NLP基础
1 自然语言处理三大特征抽取器(CNN/RNN/TF)比较


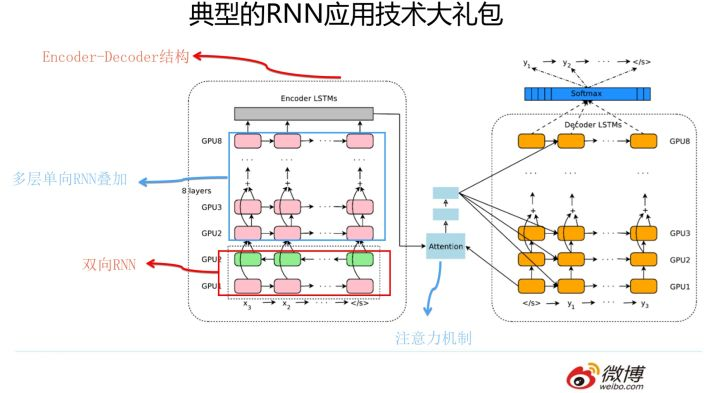
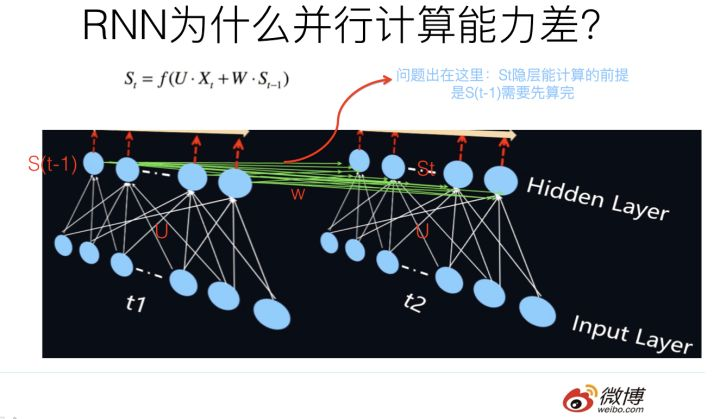
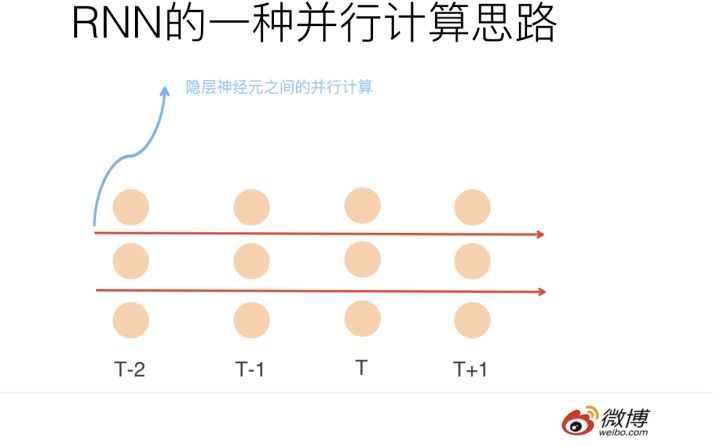
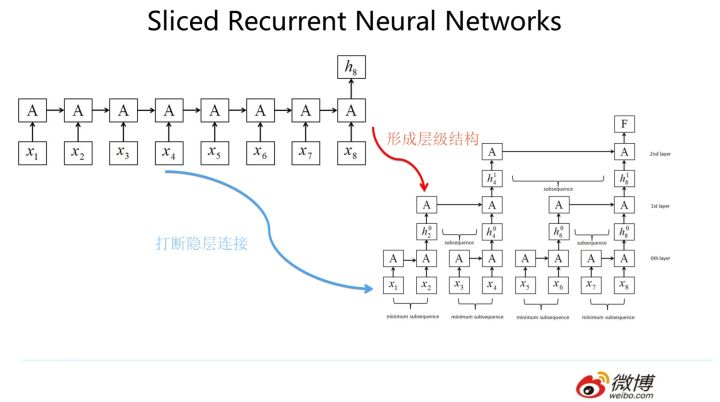
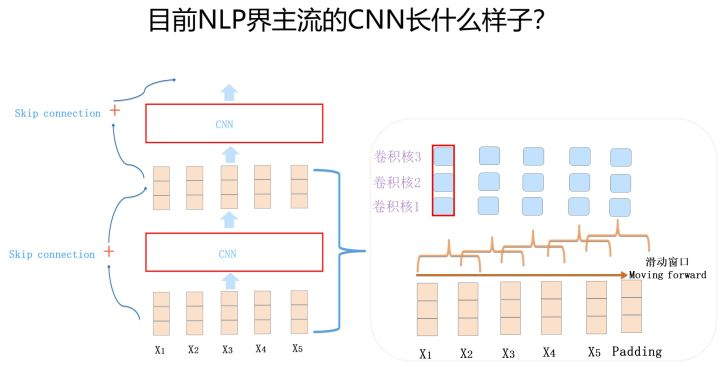
白衣骑士Transformer:盖世英雄站上舞台

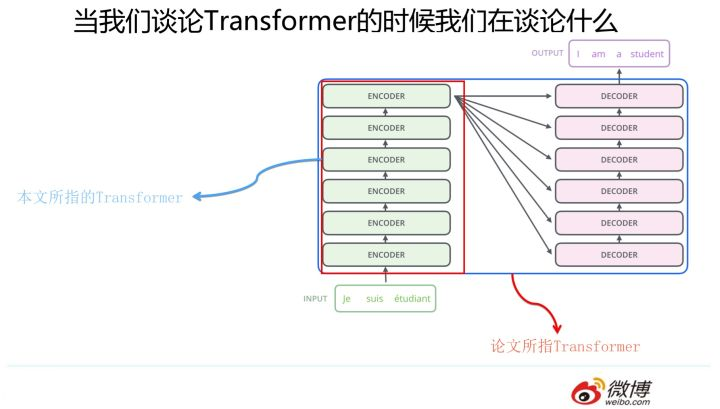
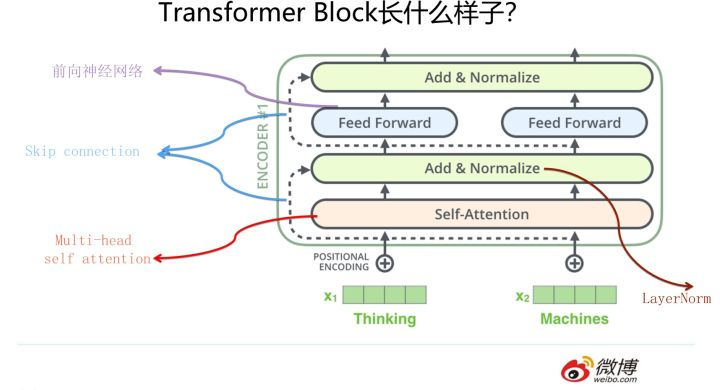
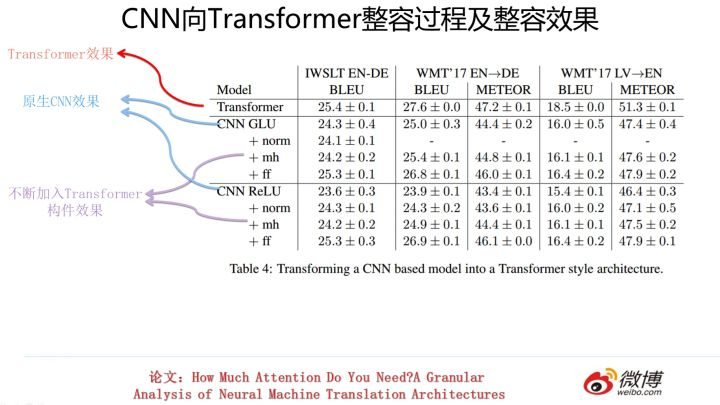
华山论剑:三大特征抽取器比较
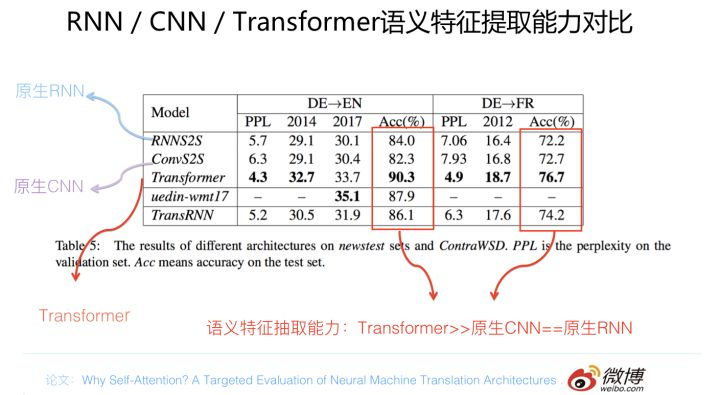

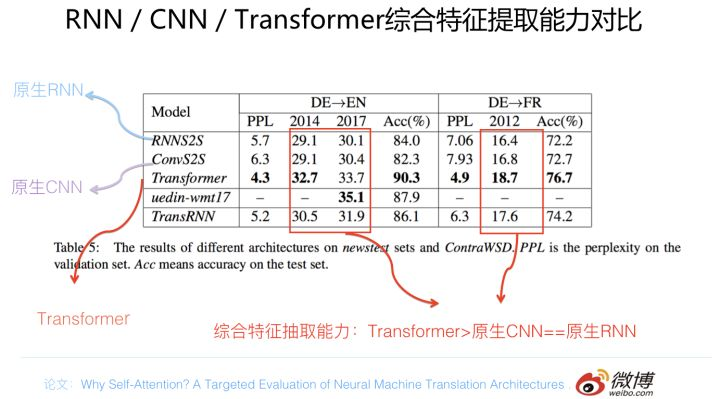

综合排名情况
以上介绍内容是从几个不同角度来对RNN/CNN/Transformer进行对比,综合这几个方面的实验数据,我自己得出的结论是这样的:单从任务综合效果方面来说,Transformer明显优于CNN,CNN略微优于RNN。速度方面Transformer和CNN明显占优,RNN在这方面劣势非常明显。这两者再综合起来,如果我给的排序结果是Transformer>CNN>RNN,估计没有什么问题吧?那位吃亏…..爱挑刺的同学,你说呢?
