Hadoop3.1.1源码Client详解 : 写入准备-RPC调用与流的建立
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览
关于RPC(Remote Procedure Call),如果没有概念,可以参考一下RMI(Remote Method Invocation)。
简言之,是一种对网络传输细节进行封装,并且对用户暴露被代理对象的一种思想。
我们知道NameNode和客户端一般是不在同一部机器上的,客户端(Client)通过RPC调用NameNode的方法,获得NameNode上
文件目录结构,块映射信息,文件权限,文件所在位置(Locations,也就是DataNode的信息)等等信息资源。
下文将讲解当我们调用FileSystem.create,FileSystem.append,FileSystem.open等方法时,为数据传输做的准备。
这些方法是最主要的方法,其他方法的准备阶段和他们的准备阶段差不多。
.FileSystem.create搭建的准备环境:
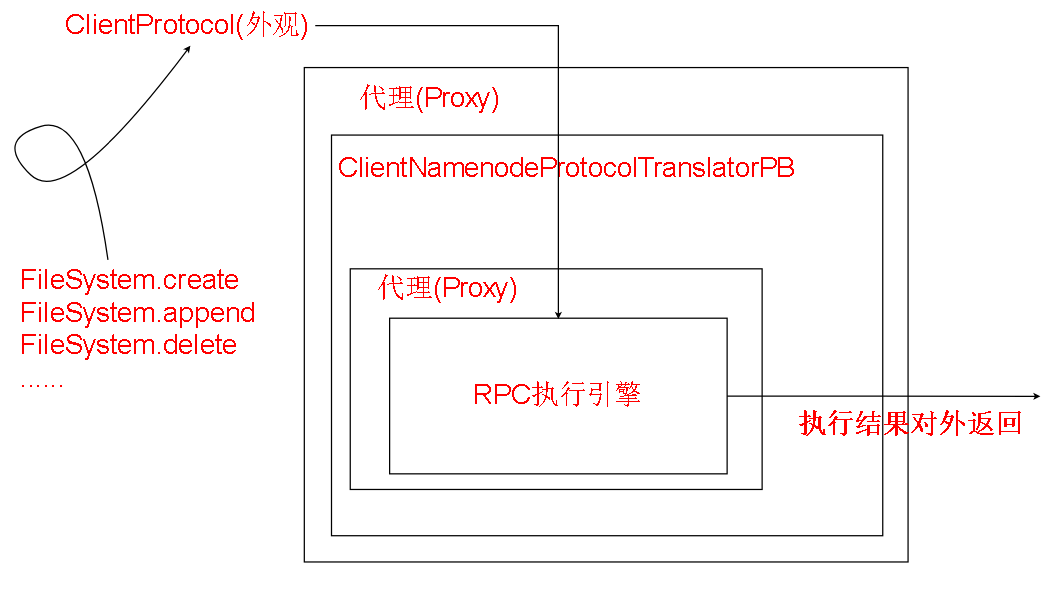
下图是我们调用FileSystem.create方法的时候,最终调用到的关于namenode的地方。
