在依赖关系的两个类的定义中包含对方的实例或实例的集合,Entity Framework Code First会自 ...
- spark2.0新特性之DataSet
1.Spark SQL,DataFrame,DataSet的错误类型检测时机 spark SQL:其类型检测与语法检测是在运行时检测的 DataFrame:在spark2.0以前的版本中,DataFr ...