从速度和效果折衷的角度看,对于工业界实用化应用,我的感觉在特征抽取器选择方面配置Transformer base是个较好的选择。
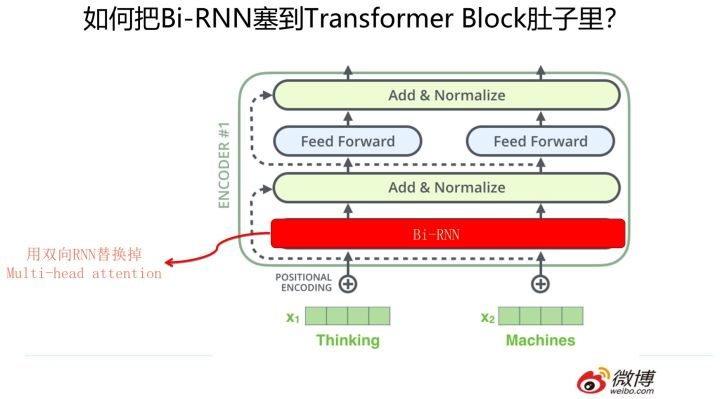
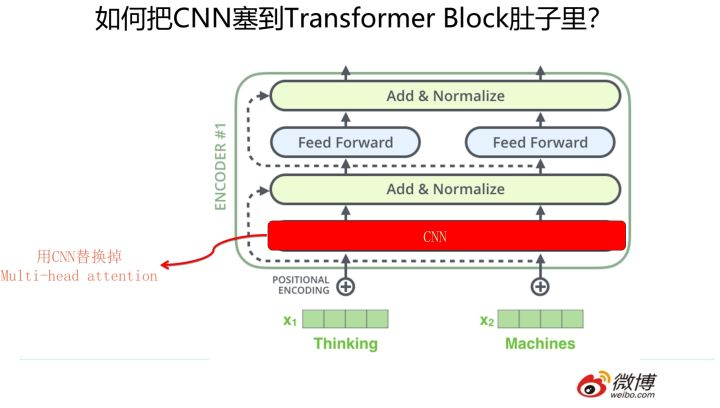
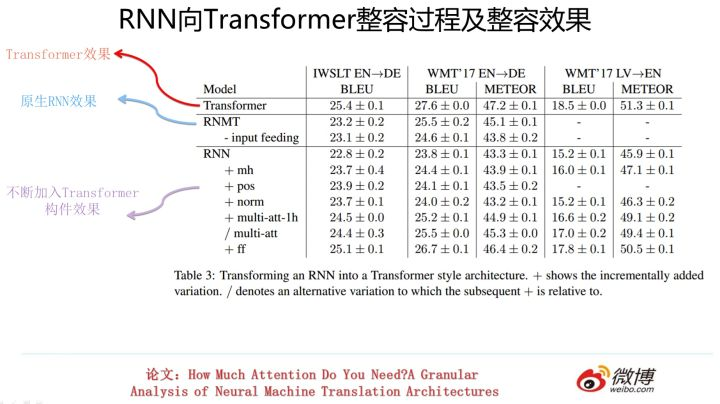
三者的合流:向Transformer靠拢
2 从Word Embedding 到bert模型(上下文预训练)-自然语言处理中的预训练技术发展史
A: NNLM
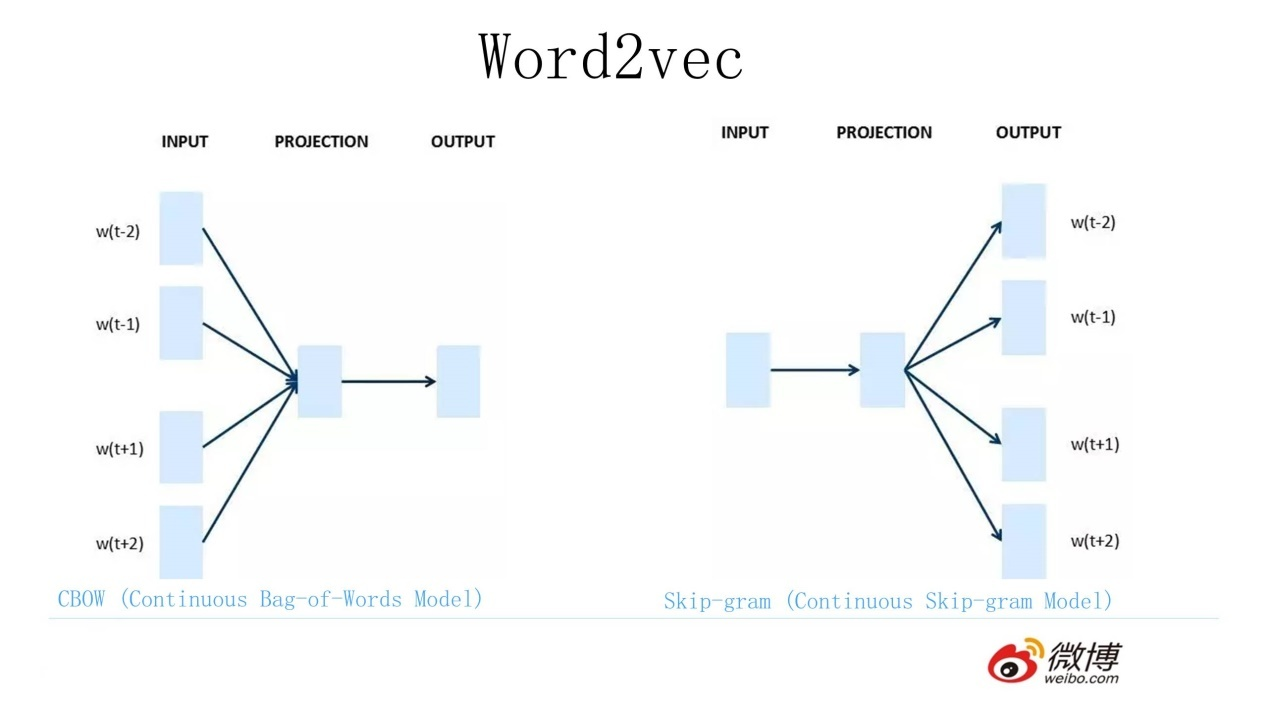
B: Word2Vec CBOW (完形填空)
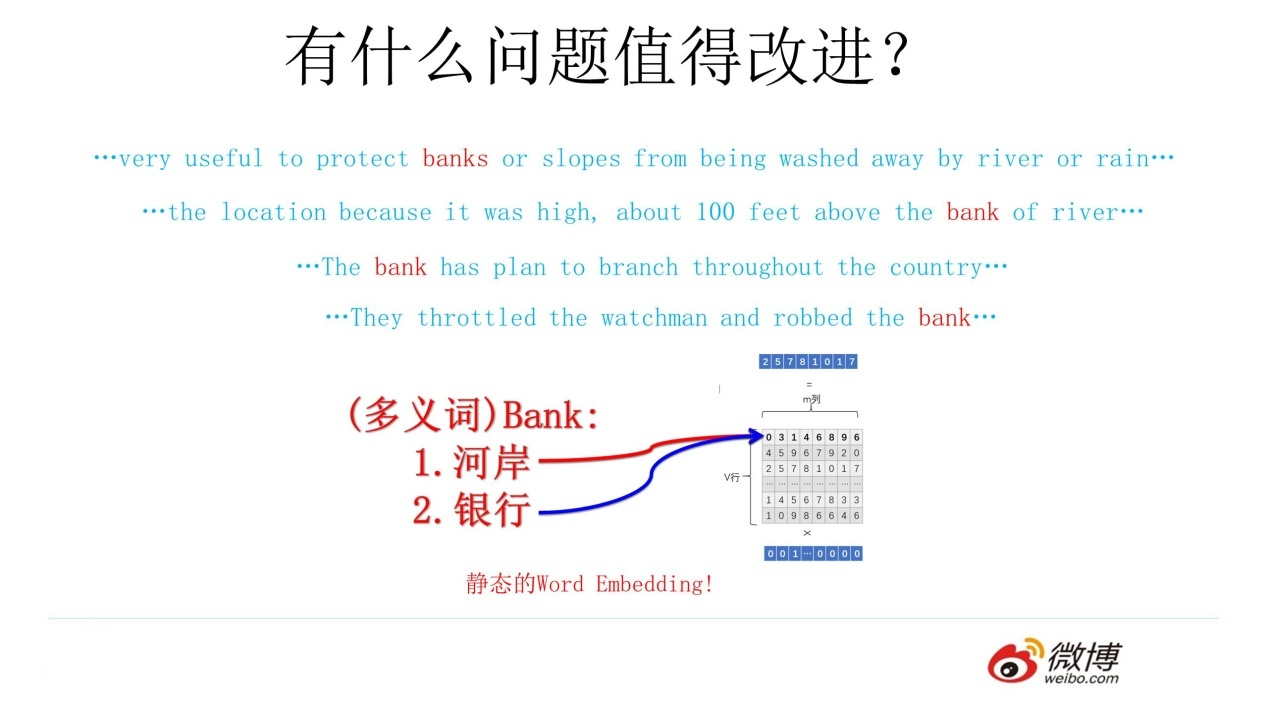
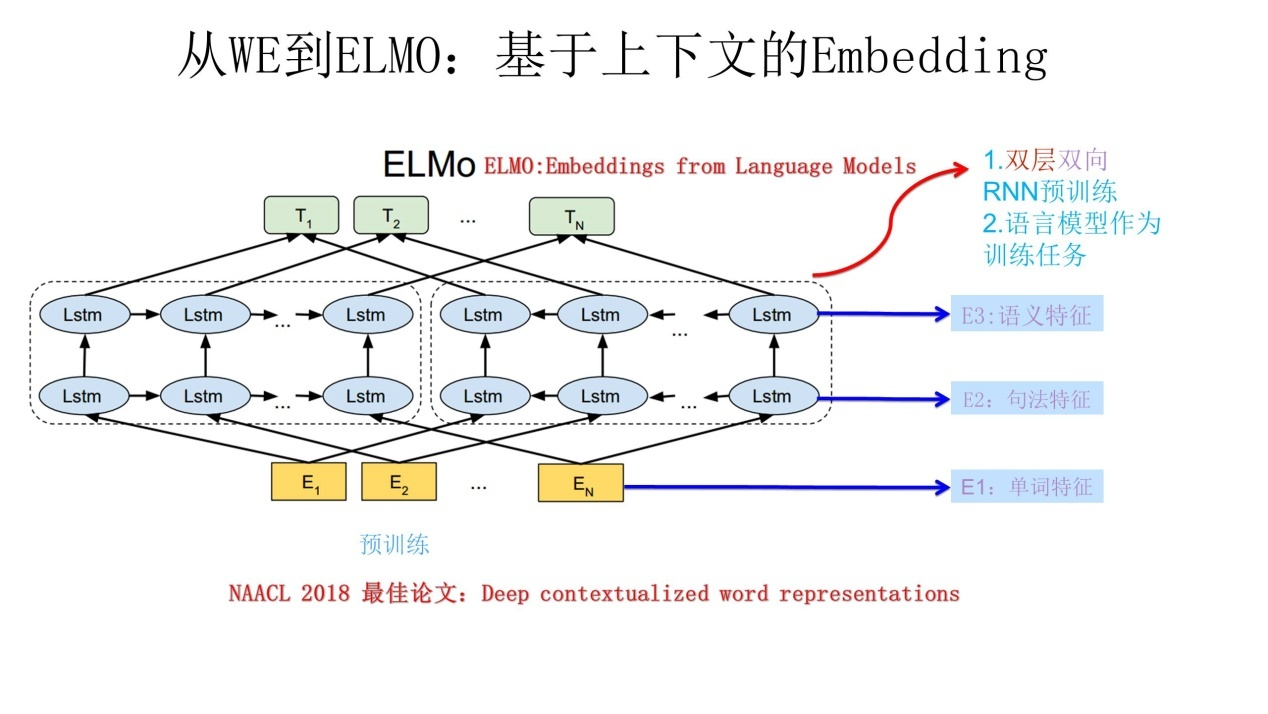
C : ELMO ELMO本身是个根据当前上下文对Word Embedding动态调整的思路。
从W2V 到ELMO:基于上下文的embedding
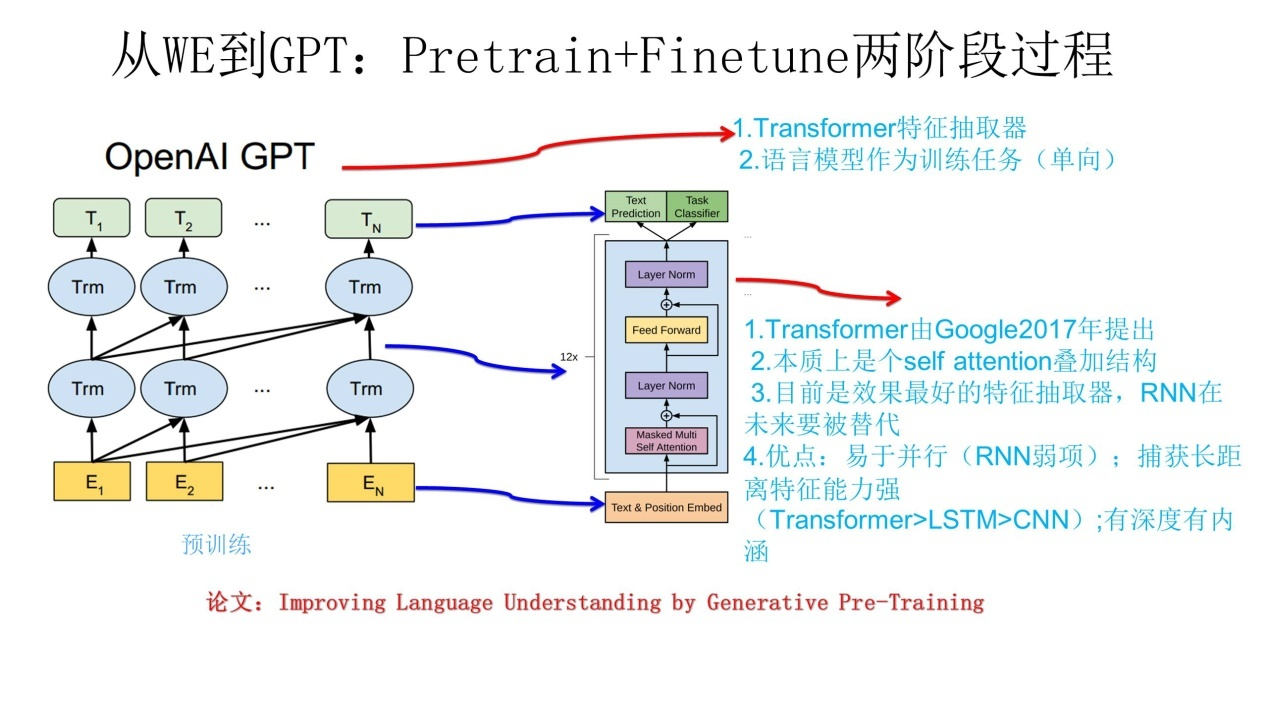
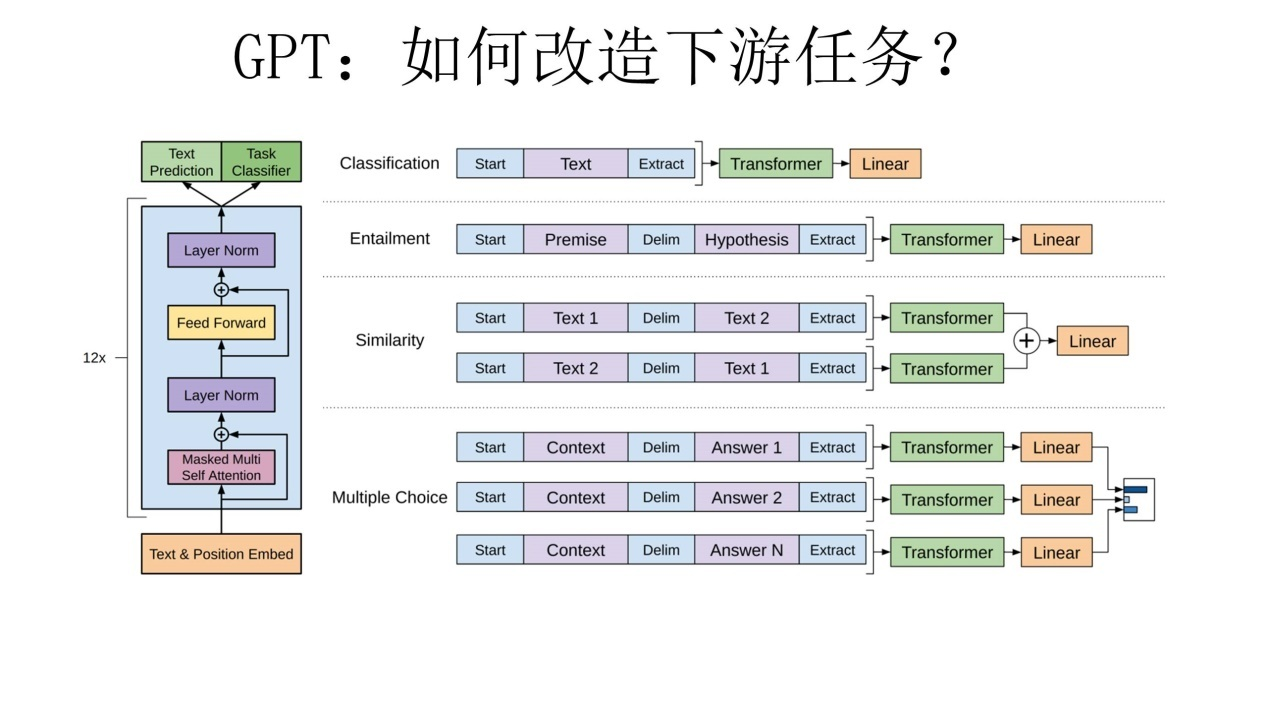
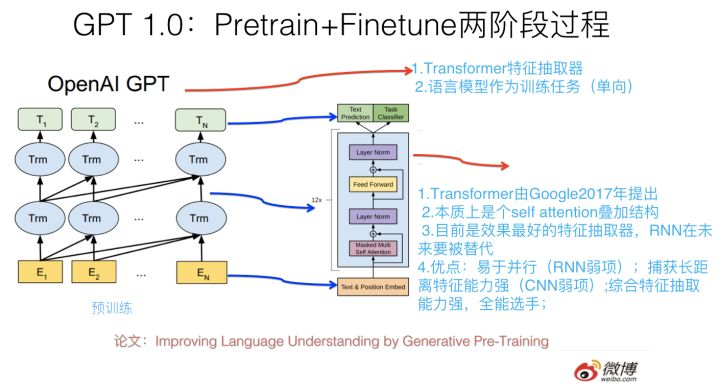
D: GPT 从W2V 到 GPT: Pretain + Finetune两阶段过程
1 Transformer 作为特征抽取器
2 语言模型作为预训练任务(单向)
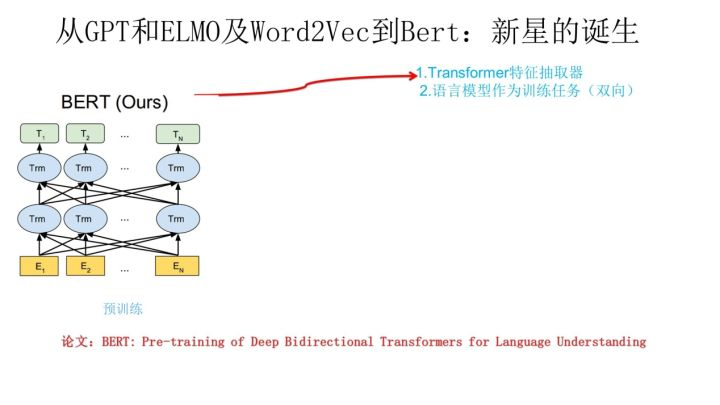
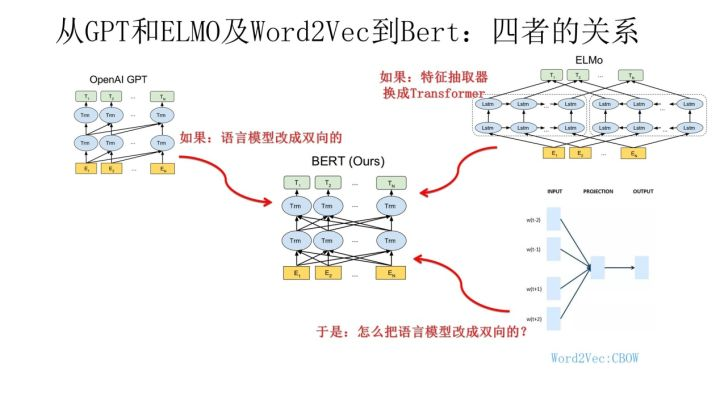
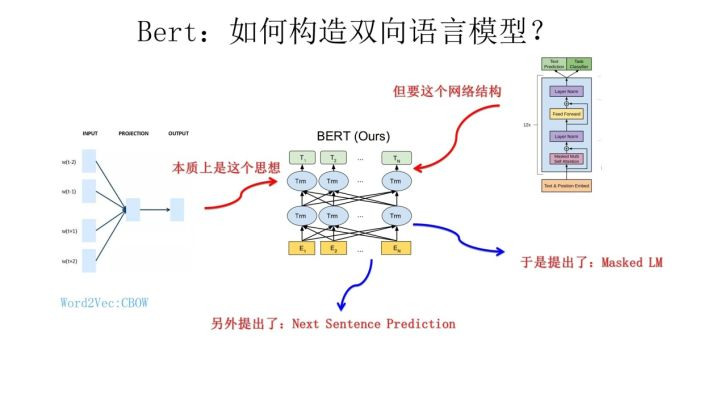
E: Bert 从GPT和ELMO及W2V 到bert, 新星的诞生
1 Transformer 作为特征抽取器
2 语言模型作为预训练任务(双向) (CBOW)
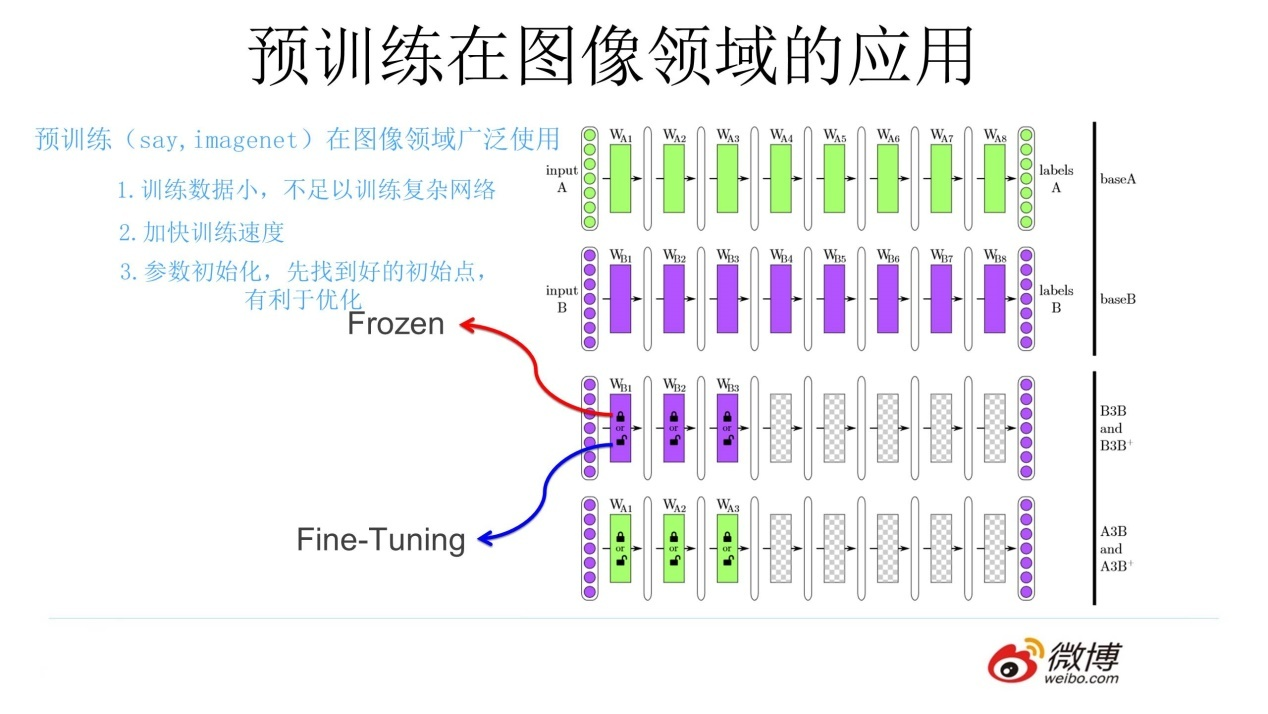
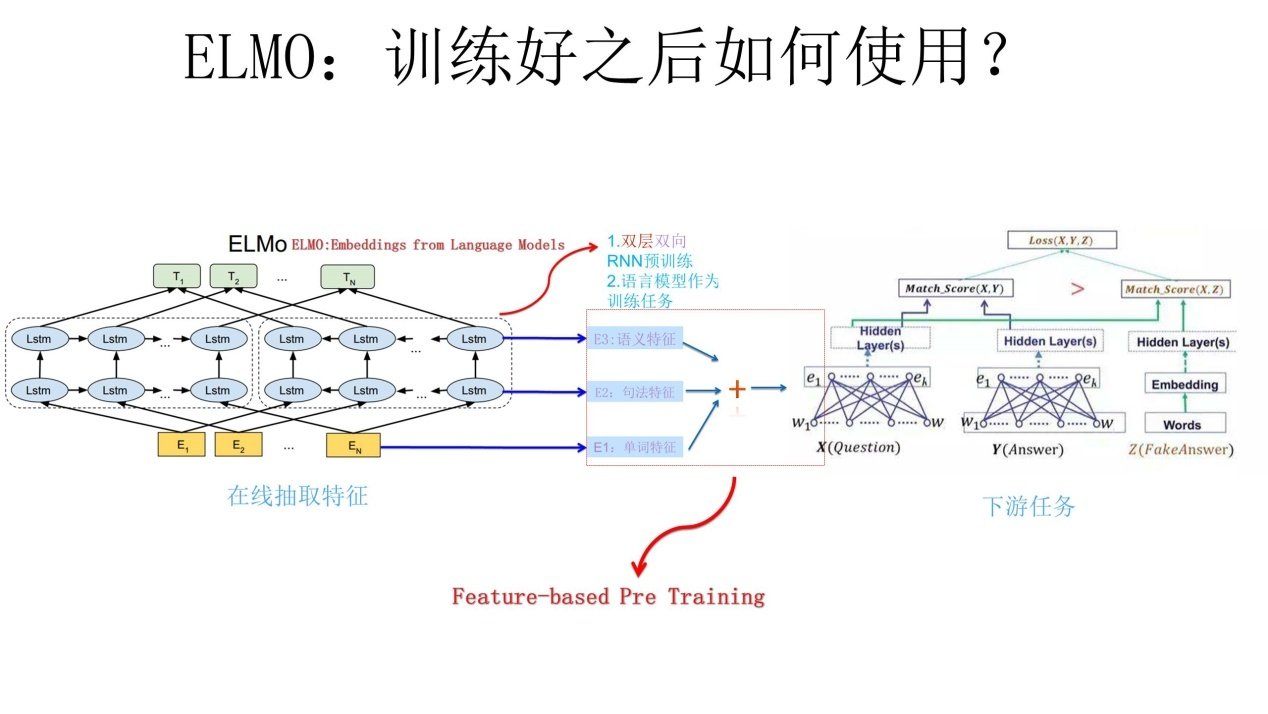
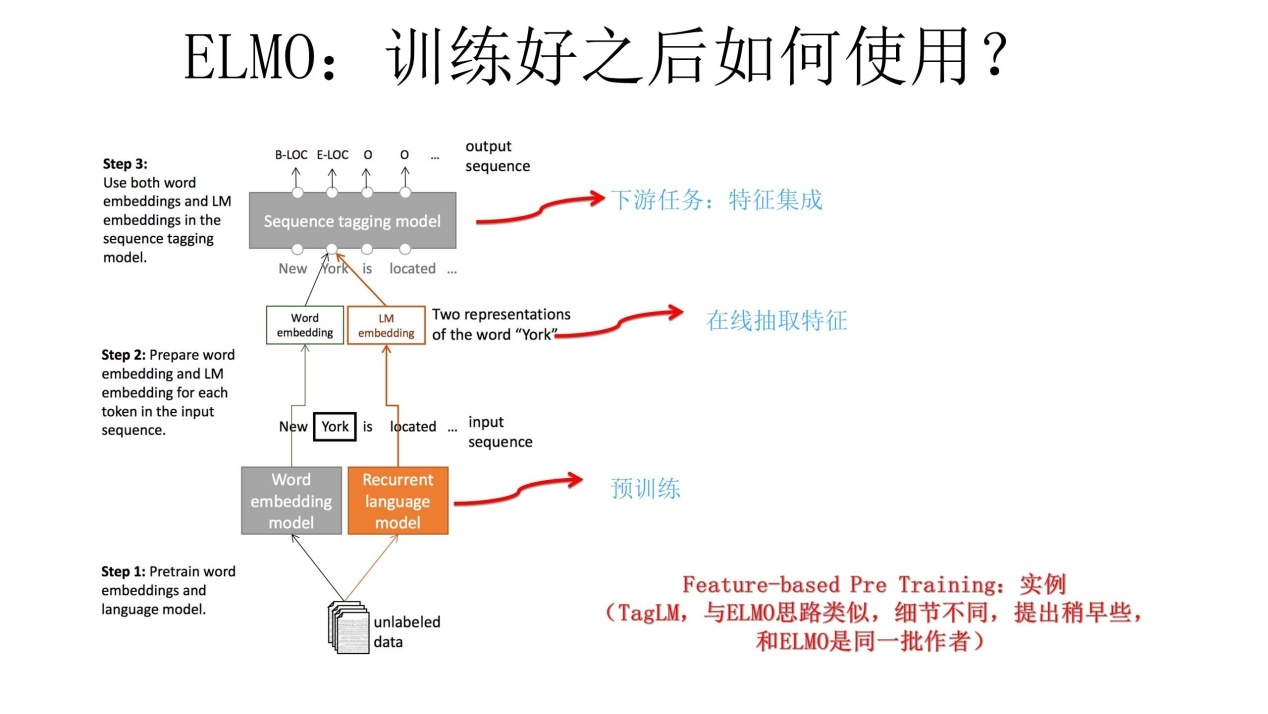
我们知道,ELMO/GPT/Bert这几个自然语言预训练模型给NLP带来了方向性的指引,一般在应用这些预训练模型的时候,采取两阶段策略:首先是利用通用语言模型任务,采用自监督学习方法,选择某个具体的特征抽取器来学习预训练模型;第二个阶段,则针对手头的具体监督学习任务,采取特征集成或者Fine-tuning的应用模式,表达清楚自己到底想要Bert干什么,然后就可以高效地解决手头的问题和任务了。


从WordEmbedding到 ELMO


从Word2Embeding到GPT



