[计算机组成原理] 字符集编码: Unicode 字符集(UTF8/UTF16/UTF32) 和 `BOM`(Byte Order Mark/字节序标记) / UnicodeTextUtils
Unicode字符集
Unicode 字符集的 BOM := Byte Order Mark := 字符顺序标记
BOM(Byte Order Mark)在分析unicode之前,先把bom(byte order mark)说一下。
bom是unicode字符顺序的标识符号,一般以魔数(magic code)的形式出现在以Unicode字符编码的文件的开始的头部,作为该文件的编码标识。
- 举个很简单的例子:
在 windows 下新建一个文本文件,并另存为 utf8 的文件格式。
该文件里面没有任何内容,我们再用Hex Edit来查看该文件的二进制内容:
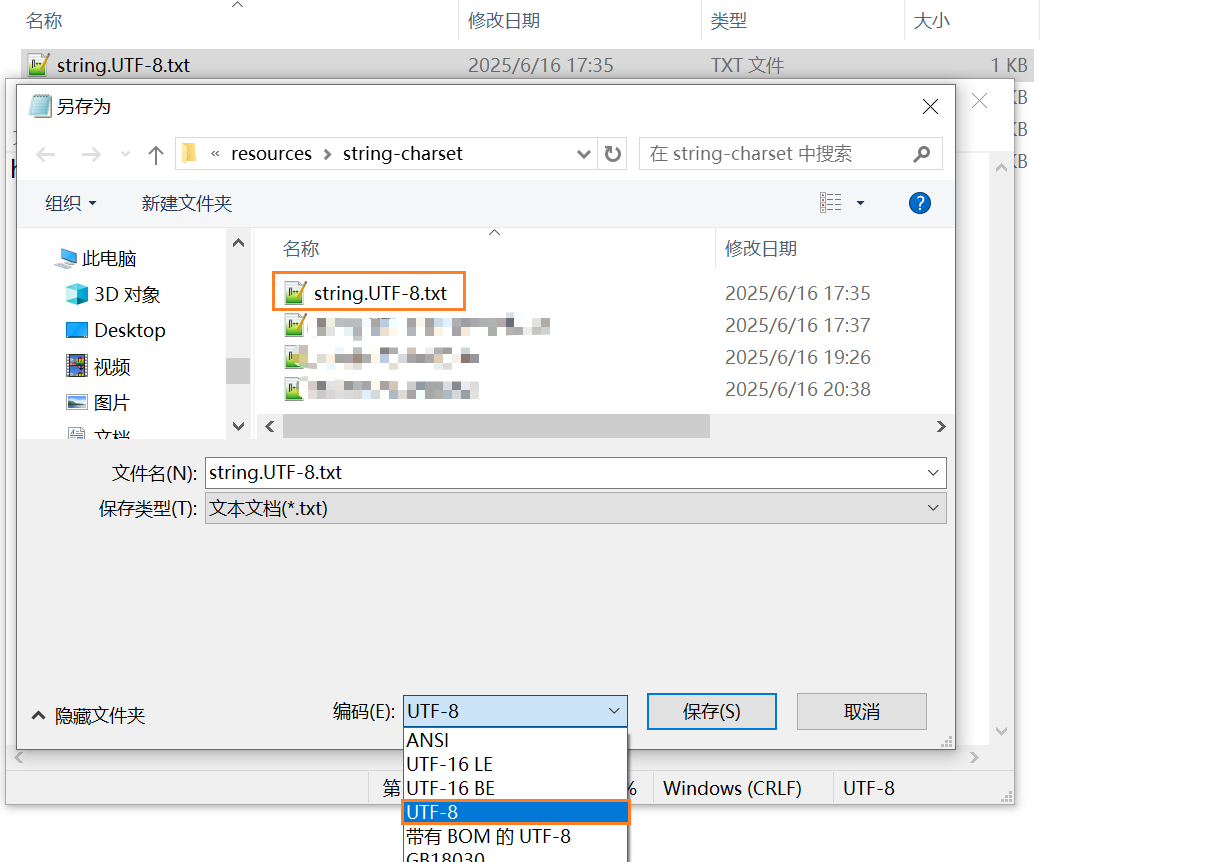

UTF-8

UTF-8 with BOM
0xEF BB BF就是这个文件的bom, 这也就是标识该文件是以utf8为编码格式的。
带 BOM 的 Unicode 文本 vs. 不带 BOM 的 Unicode 文本
UTF-8、UTF-16、UTF-32还区分带BOM的以及不带BOM的 Unicode 文本。BOM的全称为byte-order mark,即字节顺序标记,它是插入到以UTF-8、UTF16或UTF-32编码Unicode文件开头的特殊标记。
这些标记对于 UTF-8 来说并不是必须的。所以,我们们可以将带有
BOM的UTF-8转换为UTF-8。
Unicode 字符集 BOM的对应关系
下面来看看字符编码与其
bom的对应关系
| 字符编码 | Bom (十六进制) |
|---|---|
| UTF-8 | EF BB BF |
| UTF-16 (BE) 大端 | FE FF |
| UTF-16 (LE) 小端 | FF FE |
| UTF-32 (BE) 大端 | 00 00 FE FF |
| UTF-32 (LE) 小端 | FF FE 00 00 |
| GB-18030 | 84 31 95 33 |
UTF-8编码剖析
Unicode编码以code point来标识每一个字符,code point的范围是
0x000000 – 0x10FFFF
也就是每一个字符的code point都落在这个范围
而utf8的一个字符可以用1-4字节来表示,可能有人会说这code point最大也就是0x10FFFF,为什么最大不是可以用三个字节表示呢?那是因为utf8有自己独特的表示格式,先来看看下面的对应关系:
| 字节数 | 字符code point位数 | 最小的code point | 最大的code point | 第一个字节 | 第二个字节 | 第三个字节 | 第四个字节 |
|---|---|---|---|---|---|---|---|
| 1 | 7 | U+0000 | U+007F | 0XXXXXXX | 无 | 无 | 无 |
| 2 | 11 | U+0080 | U+07FF | 110XXXXX | 10XXXXXX | 无 | 无 |
| 3 | 16 | U+0800 | U+FFFF | 1110XXXX | 10XXXXXX | 10XXXXXX | 无 |
| 4 | 21 | U+10000 | U+10FFFF | 11110XXX | 10XXXXXX | 10XXXXXX | 10XXXXXX |
- 当某个字符的code point (cp简称) U+0000 <= cp <= U+007F 落在这个范围内
这时只需要一个字节来表示 0XXXXXXX,将该字符的code point (7位)填入X的位置,就可以得到该字符的utf8的编码后的格式了。
我们以小写字母a举个例子,a的code point是01100001, 经过utf8编码后01100001(0x61)
- 例如,中文汉字
加code point 为0x52A0二进制格式 0101 0010 1010 0000
按照上表中的规则,该字符需要用3个字节来表示
按照填充规则 ,第一个字节1110XXXX->11100101, 第二个字节10XXXXXX -> 10001010 , 第三个字节10XXXXXX -> 10100000组合起来就是
11100101 10001010 10100000:=HEX-> 0xE58AA0
UTF-16编码剖析
utf-16编码的单元是2个字节,也就是16位。
utf-16编码格式在程序内存里经常使用,因为它比较高效,
java中Character 字符用的就是utf-16编码格式
在早期的时候,世界上所有的字符都可以用两个字节标识,也就是code point范围 U+0000 – U+FFFF,这样utf-16就可以很好的表示了,而且也不用像utf8那样按照固定的模板组合,可以直接用字符的code point表示,非常高效。
但是随着时间的推移,所有字符远远不能用两个字节的code point 表示了,那为了兼容code point 超过U+FFFF的字符 就出现字符代理对(Surrogate pair), utf16就是使用代理对来表示code point 范围在 U+10000 -> U+10FFFF之间的字符,当然也就的使用四个字节来表示该字符了。
