用sqoop将mysql的数据导入到hive表中
1:先将mysql一张表的数据用sqoop导入到hdfs中
准备一张表

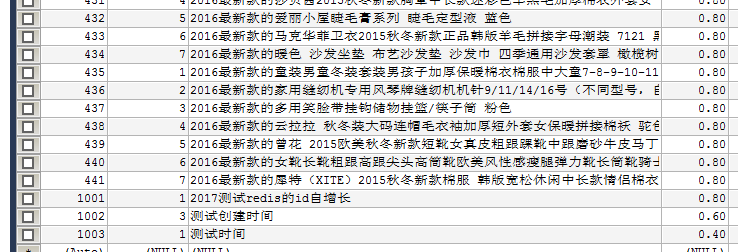
需求 将 bbs_product 表中的前100条数据导 导出来 只要id brand_id和 name 这3个字段
数据存在 hdfs 目录 /user/xuyou/sqoop/imp_bbs_product_sannpy_ 下
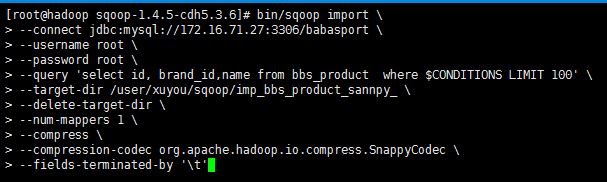
bin/sqoop import \
--connect jdbc:mysql://172.16.71.27:3306/babasport \
--username root \
--password root \
--query 'select id, brand_id,name from bbs_product where $CONDITIONS LIMIT 100' \
--target-dir /user/xuyou/sqoop/imp_bbs_product_sannpy_ \
--delete-target-dir \
--num-mappers 1 \
--compress \
--compression-codec org.apache.hadoop.io.compress.SnappyCodec \
--fields-terminated-by '\t'
ps: 如果导出的数据库是mysql 则可以添加一个 属性 --direct
bin/sqoop import \
--connect jdbc:mysql://172.16.71.27:3306/babasport \
--username root \
--password root \
--query 'select id, brand_id,name from bbs_product where $CONDITIONS LIMIT 100' \
--target-dir /user/xuyou/sqoop/imp_bbs_product_sannpy_ \
--delete-target-dir \
--num-mappers 1 \
--compress \
--compression-codec org.apache.hadoop.io.compress.SnappyCodec \
--direct \
--fields-terminated-by '\t'
加了 direct 属性在导出mysql数据库表中的数据会快一点 执行的是mysq自带的导出功能
第一次执行所需要的时间

第二次执行所需要的时间 (加了direct属性)

执行成功

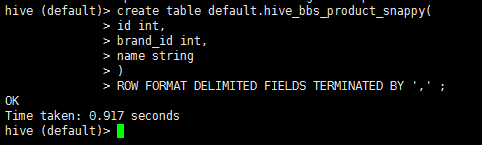
2:启动hive 在hive中创建一张表
drop table if exists default.hive_bbs_product_snappy ;
create table default.hive_bbs_product_snappy(
id int,
brand_id int,
name string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ;
3:将hdfs中的数据导入到hive中
load data inpath '/user/xuyou/sqoop/imp_bbs_product_sannpy_' into table default.hive_bbs_product_snappy ;

4:查询 hive_bbs_product_snappy 表
select * from hive_bbs_product_snappy;

此时hdfs 中原数据没有了

然后进入hive的hdfs存储位置发现

注意 :sqoop 提供了 直接将mysql数据 导入 hive的 功能 底层 步骤就是以上步骤
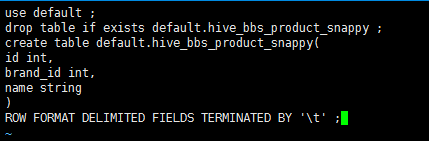
创建一个文件 touch test.sql 编辑文件 vi test.sql
use default;
drop table if exists default.hive_bbs_product_snappy ;
create table default.hive_bbs_product_snappy(
id int,
brand_id int,
name string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ;
在 启动hive的时候 执行 sql脚本
bin/hive -f /opt/cdh-5.3.6/sqoop-1.4.5-cdh5.3.6/test.sql


执行sqoop直接导入hive的功能
bin/sqoop import \
--connect jdbc:mysql://172.16.71.27:3306/babasport \
--username root \
--password root \
--table bbs_product \
--fields-terminated-by '\t' \
--delete-target-dir \
--num-mappers 1 \
--hive-import \
--hive-database default \
--hive-table hive_bbs_product_snappy
看日志输出可以看出 在执行map任务之后 又执行了load data