Bert的诞生:


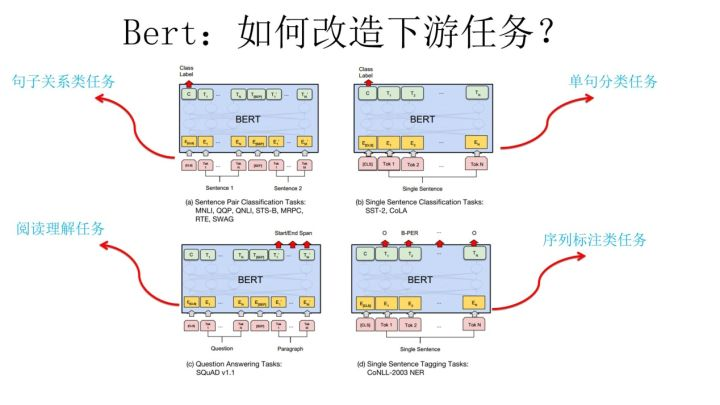





Bert的另外一种改进模式:进一步的多任务预训练
上面介绍的是GPT 2.0的改进模式,如上归纳,它采取的大的策略是:优化Bert的第一个预训练阶段,方向是扩充数据数量,提升数据质量,增强通用性,追求的是通过做大来做强。那么如果让你来优化Bert模型,除了这种无监督模式地把训练数据做大,还有其它模式吗?
当然有,你这么想这个问题:既然Bert的第一个阶段能够无监督模式地把训练数据做大,我们知道,机器学习里面还有有监督学习,NLP任务里也有不少有监督任务是有训练数据的,这些数据能不能用进来改善Bert第一阶段的那个学习各种知识的Transformer呢?肯定是可以的呀,所以很自然的一个想法是:把Bert第一阶段或者第二阶段改成多任务学习的训练过程,这样就可以把很多NLP任务的有监督训练数据里包含的知识引入到Transformer中了。
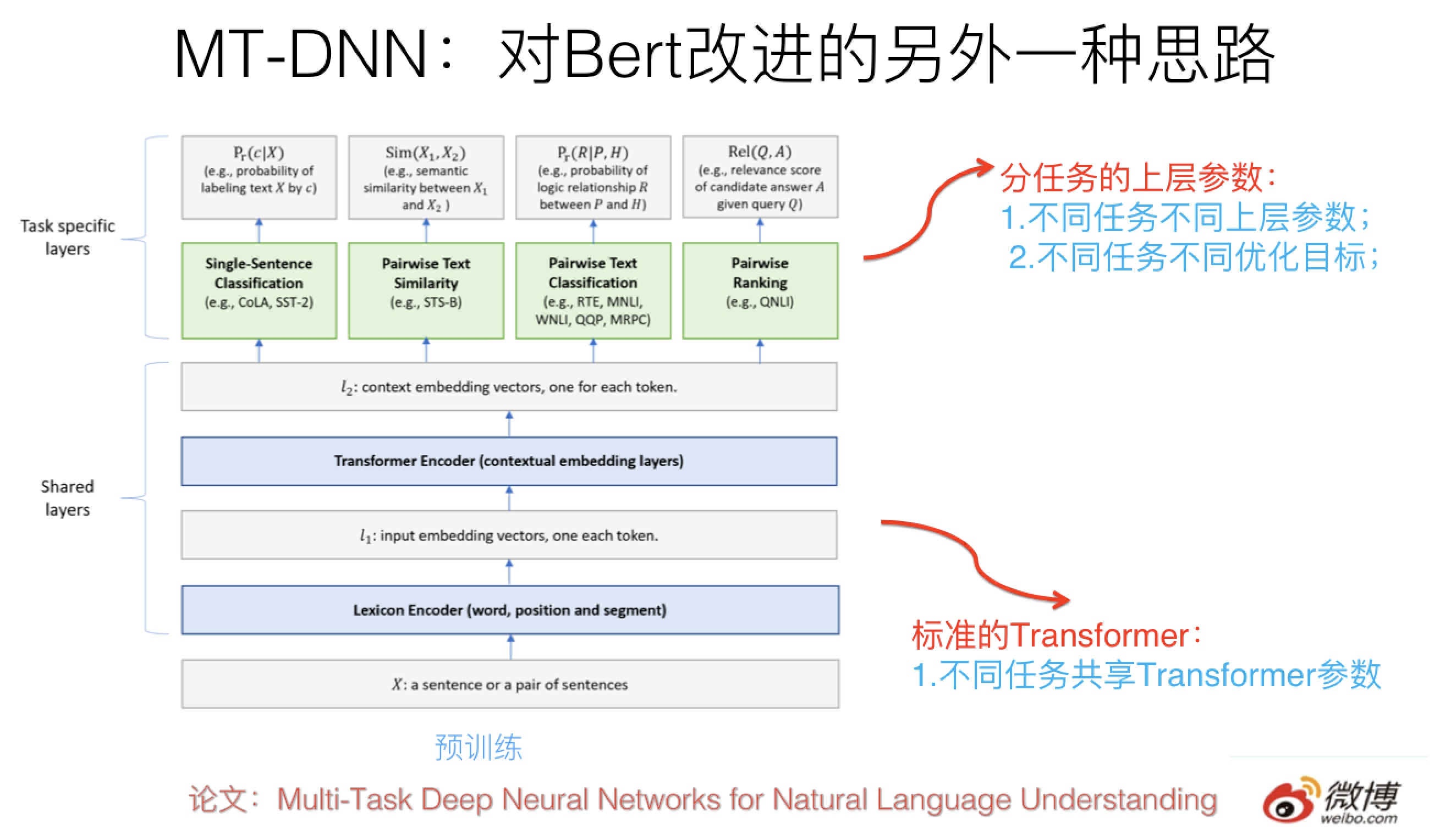
这种做法一个典型的模型是最近微软推出的MT-DNN,改进思路就如上所述,可以参考上图示意。核心思想如上,结构上底层就是标准的Bert Transformer,第一阶段采用Bert的预训练模型不动,在Finetuning阶段,在上层针对不同任务构造不同优化目标,所有不同上层任务共享底层Transformer参数,这样就强迫Transformer通过预训练做很多NLP任务,来学会新的知识,并编码到Transformer的参数中。
对Bert的多任务改造其实是个非常自然的Bert的拓展思路,因为本来原始版本的Bert在预训练的时候就是多任务过程,包括语言模型以及next-sentence预测两个任务。新的多任务的目标是进一步拓展任务数量,以此来进行模型优化。
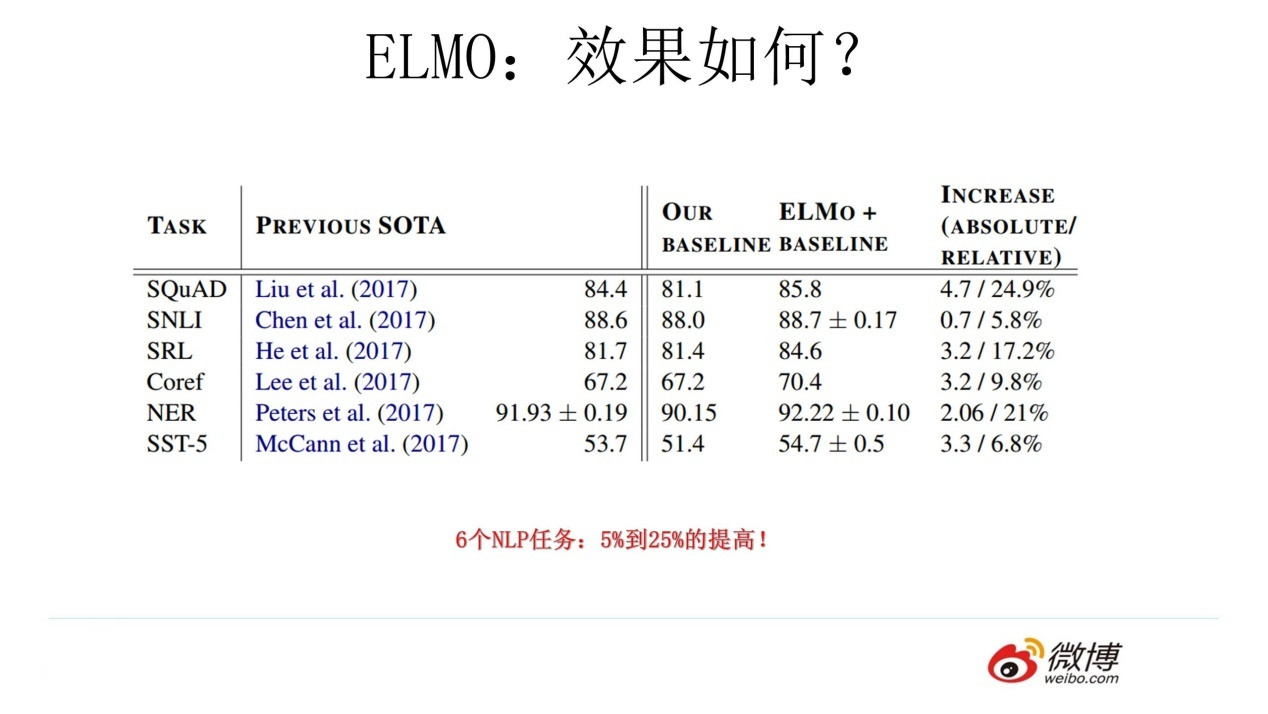
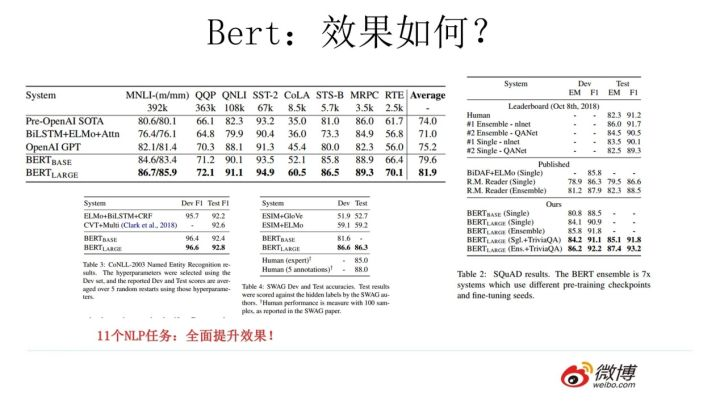
这种改进在效果上也有直接的效果提升,在11项NLP任务中9项超过了原始版本的Bert。
多任务理论上在第一阶段预训练和第二阶段Finetuning阶段做都可以,但是估计大多数会在第二阶段做,原因是第一阶段跟着那个大的语言模型数据一起,太消耗资源。
3 文本分类
1)fastText
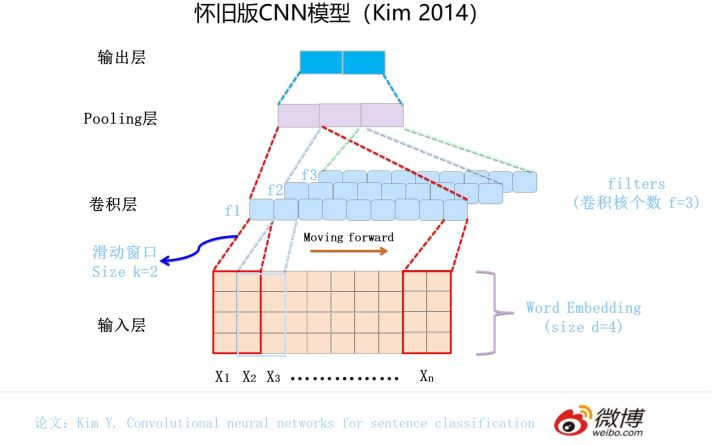
fastText 是上文提到的 word2vec 作者 Mikolov 转战 Facebook 后16年7月刚发表的一篇论文 Bag of Tricks for Efficient Text Classification。把 fastText 放在此处并非因为它是文本分类的主流做法,而是它极致简单,模型图见下:

原理是把句子中所有的词向量进行平均(某种意义上可以理解为只有一个avg pooling特殊CNN),然后直接接 softmax 层。其实文章也加入了一些 n-gram 特征的 trick 来捕获局部序列信息。文章倒没太多信息量,算是“水文”吧,带来的思考是文本分类问题是有一些“线性”问题的部分[from项亮],也就是说不必做过多的非线性转换、特征组合即可捕获很多分类信息,因此有些任务即便简单的模型便可以搞定了。
2)TextCNN
本篇文章的题图选用的就是14年这篇文章提出的TextCNN的结构(见下图)。fastText 中的网络结果是完全没有考虑词序信息的,而它用的 n-gram 特征 trick 恰恰说明了局部序列信息的重要意义。卷积神经网络(CNN Convolutional Neural Network)最初在图像领域取得了巨大成功,CNN原理就不讲了,核心点在于可以捕捉局部相关性,具体到文本分类任务中可以利用CNN来提取句子中类似 n-gram 的关键信息。
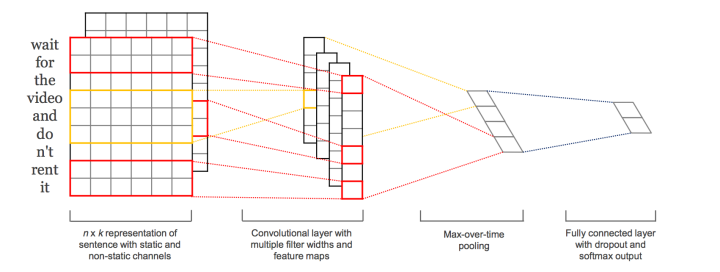
TextCNN的详细过程原理图见下:
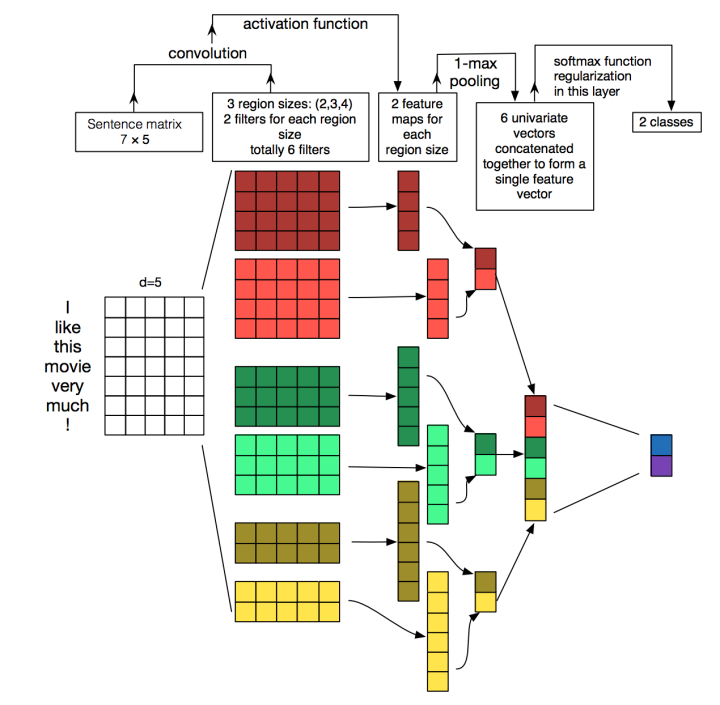
TextCNN详细过程:第一层是图中最左边的7乘5的句子矩阵,每行是词向量,维度=5,这个可以类比为图像中的原始像素点了。然后经过有 filter_size=(2,3,4) 的一维卷积层,每个filter_size 有两个输出 channel。第三层是一个1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示了,最后接一层全连接的 softmax 层,输出每个类别的概率。
特征:这里的特征就是词向量,有静态(static)和非静态(non-static)方式。static方式采用比如word2vec预训练的词向量,训练过程不更新词向量,实质上属于迁移学习了,特别是数据量比较小的情况下,采用静态的词向量往往效果不错。non-static则是在训练过程中更新词向量。推荐的方式是 non-static 中的 fine-tunning方式,它是以预训练(pre-train)的word2vec向量初始化词向量,训练过程中调整词向量,能加速收敛,当然如果有充足的训练数据和资源,直接随机初始化词向量效果也是可以的。
通道(Channels):图像中可以利用 (R, G, B) 作为不同channel,而文本的输入的channel通常是不同方式的embedding方式(比如 word2vec或Glove),实践中也有利用静态词向量和fine-tunning词向量作为不同channel的做法。
一维卷积(conv-1d):图像是二维数据,经过词向量表达的文本为一维数据,因此在TextCNN卷积用的是一维卷积。一维卷积带来的问题是需要设计通过不同 filter_size 的 filter 获取不同宽度的视野。