由图可见这里的namenode是一个Proxy(代理),真正的对象其实被封装在代理中。

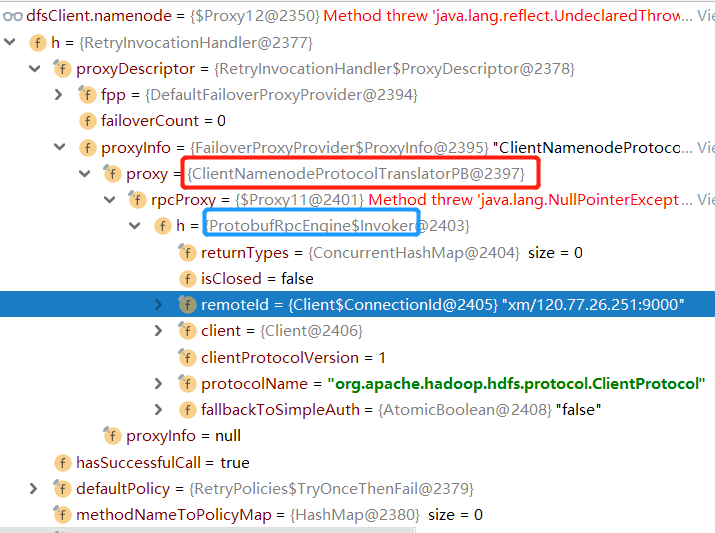
根据JDK动态代理中常用的真实对象->Handler->Proxy$
的封装关系,我们可以看到代理体系中,被代理的第一层(红色框)是一个ClientNamenodeProtocolTranslatorPB的对象
ClientNamenodeProtocolTranslatorPB类中有create,append,delete 等可以向NameNode进行的操作,但他实际上也只是一层壳
实际进行远程调用的还是第二层(蓝色框)ProtobufRpcEngine的Invoker。
下面我们来看看调用Filesystem的create,append,open等方法后,Client这边会得到什么,并且执行什么操作。
当我们调用Filesystem.create , 调用的是namenode的create方法。

如果NameNode在目录结构中创建文件的元数据成功,那么将会把创建的文件的相关信息返回给客户端
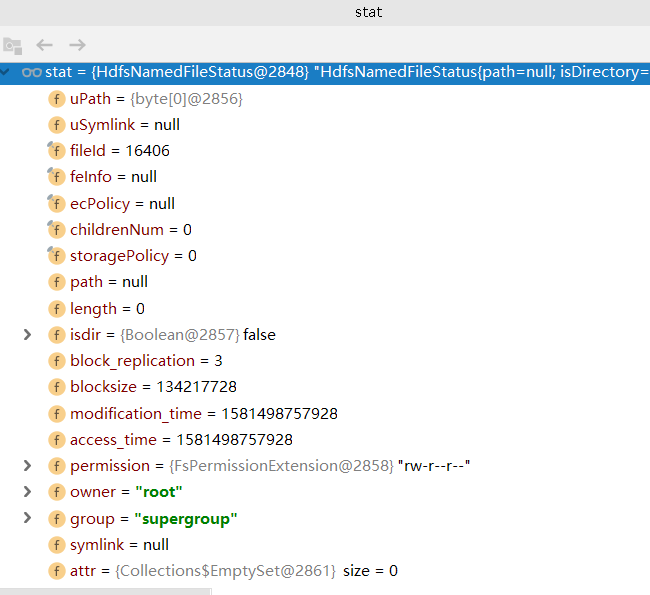
从图中我们可以看到创建的文件的各种信息 比如