对于Surrogate pair 与code point 之间的对应关系算法,等会儿再说。
先来看下utf16对于code point 小与U+10000的字符表示,其实用的就是字符的code point表示,这里还区分了大小端的表示法。
- 案例
还是来看中文汉字
加code point 为0x52A0, 推测一下:
如果用utf16大端存储,那就是0x52A0;
如果用utf16小端存储,那就是0xA052
UTF-32编码剖析
utf-32用4个字节表示一个字符
- 直接用字符的
code point表示,非常高效,不需要任何的转化操作- 但占用的存储空间却是很大的,会有空间的浪费。
- 例如:小写字母
a
code point是0x61
用utf32表示就是大端 ->0x00 00 00 61; 小端 ->0x61 00 00 00
这样会造成存储空间的浪费,当然应用场景不同而已,当追求高效的转换而忽略存储空间的浪费这个问题,utf32编码格式是比较好的选择。
而utf8的原则是尽可能的节省存储空间,牺牲转化的效率,各有各的好处。
判别Unicode文本的字符集的方法(Java) 【废弃/不可靠】
亲测,此方法并可绝对可靠(尤其是结果为 UTF-8 的情况)。
/**
* 获取 Unicode 文本的字符集
* @param textBytes
* @return
*/
public static Charset getUnicodeTextCharset(byte[] textBytes){
String encoding = null;
int bomSize = 4;//BOM_SIZE;
byte bom[] = new byte[bomSize];
int n, unread;
//n = internalIn.read(bom, 0, bom.length);
//读取 bom
int off = 0;
int len = bom.length;
int pos = 0;
if (bom == null) {
throw new NullPointerException();
} else if (off < 0 || len < 0 || len > bom.length - off) {
throw new IndexOutOfBoundsException();
}
int avail = bom.length <= textBytes.length ? bom.length : textBytes.length ;//算 bom.length 与 textBytes.length 的最小值
if (avail > 0) {
System.arraycopy(textBytes, pos, bom, off, avail);
}
//判断 unicode 字符集
if ((bom[0] == (byte) 0x00) && (bom[1] == (byte) 0x00)
&& (bom[2] == (byte) 0xFE) && (bom[3] == (byte) 0xFF)) {
encoding = "UTF-32BE";
//unread = n - 4;
} else if ((bom[0] == (byte) 0xFF) && (bom[1] == (byte) 0xFE)
&& (bom[2] == (byte) 0x00) && (bom[3] == (byte) 0x00)) {
encoding = "UTF-32LE";
//unread = n - 4;
} else if ((bom[0] == (byte) 0xEF) && (bom[1] == (byte) 0xBB)
&& (bom[2] == (byte) 0xBF)) {
encoding = "UTF-8";//utf08 with bom
//unread = n - 3;
} else if ((bom[0] == (byte) 0xFE) && (bom[1] == (byte) 0xFF)) {
encoding = "UTF-16BE";
//unread = n - 2;
} else if ((bom[0] == (byte) 0xFF) && (bom[1] == (byte) 0xFE)) {
encoding = "UTF-16LE";
//unread = n - 2;
} else {
// Unicode BOM mark not found, unread all bytes
//defaultEncoding = defaultEncoding == null ? Charset.defaultCharset().name() : defaultEncoding;
//defaultEncoding = defaultEncoding == null ? null : defaultEncoding;
//encoding = defaultEncoding;
//unread = n;
encoding = "UTF-8";//默认: UTF-8 (without bom)
}
// System.out.println("read=" + n + ", unread=" + unread);
return Charset.forName(encoding);