Pooling层:利用CNN解决文本分类问题的文章还是很多的,比如这篇 A Convolutional Neural Network for Modelling Sentences 最有意思的输入是在 pooling 改成 (dynamic) k-max pooling ,pooling阶段保留 k 个最大的信息,保留了全局的序列信息。比如在情感分析场景,举个例子:
“ 我觉得这个地方景色还不错,但是人也实在太多了 ”
虽然前半部分体现情感是正向的,全局文本表达的是偏负面的情感,利用 k-max pooling能够很好捕捉这类信息。
3)TextRNN
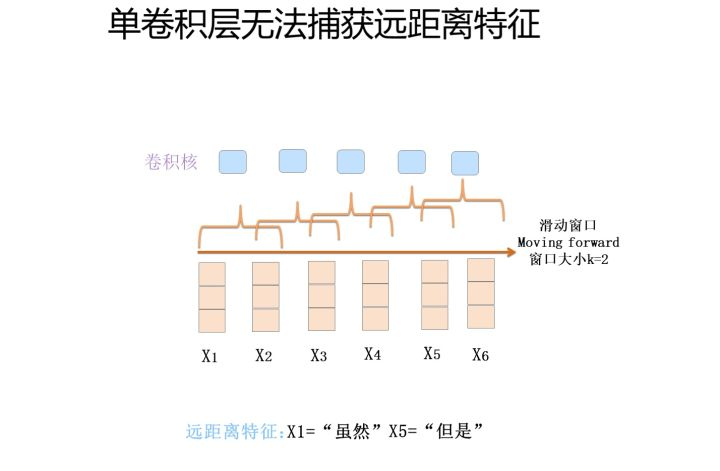
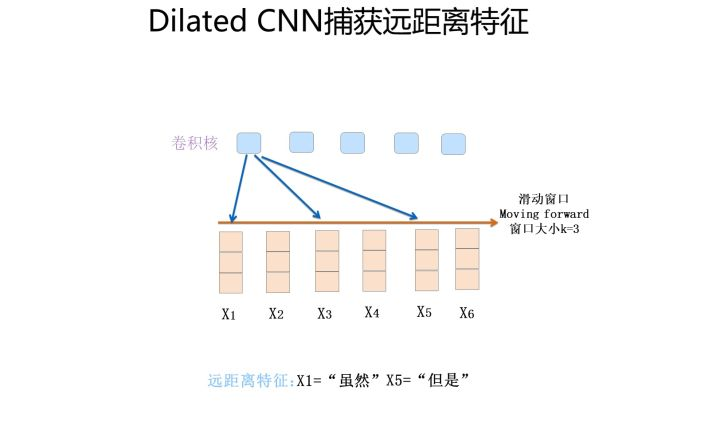
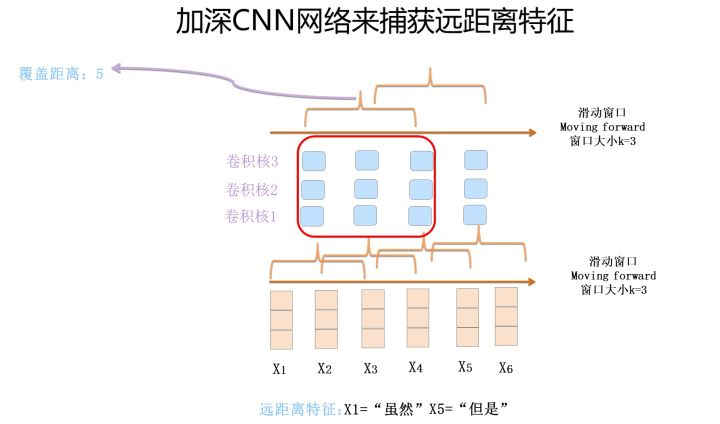
尽管TextCNN能够在很多任务里面能有不错的表现,但CNN有个最大问题是固定 filter_size 的视野,一方面无法建模更长的序列信息,另一方面 filter_size 的超参调节也很繁琐。CNN本质是做文本的特征表达工作,而自然语言处理中更常用的是递归神经网络(RNN, Recurrent Neural Network),能够更好的表达上下文信息。具体在文本分类任务中,Bi-directional RNN(实际使用的是双向LSTM)从某种意义上可以理解为可以捕获变长且双向的的 "n-gram" 信息。
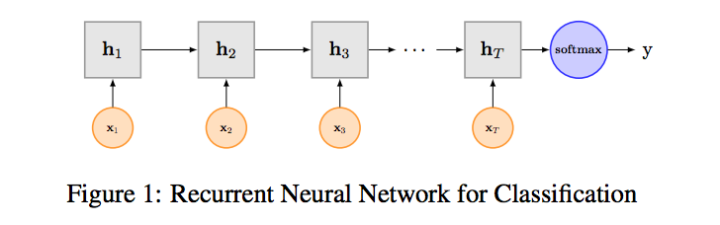
RNN算是在自然语言处理领域非常一个标配网络了,在序列标注/命名体识别/seq2seq模型等很多场景都有应用,Recurrent Neural Network for Text Classification with Multi-Task Learning文中介绍了RNN用于分类问题的设计,下图LSTM用于网络结构原理示意图,示例中的是利用最后一个词的结果直接接全连接层softmax输出了。
4)TextRNN + Attention
CNN和RNN用在文本分类任务中尽管效果显著,但都有一个不足的地方就是不够直观,可解释性不好,特别是在分析badcase时候感受尤其深刻。而注意力(Attention)机制是自然语言处理领域一个常用的建模长时间记忆机制,能够很直观的给出每个词对结果的贡献,基本成了Seq2Seq模型的标配了。实际上文本分类从某种意义上也可以理解为一种特殊的Seq2Seq,所以考虑把Attention机制引入近来,研究了下学术界果然有类似做法。
Attention机制介绍:
详细介绍Attention恐怕需要一小篇文章的篇幅,感兴趣的可参考14年这篇paper NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE。
以机器翻译为例简单介绍下,下图中 是源语言的一个词,
是目标语言的一个词,机器翻译的任务就是给定源序列得到目标序列。翻译
