Adam那么棒,为什么还对SGD念念不忘 (3)—— 优化算法的选择与使用策略
在前面两篇文章中,我们用一个框架梳理了各大优化算法,并且指出了以Adam为代表的自适应学习率优化算法可能存在的问题。那么,在实践中我们应该如何选择呢?
本文介绍Adam+SGD的组合策略,以及一些比较有用的tricks.
回顾前文:
不同优化算法的核心差异:下降方向
从第一篇的框架中我们看到,不同优化算法最核心的区别,就是第三步所执行的下降方向:
这个式子中,前半部分是实际的学习率(也即下降步长),后半部分是实际的下降方向。SGD算法的下降方向就是该位置的梯度方向的反方向,带一阶动量的SGD的下降方向则是该位置的一阶动量方向。自适应学习率类优化算法为每个参数设定了不同的学习率,在不同维度上设定不同步长,因此其下降方向是缩放过(scaled)的一阶动量方向。
由于下降方向的不同,可能导致不同算法到达完全不同的局部最优点。An empirical analysis of the optimization of deep network loss surfaces 这篇论文中做了一个有趣的实验,他们把目标函数值和相应的参数形成的超平面映射到一个三维空间,这样我们可以直观地看到各个算法是如何寻找超平面上的最低点的。
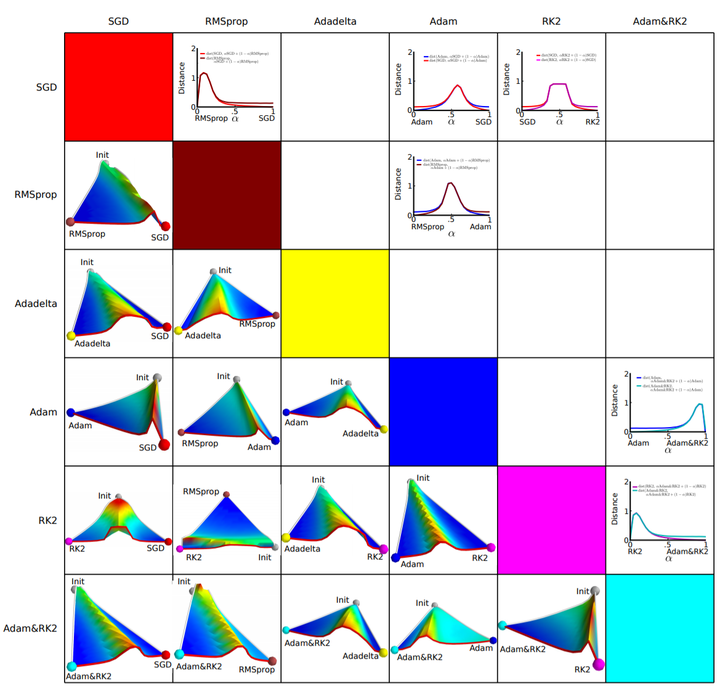
上图是论文的实验结果,横纵坐标表示降维后的特征空间,区域颜色则表示目标函数值的变化,红色是高原,蓝色是洼地。他们做的是配对儿实验,让两个算法从同一个初始化位置开始出发,然后对比优化的结果。可以看到,几乎任何两个算法都走到了不同的洼地,他们中间往往隔了一个很高的高原。这就说明,不同算法在高原的时候,选择了不同的下降方向。
Adam+SGD 组合策略
正是在每一个十字路口的选择,决定了你的归宿。如果上天能够给我一个再来一次的机会,我会对那个女孩子说:SGD!
不同优化算法的优劣依然是未有定论的争议话题。据我在paper和各类社区看到的反馈,主流的观点认为:Adam等自适应学习率算法对于稀疏数据具有优势,且收敛速度很快;但精调参数的SGD(+Momentum)往往能够取得更好的最终结果。
那么我们就会想到,可不可以把这两者结合起来,先用Adam快速下降,再用SGD调优,一举两得?思路简单,但里面有两个技术问题:
- 什么时候切换优化算法?——如果切换太晚,Adam可能已经跑到自己的盆地里去了,SGD再怎么好也跑不出来了。
- 切换算法以后用什么样的学习率?——Adam用的是自适应学习率,依赖的是二阶动量的累积,SGD接着训练的话,用什么样的学习率?
上一篇中提到的论文 Improving Generalization Performance by Switching from Adam to SGD 提出了解决这两个问题的思路。
首先来看第二个问题,切换之后用什么样的学习率。Adam的下降方向是
而SGD的下降方向是
.