}
最佳实践
UnicodeTextUtils : Unicode文本处理工具类
UnicodeCharsetEnum
import com.xxx.sdk.pojo.text.enums.DigitalModeEnum;
/**
* Unicode 字符集
* @updateTime 2025.6.17 19:48
*/
public enum UnicodeCharsetEnum {
UTF8_WITH_BOM("UTF8_WITH_BOM", "UTF-8 With BOM", "UTF-8"),
UTF8_WITHOUT_BOM("UTF8_WITHOUT_BOM", "UTF-8 Without BOM", "UTF-8"),
//小端
UTF16LE_WITH_BOM("UTF16LE_WITH_BOM", "UTF-16LE With BOM", "UTF-16LE"),
UTF16LE_WITHOUT_BOM("UTF16LE_WITHOUT_BOM", "UTF-16LE Without BOM", "UTF-16LE"),
//大端
UTF16BE_WITH_BOM("UTF16BE_WITH_BOM", "UTF-16BE With BOM", "UTF-16BE"),
UTF16BE_WITHOUT_BOM("UTF16BE_WITHOUT_BOM", "UTF-16BE Without BOM", "UTF-16BE"),
//小端
UTF32LE_WITH_BOM("UTF32LE_WITH_BOM", "UTF-32LE With BOM", "UTF-32LE"),
UTF32LE_WITHOUT_BOM("UTF32LE_WITHOUT_BOM", "UTF-32LE Without BOM", "UTF-32LE"),
//大端
UTF32BE_WITH_BOM("UTF32BE_WITH_BOM", "UTF-32BE With BOM", "UTF-32BE"),
UTF32BE_WITHOUT_BOM("UTF32BE_WITHOUT_BOM", "UTF-32BE Without BOM", "UTF-32BE");
private final String charsetCode;
private final String charsetName;
//java中定义的字符集
private final String javaCharset;
public final static String CODE_PARAM = "code";
public final static String NAME_PARAM = "name";
UnicodeCharsetEnum(String charsetCode, String charsetName, String javaCharset) {
this.charsetCode = charsetCode;
this.charsetName = charsetName;
this.javaCharset = javaCharset;
}
public static UnicodeCharsetEnum findByCharsetCode(String charsetCode) {
for (UnicodeCharsetEnum type : values()) {
if (type.getCharsetCode().equals(charsetCode)) {
return type;
}
}
return null;
}
public static UnicodeCharsetEnum findByCharsetName(String charsetName) {
for (UnicodeCharsetEnum type : values()) {
if (type.getCharsetName().equals(charsetName)) {
return type;
}
}
return null;
}
public String getCharsetName() {
return charsetName;
}
public String getCharsetCode() {
return charsetCode;
}
public String getJavaCharset() {
return javaCharset;
}
}
UnicodeTextUtils
import com.xxx.sdk.pojo.text.UnicodeCharsetEnum;
import java.io.UnsupportedEncodingException;
/**
* Unicode 文本处理工具类
* @updateTime 2025.6.17 19:47
*/
public class UnicodeTextUtils {
/**
* 将指定文本转换为指定 Unicode 字符集的字节数组
* @param text Java 字符串
* eg: "hello world!你好!"
* @param unicodeCharset
* eg: UTF8_WITH_BOM
* @return 指定 Unicode 字符集的字节数组