文件权限 : rw-r--r-- (对于文件拥有者可读可写,对于拥有者所在群组成员和其他人可读)
备份数 : 3
文件的第一个数据块的信息......
其中值得注意的是文件块(Block)的大小blocksize = 134217728 字节

表明了我们一个块的大小是128MB。128MB是默认值,适用于多数大文件传输的场景。
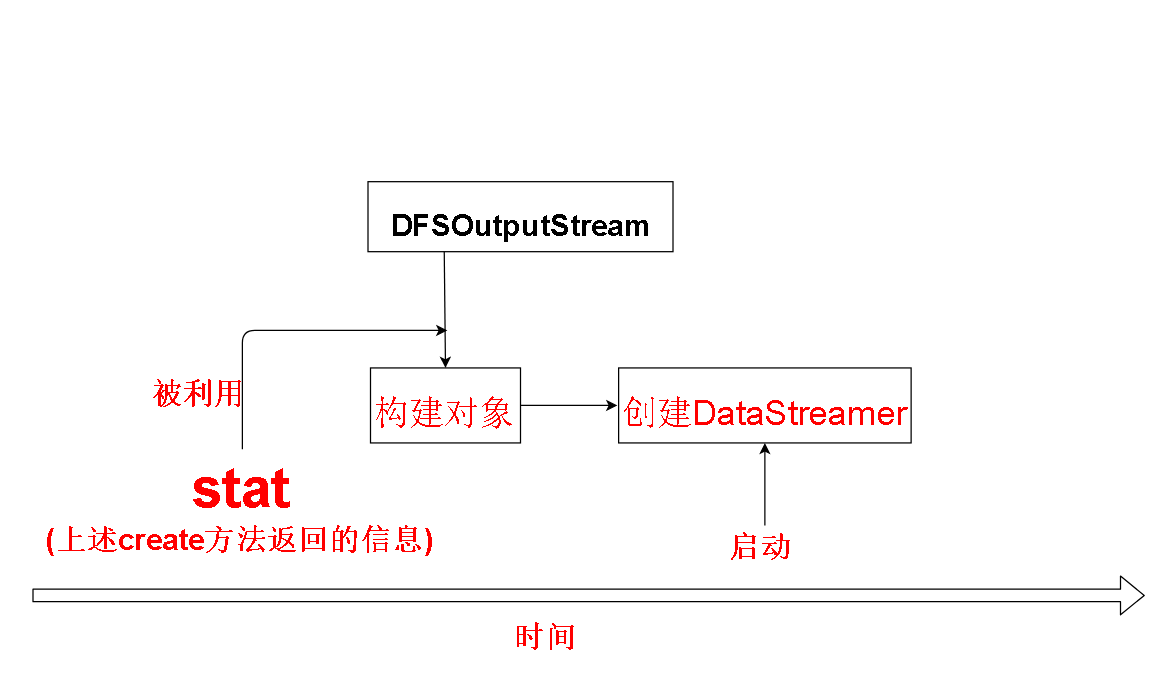
根据文件元数据信息stat,我们创建了一个DFSOutputStream(简化起见将DFSStripedOutputStream与DFSOutStream看作一个讨论,前者其实继承后者)

DFSOutputStream很重要,我们操作的FSDataOutputStream对象中包装了他的对象。
也就是说我们的函数调用实际是DFSOutputStream负责实现的。
并且他负责开启和维护着管理我们数据传输的守护线程DataStreamer
(代码图之后是过程图解)
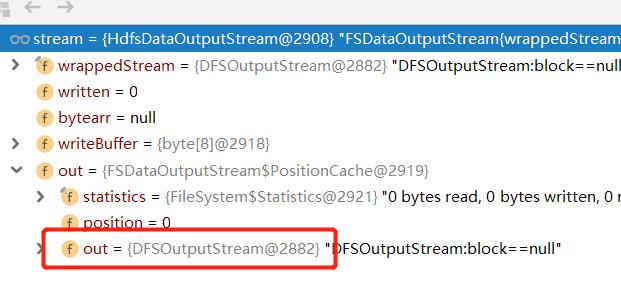
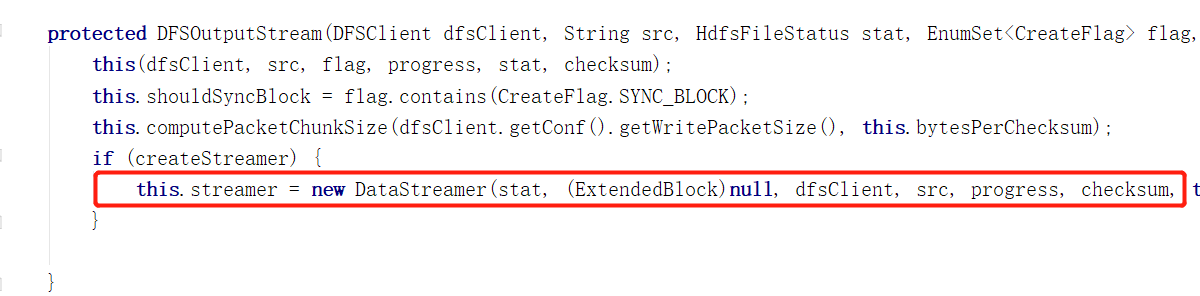
至此,create方法的准备阶段完成。DataStreamer被开启,等待数据被传输。
.FileSystem.append搭建的准备环境:
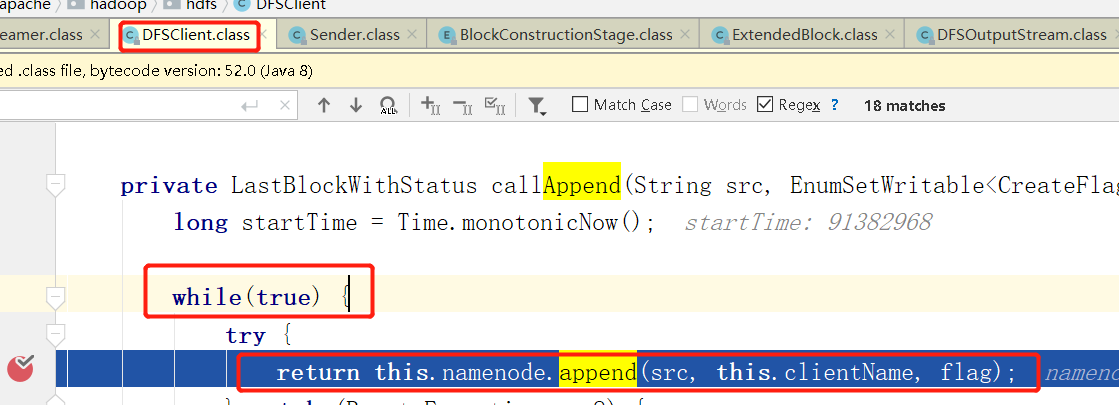
调用FileSystem.append,最终会调用到namenode.append上,也就是RPC调用,和上文原理类似。
我们注意到这里写了while(true)的死循环,主要是如果NameNode繁忙,来不及处理我们的请求的话,就会抛出异常

死循环允许程序产生异常的时候,会休眠一段时间之后重试,而不是直接退出。
如果请求超过了一定时间(5秒),那么将会抛出异常,停止重试。
较为重要的是函数的返回值

我们发现我们从namenode.append那里拿到的东西,有二
一是我们请求append的文件的最后一个数据块的信息
二是我们请求append的文件他本身的信息
比如我们.append("abc/abc");
那么lastBlock返回的是组成abc/abc这个文件的所有数据块中,最后那个数据块的信息。
fileStatus是abc/abc这个文件他本身的信息
我们看看这些信息包括了什么。
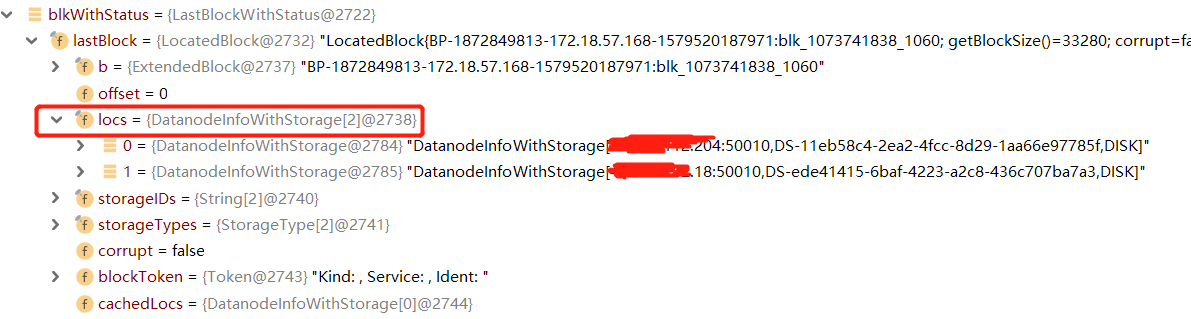
最后一个数据块的信息中,比较重要的是存储这个数据块的位置,位置信息中包含DataNode的IP和端口,根据位置信息,我们可以建立起对块进行读写的流水 线(pipeLine)