的过程产生取决于上一个词
和源语言的词的表示
(
的 bi-RNN 模型的表示),而每个词所占的权重是不一样的。比如源语言是中文 “我 / 是 / 中国人” 目标语言 “i / am / Chinese”,翻译出“Chinese”时候显然取决于“中国人”,而与“我 / 是”基本无关。下图公式,
则是翻译英文第
个词时,中文第
个词的贡献,也就是注意力。显然在翻译“Chinese”时,“中国人”的注意力值非常大。
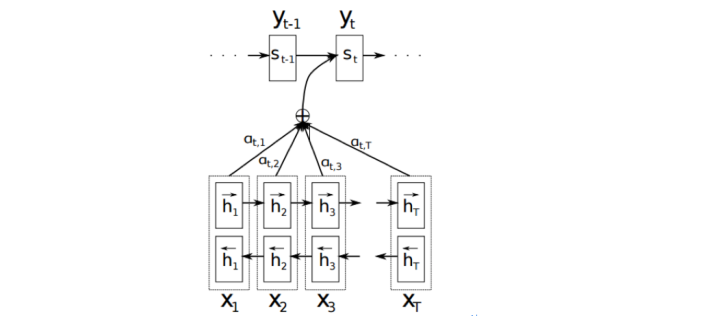
Attention的核心point是在翻译每个目标词(或 预测商品标题文本所属类别)所用的上下文是不同的,这样的考虑显然是更合理的。
TextRNN + Attention 模型:
我们参考了这篇文章 Hierarchical Attention Networks for Document Classification,下图是模型的网络结构图,它一方面用层次化的结构保留了文档的结构,另一方面在word-level和sentence-level。淘宝标题场景只需要 word-level 这一层的 Attention 即可。
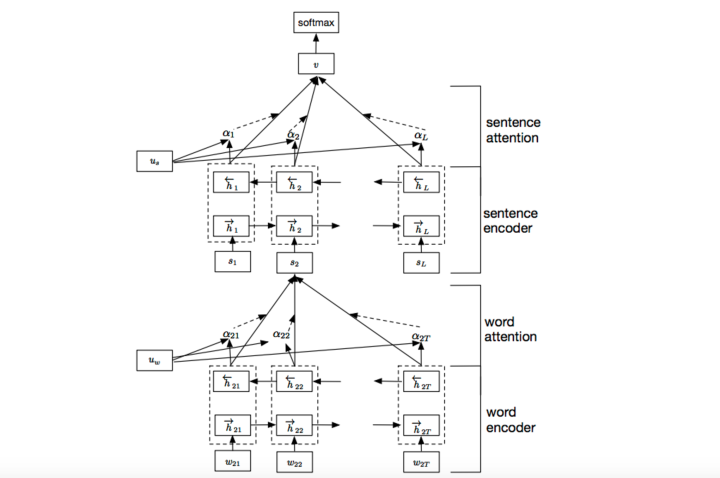
加入Attention之后最大的好处自然是能够直观的解释各个句子和词对分类类别的重要性。
5)TextRCNN(TextRNN + CNN)
我们参考的是中科院15年发表在AAAI上的这篇文章 Recurrent Convolutional Neural Networks for Text Classification 的结构:
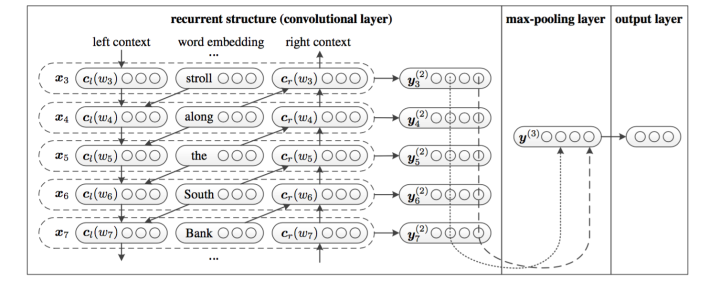
利用前向和后向RNN得到每个词的前向和后向上下文的表示:
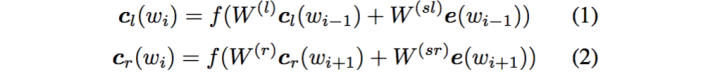
这样词的表示就变成词向量和前向后向上下文向量concat起来的形式了,即:
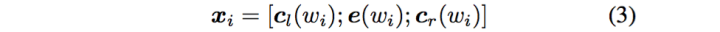
最后再接跟TextCNN相同卷积层,pooling层即可,唯一不同的是卷积层 filter_size = 1就可以了,不再需要更大 filter_size 获得更大视野,这里词的表示也可以只用双向RNN输出。
4 机器翻译(生成式任务)
Seq2Seq
Seq2Seq with Attenation
Transformer
4 文本相似度/文本匹配
1 特征工程
2 深度学习模型
深度模型有两种思路,一种是基于表示,一种是基于交互。不过基于交互的模型大多也是先要拿到文本表示,从文本表示构建交互,从交互到特征抽取的思路
4 Seq2Seq
参考文献: 1 https://zhuanlan.zhihu.com/p/54743941 自然语言处理三大特征抽取器