* @usage String newText = new String( textToBytes(text="hello world!你好!", UTF8_WITH_BOM) , UTF8_WITH_BOM.charset)
*/
public static byte [] textToBytes(String text, UnicodeCharsetEnum unicodeCharset) throws UnsupportedEncodingException {
byte [] textBytes = null;
switch (unicodeCharset) {
// UTF8 不涉及 字节序(大小端)问题 (每个文本字符的最小单元: 1 byte)
case UTF8_WITH_BOM : {
byte [] textBytes1 = (new String( text )).getBytes( unicodeCharset.getJavaCharset() );//"UTF-8"
int bomLength = 3;
byte [] textBytes2 = new byte [textBytes1.length + bomLength];//预留 3个字节,填充 bom
System.arraycopy(textBytes1, 00, textBytes2, 0 + bomLength, textBytes1.length);
textBytes2[0] = (byte)0xef;
textBytes2[1] = (byte)0xbb;
textBytes2[2] = (byte)0xbf;
//text == newText == "hello world!你好!", newText == [ (byte)0xef, (byte)0xbb, (byte)0xbf, 104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100, 33, -28, -67, -96, -27, -91, -67, 33 ]
//String newText = new String( textBytes2, unicodeCharset.getJavaCharset() );
textBytes = textBytes2;
break;
}
case UTF8_WITHOUT_BOM : {
byte [] textBytes1 = (new String( text )).getBytes( unicodeCharset.getJavaCharset() );//"UTF-8"
//text == newText == "hello world!你好!", newText == [ 104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100, 33, -28, -67, -96, -27, -91, -67, 33 ]
//String newText = new String( textBytes2, unicodeCharset.getJavaCharset() );
textBytes = textBytes1;
break;
}
//UTF16 设计 字节序(大小端)问题 (每个文本字符的最小单元: 2 byte)
case UTF16LE_WITH_BOM : {
byte [] textBytes1 = (new String( text )).getBytes( unicodeCharset.getJavaCharset() );//"UTF-16LE"
int bomLength = 2;
byte [] textBytes2 = new byte [textBytes1.length + bomLength];//预留 2个字节,填充 bom
System.arraycopy(textBytes1, 00, textBytes2, 0 + bomLength, textBytes1.length);
textBytes2[0] = (byte)0xff;
textBytes2[1] = (byte)0xfe;
//text == newText == "hello world!你好!", newText == [ 0xff/-1, 0xfe/-2, 104, 0, 101, 0, 108, 0, 108, 0, 111, 0, 32, 0, 119, 0, 111, 0, 114, 0, 108, 0, 100, 0, 33, 0, 96, 79, 125, 89, 33, 0 ]
//String newText = new String( textBytes2, unicodeCharset.getJavaCharset() );
textBytes = textBytes2;
break;
}
case UTF16LE_WITHOUT_BOM : {
byte [] textBytes1 = (new String( text )).getBytes( unicodeCharset.getJavaCharset() );//"UTF-16LE"
//text == newText == "hello world!你好!", newText == [ 104, 0, 101, 0, 108, 0, 108, 0, 111, 0, 32, 0, 119, 0, 111, 0, 114, 0, 108, 0, 100, 0, 33, 0, 96, 79, 125, 89, 33, 0 ]