必定可以分解为
所在方向及其正交方向上的两个方向之和,那么其在
方向上的投影就意味着SGD在Adam算法决定的下降方向上前进的距离,而在
的正交方向上的投影是 SGD 在自己选择的修正方向上前进的距离。
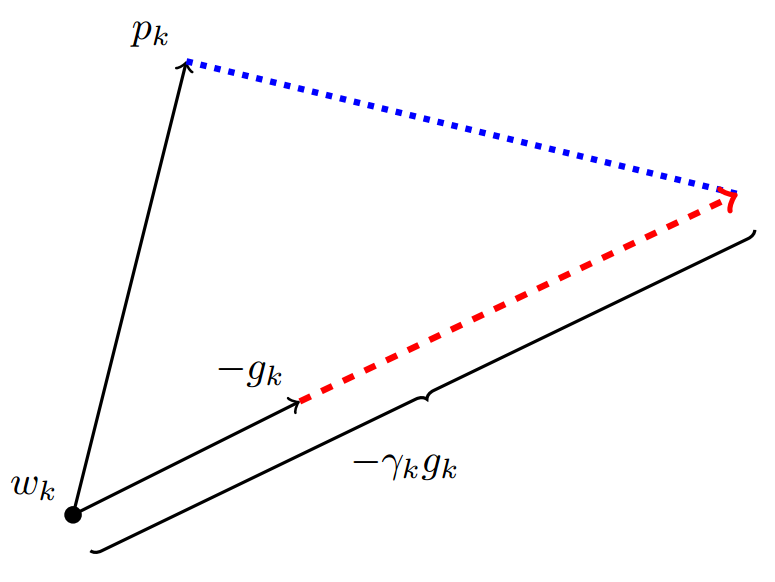 图片来自原文,这里p为Adam下降方向,g为梯度方向,r为SGD的学习率。
图片来自原文,这里p为Adam下降方向,g为梯度方向,r为SGD的学习率。
如果SGD要走完Adam未走完的路,那就首先要接过Adam的大旗——沿着 方向走一步,而后在沿着其正交方向走相应的一步。
这样我们就知道该如何确定SGD的步长(学习率)了——SGD在Adam下降方向上的正交投影,应该正好等于Adam的下降方向(含步长)。也即:
解这个方程,我们就可以得到接续进行SGD的学习率:
为了减少噪声影响,作者使用移动平均值来修正对学习率的估计:
这里直接复用了Adam的 参数。
然后来看第一个问题,何时进行算法的切换。
作者的回答也很简单,那就是当 SGD的相应学习率的移动平均值基本不变的时候,即:
. 每次迭代玩都计算一下SGD接班人的相应学习率,如果发现基本稳定了,那就SGD以
为学习率接班前进。
优化算法的常用tricks
最后,分享一些在优化算法的选择和使用方面的一些tricks。
- 首先,各大算法孰优孰劣并无定论。如果是刚入门,优先考虑SGD+Nesterov Momentum或者Adam.(Standford 231n : The two recommended updates to use are either SGD+Nesterov Momentum or Adam)
- 选择你熟悉的算法——这样你可以更加熟练地利用你的经验进行调参。
- 充分了解你的数据——如果模型是非常稀疏的,那么优先考虑自适应学习率的算法。
- 根据你的需求来选择——在模型设计实验过程中,要快速验证新模型的效果,可以先用Adam进行快速实验优化;在模型上线或者结果发布前,可以用精调的SGD进行模型的极致优化。
- 先用小数据集进行实验。有论文研究指出,随机梯度下降算法的收敛速度和数据集的大小的关系不大。(The mathematics of stochastic gradient descent are amazingly independent of the training set size. In particular, the asymptotic SGD convergence rates are independent from the sample size. [2])因此可以先用一个具有代表性的小数据集进行实验,测试一下最好的优化算法,并通过参数搜索来寻找最优的训练参数。
- 考虑不同算法的组合。先用Adam进行快速下降,而后再换到SGD进行充分的调优。切换策略可以参考本文介绍的方法。
- 数据集一定要充分的打散(shuffle)。这样在使用自适应学习率算法的时候,可以避免某些特征集中出现,而导致的有时学习过度、有时学习不足,使得下降方向出现偏差的问题。
- 训练过程中持续监控训练数据和验证数据上的目标函数值以及精度或者AUC等指标的变化情况。对训练数据的监控是要保证模型进行了充分的训练——下降方向正确,且学习率足够高;对验证数据的监控是为了避免出现过拟合。
- 制定一个合适的学习率衰减策略。可以使用定期衰减策略,比如每过多少个epoch就衰减一次;或者利用精度或者AUC等性能指标来监控,当测试集上的指标不变或者下跌时,就降低学习率。
这里只列举出一些在优化算法方面的trick,如有遗漏,欢迎各位知友在评论中补充,我将持续更新此文。提前致谢!
神经网络模型的设计和训练要复杂得多,initialization, activation, normalization 等等无不是四两拨千斤,这些方面的技巧我再慢慢写,欢迎关注我的知乎专栏和微信公众号(Julius-AI),一起交流学习。
参考文献:
[1] CS231n Convolutional Neural Networks for Visual Recognition
[2] Stochastic Gradient Descent Tricks.
本系列目录:
Adam那么棒,为什么还对SGD念念不忘 (1) —— 一个框架看懂优化算法
Adam那么棒,为什么还对SGD念念不忘 (2)—— Adam的两宗罪
Adam那么棒,为什么还对SGD念念不忘 (3)—— 优化算法的选择与使用策略
Adam那么棒,为什么还对SGD念念不忘 (3)—— 优化算法的选择与使用策略的更多相关文章
- Adam那么棒,为什么还对SGD念念不忘 (1) —— 一个框架看懂优化算法
机器学习界有一群炼丹师,他们每天的日常是: 拿来药材(数据),架起八卦炉(模型),点着六味真火(优化算法),就摇着蒲扇等着丹药出炉了. 不过,当过厨子的都知道,同样的食材,同样的菜谱,但火候不一样了, ...