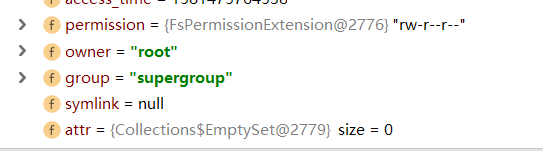
fileStatus包含文件的权限,所有者等等关于文件的信息。
和.create方法一样,我们在获取文件信息后也利用文件信息创建了一个DFSOuputStream,并且在DFSOutputStream构造完后也开启了DataStreamer(DataStreamer的创建和启动不在下图中)
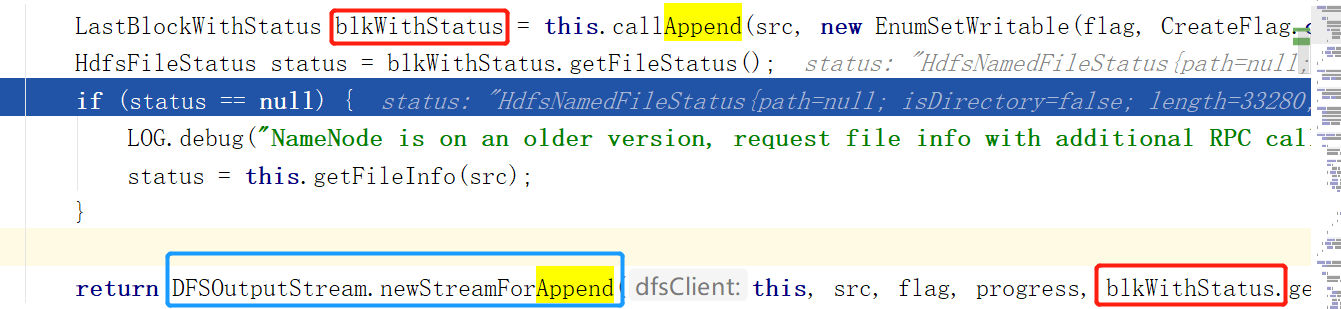
至此,.append的准备阶段完成。
3.open函数做的准备;
当我们调用FileSystem.open , 最终会调用到DFSClient的callGetBlockLocations函数,这个函数通过调用namenode的getBlockLocations获得
数据块的存储位置,我们看看他返回了什么。

一.我们打开只有一个Block的文件
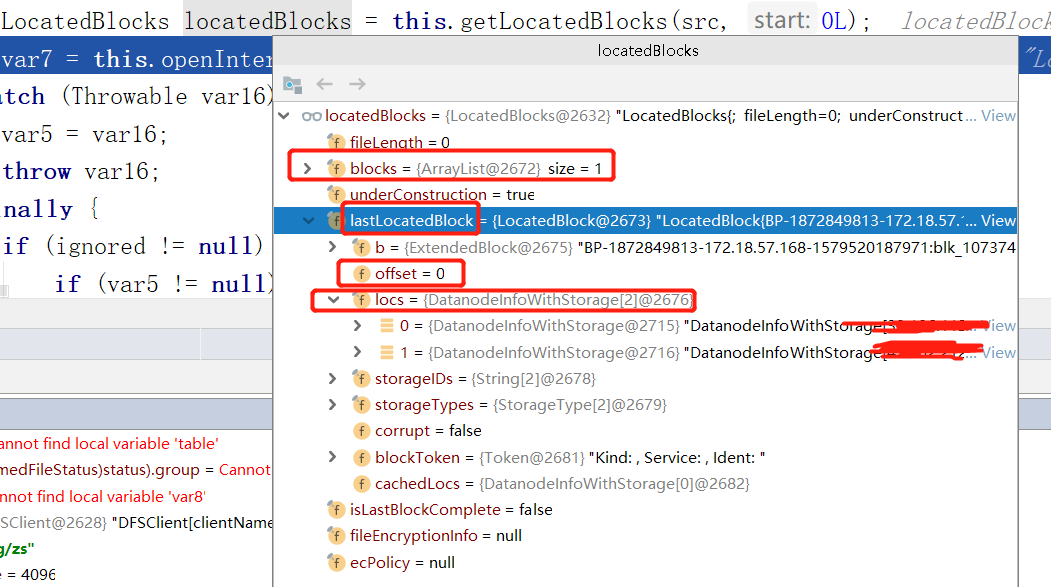
1.我们注意到,blocks(组成文件的数据块),确实只有一个
2.并且lastLocatedBlock(组成文件的最后一个数据块),offset是0,因为只有一个数据块,所以offset是0,等会我们打开有两个数据块的文件,这个值不是0.