2 从Word Embedding 到 Bert模型,自然语言处理中的欲训练发展史
3 Bert大火却不懂Transformer
4 https://zhuanlan.zhihu.com/p/56865533
5 https://zhuanlan.zhihu.com/p/69290203
NLP基础的更多相关文章
- 第1章 NLP基础
大纲 NLP基础概念 NLP的发展与应用 NLP常用术语以及扩展介绍 1.1 什么是NLP 基本分类 自然语言生成(Natural Language Generation,NLG) 指从结构化数据中以 ...
- NLP基础——词集模型(SOW)和词袋模型(BOW)
(1)词集模型(Set Of Words): 单词构成的集合,集合自然每个元素都只有一个,也即词集中的每个单词都只有一个. (2)词袋模型(Bag Of Words): 如果一个单词在文档中出现不止一 ...
- nlp基础(一)基本应用
1.问答系统,它主要是针对那些有明确答案的用户问题,而且通常面向特定的领域,比如金融,医疗,这一类的机器人.它的技术实现方案分为基于检索和基于知识库两大类. 2.第二个任务型对话系统,大家看论文的时候 ...
- NLP基础 成分句法分析和依存句法分析
正则匹配: .除换行符所有的 ?表示0次或者1次 *表示0次或者n次 a(bc)+表示bc至少出现1次 ^x.*g$表示字符串以x开头,g结束 |或者 http://regexr.com/ 依存句法分 ...
- 1.1 NLP基础技能,字符串的处理
#!/usr/bin/env python # coding: utf-8 # # 字符串操作 # ### 去空格和特殊字符 # In[8]: s = " hello world! &quo ...
- 使用httpclient访问NLP应用接口例子
参考网址: http://yuzhinlp.com/docs.html 接入前须知 接入条件 1.进入网站首页,点击注册成为语知科技用户 2.注册完成后,系统将提供语知科技用户唯一标识APIKey,并 ...
- nlp底层技术列举
其实目前除了之前博客写到的一些关于自然语言处理用到的知识点之外,很多其他nlp技术只是会用但是不了解原理,先整体分个类,之后再仔细分析吧. 上图是https://www.sohu.com/a/1386 ...
- 这篇文章写的真好-NLP将迎来黄金十年-书摘
机器之心上面微软亚研的这篇文章真好: https://baijiahao.baidu.com/s?id=1618179669909135692&wfr=spider&for=pc 其中 ...
- 转:使用RNN解决NLP中序列标注问题的通用优化思路
http://blog.csdn.net/malefactor/article/details/50725480 /* 版权声明:可以任意转载,转载时请标明文章原始出处和作者信息 .*/ author ...
随机推荐