//String newText = new String( textBytes2, unicodeCharset.getJavaCharset() );
textBytes = textBytes1;
break;
}
case UTF16BE_WITH_BOM : {
//方法1
byte [] textBytes1 = (new String( text )).getBytes( unicodeCharset.getJavaCharset() );//"UTF-16BE"
int bomLength = 2;
byte [] textBytes2 = new byte [textBytes1.length + bomLength];//预留 2个字节,填充 bom
System.arraycopy(textBytes1, 00, textBytes2, 0 + bomLength, textBytes1.length);
textBytes2[0] = (byte)0xfe;
textBytes2[1] = (byte)0xff;
//方法2
//byte [] textBytes2 = (new String( text )).getBytes( "UTF-16" );//仅适用于 utf16 BE with bom(0xfe = -2, 0xff=-1)
//text == newText == "hello world!你好!", newText == [ 0xfe/-2, 0xff/-1, 0, 104, 0, 101, 0, 108, 0, 108, 0, 111, 0, 32, 0, 119, 0, 111, 0, 114, 0, 108, 0, 100, 0, 33, 79, 96, 89, 125, 0, 33 ]
//String newText = new String( textBytes2, unicodeCharset.getJavaCharset() );
textBytes = textBytes2;
break;
}
case UTF16BE_WITHOUT_BOM : {
byte [] textBytes1 = (new String( text )).getBytes( unicodeCharset.getJavaCharset() );//"UTF-16BE"
//text == newText == "hello world!你好!", newText == [ 0, 104, 0, 101, 0, 108, 0, 108, 0, 111, 0, 32, 0, 119, 0, 111, 0, 114, 0, 108, 0, 100, 0, 33, 79, 96, 89, 125, 0, 33 ]
//String newText = new String( textBytes2, unicodeCharset.getJavaCharset() );
textBytes = textBytes1;
break;
}
//UTF32 设计 字节序(大小端)问题 (每个文本字符的最小单元: 4 byte)
case UTF32LE_WITH_BOM : {
byte [] textBytes1 = (new String( text )).getBytes( unicodeCharset.getJavaCharset() );//"UTF-32LE"
int bomLength = 4;
byte [] textBytes2 = new byte [textBytes1.length + bomLength];//预留 4个字节,填充 bom
System.arraycopy(textBytes1, 00, textBytes2, 0 + bomLength, textBytes1.length);
textBytes2[0] = (byte)0xff;
textBytes2[1] = (byte)0xfe;
textBytes2[2] = (byte)0x00;
textBytes2[3] = (byte)0x00;
//text == newText == "hello world!你好!", newText ==
//String newText = new String( textBytes2, unicodeCharset.getJavaCharset() );
textBytes = textBytes2;
break;
}
case UTF32LE_WITHOUT_BOM : {
byte [] textBytes1 = (new String( text )).getBytes( unicodeCharset.getJavaCharset() );//"UTF-32LE"
//text == newText == "hello world!你好!", newText ==
//String newText = new String( textBytes2, unicodeCharset.getJavaCharset() );
textBytes = textBytes1;
break;
}
case UTF32BE_WITH_BOM : {
//方法1
