HDFS之HBase伪分布安装
1、HBase简介
HBase是Apache Hadoop中的一个子项目,Hbase依托于Hadoop的HDFS作为最基本存储基础单元,通过使用hadoop的DFS工具就可以看到这些这些数据
存储文件夹的结构,还可以通过Map/Reduce的框架(算法)对HBase进行操作,如右侧的图所示:
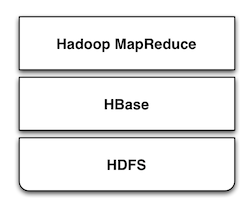
HBase在产品中还包含了Jetty,在HBase启动时采用嵌入式的方式来启动Jetty,因此可以通过web界面对HBase进行管理和查看当前运行的一些状态,非常轻巧。
2、为什么采用HBase?
HBase 不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库.所谓非结构化数据存储就是说HBase是基于列的而不是基于行的模式,这样方面读写你的大数据内容。
HBase是介于Map Entry(key & value)和DB Row之间的一种数据存储方式。就点有点类似于现在流行的Memcache,但不仅仅是简单的一个key对应一个 value,
你很可能需要存储多个属性的数据结构,但没有传统数据库表中那么多的关联关系,这就是所谓的松散数据。
简单来说,你在HBase中的表创建的可以看做是一张很大的表,而这个表的属性可以根据需求去动态增加,在HBase中没有表与表之间关联查询。
你只需要 告诉你的数据存储到Hbase的那个column families 就可以了,不需要指定它的具体类型:char,varchar,int,tinyint,text等等。但是你需要注意HBase中不包含事务此类的功 能。
Apache HBase 和Google Bigtable 有非常相似的地方,一个数据行拥有一个可选择的键和任意数量的列。表是疏松的存储的,因此用户可以给行定义各种不同的列,
对于这样的功能在大项目中非常实用,可以简化设计和升级的成本。
3、Hbase安装:
1、下载jar,并且解药到对应的目录
tar-zxvf hbase-0.98.21-hadoop1-bin.tar.gz -C /opt/install/
2、配置环境变量
sudo vim /etc/prfile
//添加HABSE_HOME
export HBASE_HOME=/opt/install/hbase
//修改PATH
export PATH=$JAVA_HOME/bin:$HBASE_HOME/bin:$HADOOP_HOME/bin:$PATH
3、 修改$HBASE_HOME/conf/hbase-env.sh,修改内容如下:
export JAVA_HOME=/opt/install/jdk1.7.0_79 //使用HBase自带的zookeeper
export HBASE_MANAGES_ZK=true
4、修改$HBASE_HOME/conf/hbase-site.xml,修改内容如下:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://192.168.203.128:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>192.168.203.168</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
5、 (可选)修改文件regionservers:
192.168.203.128
6、 启动hbase,执行命令start-hbase.sh
******启动hbase之前,确保hadoop是运行正常的,并且可以写入文件*******
7、 验证:
(1)执行jps,发现新增加了3个java进程,分别是HMaster、HRegionServer、HQuorumPeer
(2)使用浏览器访问http://hadoop0:60010
4、hbase shell操作
4.1、hbase相关shell命令

4.2对表的操作:
创建表
>create 'users','user_id','address','info'
表users,有三个列族user_id,address,info
列出全部表
>list
得到表的描述
>describe 'users' 创建表
>create 'users_tmp','user_id','address','info'
删除表
>disable 'users_tmp'
>drop 'users_tmp'
4.3、对记录的操作
//添加记录
put 'users','xiaoming','info:age','24';
put 'users','xiaoming','info:birthday','1987-06-17';
put 'users','xiaoming','info:company','alibaba';
put 'users','xiaoming','address:contry','china';
put 'users','xiaoming','address:province','zhejiang';
put 'users','xiaoming','address:city','hangzhou';
put 'users','zhangyifei','info:birthday','1987-4-17';
put 'users','zhangyifei','info:favorite','movie';
put 'users','zhangyifei','info:company','alibaba';
put 'users','zhangyifei','address:contry','china';
put 'users','zhangyifei','address:province','guangdong';
put 'users','zhangyifei','address:city','jieyang';
put 'users','zhangyifei','address:town','xianqiao'; //取得一个id的所有数据
get 'users','xiaoming' //获取一个id,一个列族的所有数据
get 'users','xiaoming','info' //获取一个id,一个列族中一个列的
所有数据
get 'users','xiaoming','info:age'
5、Java操作
package cn.edu.hadoop.hbase; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.ZooKeeperConnectionException;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result; public class LearnHbase {
public static void main(String[] args) throws Exception {
// table();
record();
} /**
* 表相关的操作
*
* @throws IOException
* @throws ZooKeeperConnectionException
* @throws MasterNotRunningException
*/
public static void table() throws Exception {
// 创建表
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.rootdir", "hdfs://master:9000/hbase");
// 使用eclipse时必须添加这个,否则无法定位
conf.set("hbase.zookeeper.quorum", "master"); HBaseAdmin admin = new HBaseAdmin(conf);
boolean isexists = admin.tableExists("table"); if (!isexists) {
HTableDescriptor desc = new HTableDescriptor("table");
desc.addFamily(new HColumnDescriptor("family"));
admin.createTable(desc);
} else {
System.out.println("exists.....");
} // 删除表
admin.disableTable("table");
admin.deleteTable("table");
} public static void record() throws Exception {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.rootdir", "hdfs://master:9000/hbase");
// 使用eclipse时必须添加这个,否则无法定位
conf.set("hbase.zookeeper.quorum", "master"); HTable table = new HTable(conf, "users");
Put put = new Put("xiaoming".getBytes());
put.add("address".getBytes(), "age".getBytes(), "40".getBytes());
table.put(put);
Get get = new Get("xiaoming".getBytes());
Result result = table.get(get);
byte[] bytes = result.getValue("address".getBytes(), "age".getBytes());
System.out.println(new String(bytes)); table.close();
}
}
HDFS之HBase伪分布安装的更多相关文章
- hbase伪分布安装配置
hbase1.2.4 伪分布式安装 注意:在安装hbase或者hadoop的时候,要注意hadoop和hbase的对应关系.如果版本不对应可能造成系统的不稳定和一些其他的问题.在hbase的lib ...