查询 hive 数据

用sqoop将mysql的数据导入到hive表中的更多相关文章
- 用sqoop将mysql的数据导入到hive表
一.先将mysql一张表的数据用sqoop导入到hdfs 1.1.先在mysql中准备一张测试用的表 mysql> desc user_info; +-----------+---------- ...
- 11.把文本文件的数据导入到Hive表中
先在hive里面创建一个表 create table mydb2.t3(id int,name string,age int) row format delimited fields terminat ...
- 使用 sqoop 将mysql数据导入到hive表(import)
Sqoop将mysql数据导入到hive表中 先在mysql创建表 CREATE TABLE `sqoop_test` ( `id` ) DEFAULT NULL, `name` varchar() ...
- 使用spark将内存中的数据写入到hive表中
使用spark将内存中的数据写入到hive表中 hive-site.xml <?xml version="1.0" encoding="UTF-8" st ...
- MYSQL(将数据加载到表中)
1. 创建和选择数据库 mysql> CREATE DATABASE menagerie; mysql> USE menagerie Database changed 2. 创建表 mys ...
- 把HDFS上的数据导入到Hive中
1. 首先下载测试数据,数据也可以创建 http://files.grouplens.org/datasets/movielens/ml-latest-small.zip 2. 数据类型与字段名称 m ...
- 如何将hive表中的数据导出
近期经常将现场的数据带回公司测试,所以写下该文章,梳理一下思路. 1.首先要查询相应的hive表,比如我要将c_cons这张表导出,我先查出hive中是否有这张表. 查出数据,证明该表在hive中存在 ...
- Talend 将Oracle中数据导入到hive中,根据系统时间设置hive分区字段
首先,概览下任务图: 流程是,先用tHDFSDelete将hdfs上的文件删除掉,然后将oracle中的机构表中的数据导入到HDFS中:建立hive连接->hive建表->tJava获取系 ...
- 将DataFrame数据如何写入到Hive表中
1.将DataFrame数据如何写入到Hive表中?2.通过那个API实现创建spark临时表?3.如何将DataFrame数据写入hive指定数据表的分区中? 从spark1.2 到spark1.3 ...
随机推荐
- css选择器和新增UI样式总结
经过两天的学习,初步对css3选择器和新增UI样式有了进一步的理解.
- 【acm】杀人游戏(hdu2211)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2211 杀人游戏 Time Limit: 3000/1000 MS (Java/Others) M ...
- MySQL---InnoDB引擎隔离级别详解
原帖:http://www.cnblogs.com/snsdzjlz320/p/5761387.html SQL标准定义了4种隔离级别,包括了一些具体规则,用来限定事务内外的哪些改变是可见的,哪些是不 ...
- [OS] 系统调用
- SpringMVC Ajax两种传参方式
1.采用@RequestParam或Request对象获取参数的方法 注:contentType必须指定为:application/x-www-form-urlencoded @ResponseBod ...
- 【Quartz.Net】.net 下使用Quartz.Net
Quartz.net是作业调度框架 1. 项目中添加quartz.net的引用(这里使用nuget管理) 新建一个类TimingJob,该类主要用于实现任务逻辑 using Quartz; usi ...
- 矩阵快速幂模板(pascal)
洛谷P3390 题目背景 矩阵快速幂 题目描述 给定n*n的矩阵A,求A^k 输入输出格式 输入格式: 第一行,n,k 第2至n+1行,每行n个数,第i+1行第j个数表示矩阵第i行第j列的元素 输出格 ...
- P4622 [COCI2012-2013#6] JEDAN
题目背景 COCI 题目描述 有N个数排成一行(数值代表高度),最初所有的数都为零,你可以选择连续的一段等高的数,将它们都增加1(除了开头和结尾那个数)如下图表示了两次操作: 现在有一些数字看不清了, ...
- 【BZOJ4197】【NOI2015】寿司晚宴(动态规划)
[BZOJ4197][NOI2015]寿司晚宴(动态规划) 题面 BZOJ 从\([2,n]\)中选择两个集合(可以为空集),使得两个集合中各选一个数出来,都互质. 求方案数. 题解 对于\(500\ ...
- BZOJ4152:[AMPPZ2014]The Captain——题解
https://www.lydsy.com/JudgeOnline/problem.php?id=4152 给定平面上的n个点,定义(x1,y1)到(x2,y2)的费用为min(|x1-x2|,|y1 ...