byte [] textBytes1 = (new String( text )).getBytes( unicodeCharset.getJavaCharset() );//"UTF-32BE"
int bomLength = 4;
byte [] textBytes2 = new byte [textBytes1.length + bomLength];//预留 2个字节,填充 bom
System.arraycopy(textBytes1, 00, textBytes2, 0 + bomLength, textBytes1.length);
textBytes2[0] = (byte)0x00;
textBytes2[1] = (byte)0x00;
textBytes2[2] = (byte)0xfe;
textBytes2[3] = (byte)0xff;
//text == newText == "hello world!你好!", newText ==
//String newText = new String( textBytes2, unicodeCharset.getJavaCharset() );
textBytes = textBytes2;
break;
}
case UTF32BE_WITHOUT_BOM : {
byte [] textBytes1 = (new String( text )).getBytes( unicodeCharset.getJavaCharset() );//"UTF-32BE"
//方法2
//byte [] textBytes2 = (new String( text )).getBytes( "UTF-32" );//仅适用于 utf32 BE without bom(0x00, 0x00, 0xfe = -2, 0xff=-1)
//text == newText == "hello world!你好!", newText == [ 0, 0, 0, 104, 0, 0, 0, 101, 0, 0, 0, 108, 0, 0, 0, 108, 0, 0, 0, 111, 0, 0, 0, 32, 0, 0, 0, 119, 0, 0, 0, 111, 0, 0, 0, 114, 0, 0, 0, 108, 0, 0, 0, 100, 0, 0, 0, 33, 0, 0, 79, 96, 0, 0, 89, 125, 0, 0, 0, 33 ]
//String newText = new String( textBytes2, unicodeCharset.getJavaCharset() );
textBytes = textBytes1;
break;
}
default: {
//do nothing
break;
}
}
return textBytes;
}
}
UnicodeTextUtilsTest
package com.xxx.sdk.utils.text;
import com.xxx.sdk.pojo.text.UnicodeCharsetEnum;
import com.xxx.sdk.utils.bytes.BytesUtils;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
@Slf4j
public class UnicodeTextUtilsTest {
@Test
public void textToBytesTest() throws Exception {
String text = "hello world!你好!";
//efbbbf68656c6c6f20776f726c6421e4bda0e5a5bd21
log.info( "UTF8_WITH_BOM:{}", BytesUtils.bytesToHexString( UnicodeTextUtils.textToBytes(text, UnicodeCharsetEnum.UTF8_WITH_BOM) ));
//68656c6c6f20776f726c6421e4bda0e5a5bd21
log.info( "UTF8_WITHOUT_BOM:{}", BytesUtils.bytesToHexString( UnicodeTextUtils.textToBytes(text, UnicodeCharsetEnum.UTF8_WITHOUT_BOM) ));
//fffe680065006c006c006f00200077006f0072006c0064002100604f7d592100
log.info( "UTF16LE_WITH_BOM:{}", BytesUtils.bytesToHexString( UnicodeTextUtils.textToBytes(text, UnicodeCharsetEnum.UTF16LE_WITH_BOM) ));
//680065006c006c006f00200077006f0072006c0064002100604f7d592100
log.info( "UTF16LE_WITHOUT_BOM:{}", BytesUtils.bytesToHexString( UnicodeTextUtils.textToBytes(text, UnicodeCharsetEnum.UTF16LE_WITHOUT_BOM) ));