- Adam那么棒,为什么还对SGD念念不忘 (2)—— Adam的两宗罪
在上篇文章中,我们用一个框架来回顾了主流的深度学习优化算法.可以看到,一代又一代的研究者们为了我们能炼(xun)好(hao)金(mo)丹(xing)可谓是煞费苦心.从理论上看,一代更比一代完善,Ada ...
- zz:一个框架看懂优化算法之异同 SGD/AdaGrad/Adam
首先定义:待优化参数: ,目标函数: ,初始学习率 . 而后,开始进行迭代优化.在每个epoch : 计算目标函数关于当前参数的梯度: 根据历史梯度计算一阶动量和二阶动量:, 计算当前时刻的下降 ...
- 一个框架看懂优化算法之异同 SGD/AdaGrad/Adam
Adam那么棒,为什么还对SGD念念不忘 (1) —— 一个框架看懂优化算法 机器学习界有一群炼丹师,他们每天的日常是: 拿来药材(数据),架起八卦炉(模型),点着六味真火(优化算法),就摇着蒲扇等着 ...
- 从 SGD 到 Adam —— 深度学习优化算法概览(一) 重点
https://zhuanlan.zhihu.com/p/32626442 骆梁宸 paper插画师:poster设计师:oral slides制作人 445 人赞同了该文章 楔子 前些日在写计算数学 ...
- 深度学习剖根问底: Adam优化算法的由来
在调整模型更新权重和偏差参数的方式时,你是否考虑过哪种优化算法能使模型产生更好且更快的效果?应该用梯度下降,随机梯度下降,还是Adam方法? 这篇文章介绍了不同优化算法之间的主要区别,以及如何选择最佳 ...
- 优化深度神经网络(二)优化算法 SGD Momentum RMSprop Adam
Coursera吴恩达<优化深度神经网络>课程笔记(2)-- 优化算法 深度机器学习中的batch的大小 深度机器学习中的batch的大小对学习效果有何影响? 1. Mini-batch ...
- 【DeepLearning】优化算法:SGD、GD、mini-batch GD、Moment、RMSprob、Adam
优化算法 1 GD/SGD/mini-batch GD GD:Gradient Descent,就是传统意义上的梯度下降,也叫batch GD. SGD:随机梯度下降.一次只随机选择一个样本进行训练和 ...
- 神经网络优化算法如何选择Adam,SGD
之前在tensorflow上和caffe上都折腾过CNN用来做视频处理,在学习tensorflow例子的时候代码里面给的优化方案默认很多情况下都是直接用的AdamOptimizer优化算法,如下: o ...
随机推荐
- 【笔记】http协议笔记
本文是本人在复习http协议时,手动整理的资料,以备后续查阅. http(hypertext transfer protocol):超文本协议.是万维网(world wide web,www,也简称为 ...
- Django 用 userena 做用户注册验证登陆
django-admin startproject userena2 cd userena2python manage.py startapp accounts vim userena2/settin ...
- css清除浮动各方法与原理
说到清除浮动的方法,我想网络上应该有不下7,8的方法,介绍这些方法之前,想下为什么清除浮动? 再次回到float这个属性,浮动元素(floats)会被移出文档流,不会影响到块状盒子的布局而只会影响内联 ...
- conda 下配置环境
conda list 查看已有环境(感觉anaconda 中查看的不全,只有指定路径的,但是这个路径和默认创建的路径不一样 然后我发现 要安装traits 库必须要的是PyQt4 但是我的py3下只有 ...
- 第三十一讲:UML类图(上)
类名 成员变量:属性 成员函数:方法 访问权限-属性名-属性的类型 访问权限-方法名-返回值,还可以传递参数列表. 继承类的类图 JAVA里面类的访问权限只有两种:package(默认的访问权限)和p ...
- linux类库之log4j-LogBack-slf4j-commons-logging
log4j http://commons.apache.org/proper/commons-logging/ http://logging.apache.org/log4j/2.x/ The Com ...
- oracle-ORA-01555错误
Snapshot too old 原因:没有足够的撤销空间满足读一致性而需要撤销信息的长查询
- docker-ce 安装和卸载
一.按照官网给的安装方法进行Ubuntu16.04 docker-ce 的安装,步骤如下: 1.由于apt官方库里的docker版本可能比较旧,所以先卸载可能存在的旧版本: sudo apt-get ...
- hdu5444 乱搞 长春网赛
可以暴力. #include<iostream> #include<cstring> #define maxn 1100 using namespace std; int a[ ...
- Java练习 SDUT-2445_小学数学
小学数学 Time Limit: 1000 ms Memory Limit: 65536 KiB Problem Description 今年中秋节,大宝哥带着一盒月饼去看望小学数学老师.碰巧数学老师 ...