3.每个block都有其所在DataNode的位置信息,比较重要的是IP和端口,可以通过他们建立文件读写的流水线
二,我们打开有两个数据块的文件
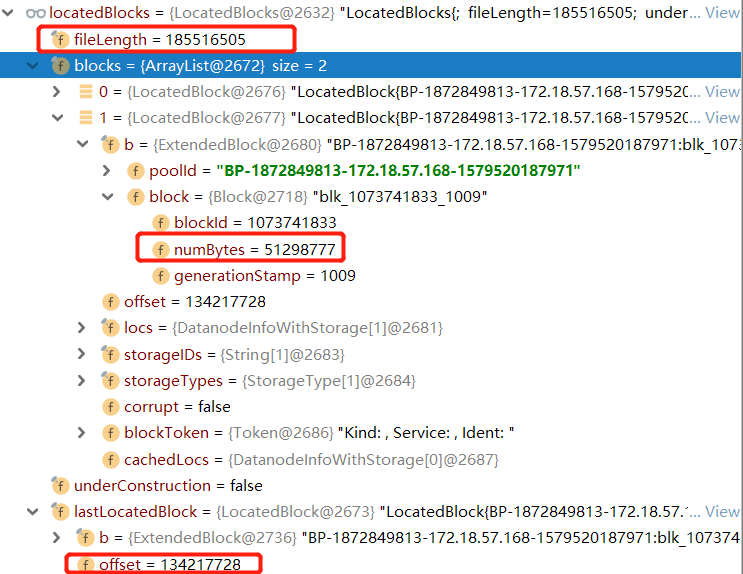
值得注意的是,确实有两个数据块,并且lastLocatedBlock就是第二个数据块(因为只有两个数据块,最后一个数据块当然是第二个数据块)
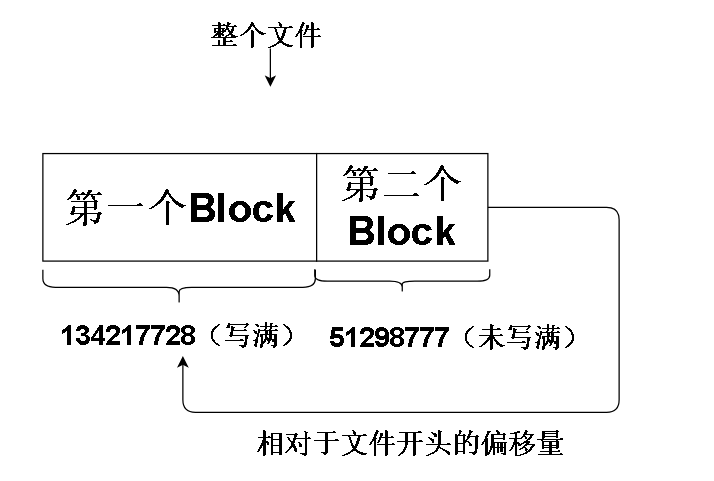
并且第二个数据块的offerset是134217728(字节),换算后就是128MB, 是较新Hadoop默认的一个Block大小,
我们用文件大小fileLength减去一个数据块的大小 185516505 - 134217728 = 51298777 ,正好是第二个数据块的大小。
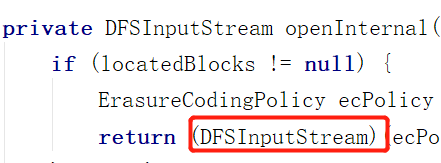
获取到关于文件数据块的信息后,调用DFSClient.openInternal

openInternal会创建DFSInputStream
不像DFSOutputStream , DFSInputStream的创建并不会创建DataStreamer守护线程并启动,因为不需要。
至此,三大开启准备阶段的方法的讲解完毕。
Hadoop3.1.1源码Client详解 : 写入准备-RPC调用与流的建立的更多相关文章
- Hadoop3.1.1源码Client详解 : 入队前数据写入
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 紧接着上一篇: Hadoop3.1.1源码Client详解 : 写入准备-RPC调用与流的建立 先给出 ...
- Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之DataStreamer(Packet发送) : 主干
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 在上一章(Hadoop3.1.1源码Client详解 : 写入准备-RPC调用与流的建立) 我们提到, ...
- Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之ResponseProcessor(ACK接收)
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 紧接着上一篇文章: Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之D ...
- Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览
一.设计原理 1.Hadoop架构: 流水线(PipeLine) 2.Hadoop架构: HDFS中数据块的状态及其切换过程,GS与BGS 3.Hadoop架构: 关于Recovery (Lease ...
- NopCommerce源码架构详解--初识高性能的开源商城系统cms
很多人都说通过阅读.学习大神们高质量的代码是提高自己技术能力最快的方式之一.我觉得通过阅读NopCommerce的源码,可以从中学习很多企业系统.软件开发的规范和一些新的技术.技巧,可以快速地提高我们 ...
- NopCommerce源码架构详解
NopCommerce源码架构详解--初识高性能的开源商城系统cms 很多人都说通过阅读.学习大神们高质量的代码是提高自己技术能力最快的方式之一.我觉得通过阅读NopCommerce的源码,可以从 ...
- Nop--NopCommerce源码架构详解专题目录
最近在研究外国优秀的ASP.NET mvc电子商务网站系统NopCommerce源码架构.这个系统无论是代码组织结构.思想及分层都值得我们学习.对于没有一定开发经验的人要完全搞懂这个源码还是有一定的难 ...
- Hadoop源码学习笔记(4) ——Socket到RPC调用
Hadoop源码学习笔记(4) ——Socket到RPC调用 Hadoop是一个分布式程序,分布在多台机器上运行,事必会涉及到网络编程.那这里如何让网络编程变得简单.透明的呢? 网络编程中,首先我们要 ...
- linux 基础入门(8) 软件安装 rpm、yum与源码安装详解
8.软件 RPM包安装 8.1rpm安装 rpm[选项]软件包名称 主选项 -i 安装 -e卸载 -U升级 -q查找 辅助选项 -ⅴ显示过程 -h --hash 查询 -a-all查询所有安装的包 - ...
随机推荐
- Python读取execl表格
读取execl表格 import xlrd Execl = xlrd.open_workbook(r'Z:\Python学习\python26期视频\day76(allure参数.读excel.发邮件 ...
- Centos7安装python3.6.5
安装python3.6.5,原来的python2.7.5并存 准备环境: 登录你的linux虚拟机或者云服务器,进入命令行界面如下图: 进入这样的窗口就是远程登录成功,我这里使用的是远程连接工具xsh ...
- testclass面试题
http://www.testclass.net/interview/selenium/ seleniuim面试题 http://www.testclass.net/interview/inter ...
- Xampp在Mac下报403的问题
将httpd.conf里的 User daemonGroup daemon 改为 User myusername(当前使用的用户名)Group admin
- 记录 shell学习过程(8)函数
start () { echo "Apache start ...... [OK]" #return 0 可以写一个返回值,比如执行成功返回 0 } stop () { echo ...
- Centos7 安装VNC实现远程桌面
1.设置root用户方法: 1.# 复制一个服务设置的模板,命令如下: cp /lib/systemd/system/vncserver@.service /etc/systemd/system/vn ...
- [P4549] 【模板】裴蜀定理 - GCD
__gcd真好用 #include <bits/stdc++.h> using namespace std; int main() { int n,x,a=0; cin>>n; ...
- vue.js + element中el-select实现拼音匹配,分词、缩写、多音字匹配能力
1.既然要用到拼音搜索,我们就需要一个拼音库,在这里我推荐一个第三方包:https://github.com/xmflswood/pinyin-match,在这里首先对这个包的开发者表示万分的感谢. ...
- 面试题:HashSet、TreeSet 和HashMap 的实现与原理
说下 TreeSet 和 HashSet 什么区别呢? 它们的区别点主要在他们的底层数据结构不同,HashSet 使用的是 HashMap 来实现,而 TreeSet 使用的是 TreeMap 来实现 ...
- IntelliJ IDEA 2017.3尚硅谷-----创建的静态 Java Web