- HBase伪分布安装
1把hbase-0.94.2-security.tar.gz复制到/usr/local 2 解压缩.重命名.设置环境变量 cd /usr/local tar -zxvf hbase--security ...
- HBase伪分布式安装(HDFS)+ZooKeeper安装+HBase数据操作+HBase架构体系
HBase1.2.2伪分布式安装(HDFS)+ZooKeeper-3.4.8安装配置+HBase表和数据操作+HBase的架构体系+单例安装,记录了在Ubuntu下对HBase1.2.2的实践操作,H ...
- Hadoop学习记录(1)|伪分布安装
本文转载自向着梦想奋斗博客 Hadoop是什么? 适合大数据的分布式存储于计算平台 不适用小规模数据 作者:Doug Cutting 受Google三篇论文的启发 Hadoop核心项目 HDFS(Ha ...
- 2015.07.12hadoop伪分布安装
hadoop伪分布安装 Hadoop2的伪分布安装步骤[使用root用户用户登陆]other进去超级用户拥有最高的权限 1.1(桥接模式)设置静态IP ,,修改配置文件,虚拟机IP192.168. ...
- Hbase伪分布式安装
前面的文章已经讲过hadoop伪分布式安装,这里直接介绍hbase伪分布式安装. 1. 下载hbase 版本hbase 1.2.6 2. 解压hbase 3. 修改hbase-env.sh 新增如下内 ...
- CentOS 6.5 伪分布安装
CentOS 6.5 伪分布安装 软件准备 jdk-6u24-linux-i586.bin .hadoop-1.2.1.tar.gz.hadoop-eclipse-plugin-1.2.1.jar ...
- hbase伪分布式安装(单节点安装)
hbase伪分布式安装(单节点安装) http://hbase.apache.org/book.html#quickstart 1. 前提配置好java,环境java变量 上传jdk ...
- Zookeeper,Hbase 伪分布,集群搭建
工作中一般使用的都是zookeeper和Hbase的分布式集群. more /etc/profile cd /usr/local zookeeper-3.4.5.tar.gz zookeeper在安装 ...
随机推荐
- div简单布局理解
以下是div的理解
- Ajax框架,DWR介绍,应用,样例
使用Ajax框架 1. 简化JavaScript的开发难度 2. 解决浏览器的兼容性问题 3. 简化开发流程 经常使用Ajax框架 Prototype 一个纯粹的JavaScript函数库,对Ajax ...
- MVC5 Controller简要创建过程(2):由ControllerFactory创建Controller
上文已经完成了ControllerFactory的创建,接下来就是调用其CreateController()方法创建Controller了. DefaultControllerFactory中Crea ...
- winform CheckedListBox实现全选/全不选
/全选 private void button3_Click(object sender, EventArgs e) { for (int i ...
- css3设置box-pack和box-align让div里面的元素垂直居中
只要设置元素的box-pack和box-align即可,这两个属性当前只有webkit和moz支持,要设置垂直居中的话只需要将这两个属性的值都设置为center即可,需要的朋友可以参考下 以前处理 ...
- setter设置器 gutter访问器
set方法书写规范: 1.必须以set开头,set后跟去掉下划线的实例变量并且首字母大写.ps: setAge:2.一定有参数3.不能有返回值4.一定是对象方法(-开头)5.形参一般是去掉下划线的实例 ...
- Unity截图
什么都不说了,直接上代码. using UnityEngine; using System.Collections; using System.IO; public class CutImage : ...
- MySQL之外键约束
MySQL之外键约束 MySQL有两种常用的引擎类型:MyISAM和InnoDB.目前只有InnoDB引擎类型支持外键约束.InnoDB中外键约束定义的语法如下: [CONSTRAINT [symbo ...
- CentOS yum安装配置lnmp服务器(Nginx+PHP+MySQL)
1.配置防火墙,开启80端口.3306端口 vi /etc/sysconfig/iptables-A INPUT -m state --state NEW -m tcp -p tcp --dport ...
- js-计算器
<div class="main"><h1>HTML5-计算器</h1> <input id="num1& ...