//feff00680065006c006c006f00200077006f0072006c006400214f60597d0021
log.info( "UTF16BE_WITH_BOM:{}", BytesUtils.bytesToHexString( UnicodeTextUtils.textToBytes(text, UnicodeCharsetEnum.UTF16BE_WITH_BOM) ));
//00680065006c006c006f00200077006f0072006c006400214f60597d0021
log.info( "UTF16BE_WITHOUT_BOM:{}", BytesUtils.bytesToHexString( UnicodeTextUtils.textToBytes(text, UnicodeCharsetEnum.UTF16BE_WITHOUT_BOM) ));
//fffe000068000000650000006c0000006c0000006f00000020000000770000006f000000720000006c0000006400000021000000604f00007d59000021000000
log.info( "UTF32LE_WITH_BOM:{}", BytesUtils.bytesToHexString( UnicodeTextUtils.textToBytes(text, UnicodeCharsetEnum.UTF32LE_WITH_BOM) ));
//68000000650000006c0000006c0000006f00000020000000770000006f000000720000006c0000006400000021000000604f00007d59000021000000
log.info( "UTF32LE_WITHOUT_BOM:{}", BytesUtils.bytesToHexString( UnicodeTextUtils.textToBytes(text, UnicodeCharsetEnum.UTF32LE_WITHOUT_BOM) ));
//0000feff00000068000000650000006c0000006c0000006f00000020000000770000006f000000720000006c000000640000002100004f600000597d00000021
log.info( "UTF32BE_WITH_BOM:{}", BytesUtils.bytesToHexString( UnicodeTextUtils.textToBytes(text, UnicodeCharsetEnum.UTF32BE_WITH_BOM) ));
//00000068000000650000006c0000006c0000006f00000020000000770000006f000000720000006c000000640000002100004f600000597d00000021
log.info( "UTF32BE_WITHOUT_BOM:{}", BytesUtils.bytesToHexString( UnicodeTextUtils.textToBytes(text, UnicodeCharsetEnum.UTF32BE_WITHOUT_BOM) ));
}
}
Y 推荐文献
X 参考文献
UTF-8、UTF-16、UTF-32还区分带BOM的以及不带BOM的 Unicode 文本。
[计算机组成原理] 字符集编码: Unicode 字符集(UTF8/UTF16/UTF32) 和 `BOM`(Byte Order Mark/字节序标记) / UnicodeTextUtils的更多相关文章
- 彻底搞懂字符编码(unicode,mbcs,utf-8,utf-16,utf-32,big endian,little endian...)[转]
最近有一些朋友常问我一些乱码的问题,和他们交流过程中,发现这个编码的相关知识还真是杂乱不堪,不少人对一些知识理解似乎也有些偏差,网上百度, google的内容,也有不少以讹传讹,根本就是错误的(例如说 ...
- Unicode 与 utf8 utf16 utf32的关系
Unicode是计算机领域的一项行业标准,它对世界上绝大部分的文字的进行整理和统一编码,Unicode的编码空间可以划分为17个平面(plane),每个平面包含2的16次方(65536)个码位.17个 ...
- UTF-8文件的Unicode签名BOM(Byte Order Mark)问题记录(EF BB BF)
背景 楼主测试的批量发送信息功能上线之后,后台发现存在少量的ERROR日志,日志内容为手机号码格式不正确. 此前测试过程中没有出现过此类问题,从运营人员拿到的发送列表的TXT,号码是符合规则的,且格式 ...
- Unicode与UTF-8/UTF-16/UTF-32的区别
Unicode的最初目标,是用1个16位的编码来为超过65000字符提供映射.但这还不够,它不能覆盖全部历史上的文字,也不能解决传输的问题 (implantation head-ache's),尤其在 ...