- setTimeout,promise,promise.then, async,await执行顺序问题
今天下午看了好多关于这些执行顺序的问题 经过自己的实践 终于理解了 记录一下就拿网上出现频繁的代码来说: async function async1() { console.log('async1 ...
- 定时备份etc目录
#!/bin/bash # #******************************************************************** #encoding -*-utf ...
- golang打包和部署到centos7
一.环境说明:VS code 二.编译: set GOOS=linux set GOARCH=amd64 go build -o "packageName" 三.发布 上传到服 ...
- 【Amaple教程】4. 组件
在Amaple单页应用中,一个页面其实存在两种模块化单位,分别是 模块 (am.Module类),它是以web单页应用跳转更新为最小单位所拆分的独立块: 组件 (am.Component类),它的定位 ...
- 洛谷P1233 木棍加工【单调栈】
题目:https://www.luogu.org/problemnew/show/P1233 题意: 有n根木棍,每根木棍有长度和宽度. 现在要求按某种顺序加工木棍,如果前一根木棍的长度和宽度都大于现 ...
- Python模块之目录
1.加密算法有关 hmac模块 hashlib模块 2.进程有关 multiprocessing模块 3.线程有关 threading模块 4.协程有关 asyncio模块 5.系统命令调用 sub ...
- Gym 100548F Color 给花染色 容斥+组合数学+逆元 铜牌题
Problem F. ColorDescriptionRecently, Mr. Big recieved n flowers from his fans. He wants to recolor th ...
- ZOJ 4124 拓扑排序+思维dfs
ZOJ - 4124Median 题目大意:有n个元素,给出m对a>b的关系,问哪个元素可能是第(n+1)/2个元素,可能的元素位置相应输出1,反之输出0 省赛都过去两周了,现在才补这题,这题感 ...
- 五一培训 清北学堂 DAY4
今天上午是钟皓曦老师的讲授,下午是吴耀轩老师出的题给我们NOIP模拟考了一下下(悲催暴零) 今天的内容——数论 话说我们可能真的是交了冤枉钱了,和上次清明培训的时候的课件及内容一样(哭. 整除性 质数 ...
- trie树(字典树)的部分简单实现
什么是trie树(字典树)? trie树是一种用于快速检索的多叉树结构.和二叉查找树不同,在trie树中,每个结点上并非存储一个元素. trie树把要查找的关键词看作一个字符序列.并根据构成关键词字符 ...