- 多字节字符集与Unicode字符集
在计算机中字符通常并不是保存为图像,每个字符都是使用一个编码来表示的,而每个字符究竟使用哪个编码代表,要取决于使用哪个字符集(charset). 多字节字符集: 在最初的时候,Internet上只有一 ...
- Unicode 与 Unicode Transformation Format(UTF,UTF-8 / UTF-16 / UTF-32)
ASCII(American Standard Code for Information Interchange):早期它使用7 bits来表示一个字符,总共表示27 = 128个字符:后来扩展到8 ...
- Unicode 与 Unicode Transformation Format(UTF-8 / UTF-16 / UTF-32)
ASCII(American Standard Code for Information Interchange):早期它使用7 bits来表示一个字符,总共表示27 = 128个字符:后来扩展到8 ...
- 刨根究底字符编码之十一——UTF-8编码方式与字节序标记
UTF-8编码方式与字节序标记 一.UTF-8编码方式 1. 接下来将分别介绍Unicode字符集的三种编码方式:UTF-8.UTF-16.UTF-32.这里先介绍应用最为广泛的UTF-8. 为满足基 ...
- 各种编码中汉字所占字节数;中文字符集编码Unicode ,gb2312 , cp936 ,GBK,GB18030
vim settings set fileencodings=utf-8,ucs-bom,gb18030,gbk,gb2312,cp936,latin1set termencoding=utf-8se ...
- 字符集编码Unicode ,gb2312 cp936
这是一篇程序员写给程序员的趣味读物.所谓趣味是指可以比较轻松地了解一些原来不清楚的概念,增进知识,类似于打RPG游戏的升级.整理这篇文章的动机是两个问题: 问题一:使用Windows记事本的“另存为” ...
随机推荐
- centos7 docker卸载老版本并升级到最新稳定版本
一.前言 docker的版本分为社区版docker-ce和企业版dokcer-ee社,区版是免费提供给个人开发者和小型团体使用的,企业版会提供额外的收费服务,比如经过官方测试认证过的基础设施.容器.插 ...
- Delphi MEMO 循环往上往下滚动
// 循环往上滚动 if Memo1.Perform(EM_SCROLL,SB_LINEDOWN,0)=0 then begin Memo1.Perform(WM_VSCROLL,SB_TOP,0); ...
- Delphi 让窗体自适应屏幕显示
unit Unit1; interface uses Winapi.Windows, Winapi.Messages, System.SysUtils, System.Variants, System ...
- VSCode 中 Json 文件介绍
Visual Studio Code 官方文档 1. Json 配置文件 Editing JSON with Visual Studio Code settings.json 分类 defaultse ...
- 阶段升级,zhitan-ems集成建筑能耗支路和分项功能
升级介绍 自从春节上班后开源以来,zhitan-ems收到了大家很多的赞誉和任何,很多朋友也提出了中肯的意见.感谢大家. 很多朋友的建议里提到建筑能耗功能,依据大家意见,我们加班加点实现了简单的建筑能 ...
- 请运行命令来卸载Oracle主目录
卸载Oracle数据库碰见的一个不一样的操作,留爪. 正常点的软件卸载直接点卸载即可, Oracle 卸载非要来点不一样警告, 如图: 注意:不要被图里的斜杠符号忽略了,准确的应该是: # 注意斜杠 ...
- vue3第二次传递数据方法无法获取到最新的值
使用reactive父组件第二次传递给子组件的数据:方法中可以获取到最新数据 <template> <div> <div> <h1>子组件</h1 ...
- ArrayBlockingQueue的put方法底层原理
一.ArrayBlockingQueue的put方法底层原理 ArrayBlockingQueue 是 Java 并发包 (java.util.concurrent) 中的一个基于数组实现的有界阻塞队 ...
- springmvc实现转发和重定向
一. @RequestMapping("/testVoid") public String testVoid(HttpServletRequest request){ //转发方式 ...
- JAVA基础之多线程二期
一.主线程 public class MainThread { /** * 主线程:指执行main()方法的线程,且该线程是单线程,从上到下执行 * JVM执行main()方法时,JVM会将main( ...