怎么解决DB读写分离,导致数据不一致问题?
前言
在互联网中大型项目中,读写分离应该是我们小伙伴经常听说的,这个主要解决大流量请求时,提高系统的吞吐量。因为绝大部分互联网产品都是读多写少,大部分都是读请求,很小部分是写请求。

上图:
1)一个主库负责写请求,更新数据
2)两个从库负责读请求,可以提高系统吞吐量
3)主库和从库之间同步数据
为什么产生数据不一致
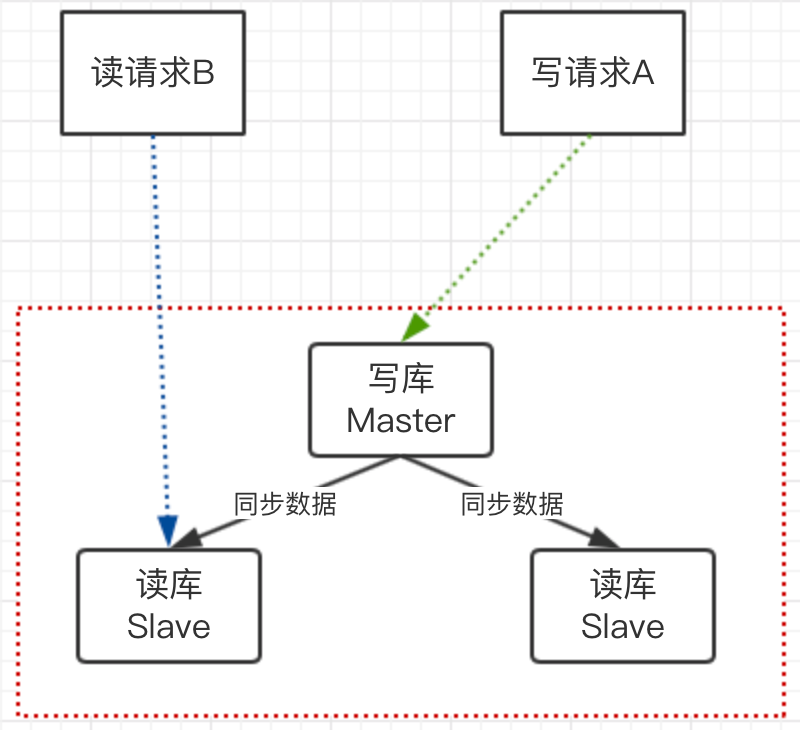
上图中业务流程
1)写请求A进行数据更新,但写库还没有来得及把更新的数据更新到读库
2)读请求B进行数据查询,请求B是访问的读库,获取的是旧值
3)因为写库和读库之间存在同步延迟,导致数据在不同库中不一致
这个问题我们如何解决?
方案一:利用数据库自身特性
我们一般用的数据库是mysql和oracle,mysql是我们互联网项目都会用到的,oracle一般大公司用的比较多(很贵啊)。
我们分析一下问题,原因就是在主库(写库)与从库(读库)之间数据同步延迟导致,mysql中有全同步复制机制、半同步复制、异步复制三种复制方案(小伙伴可以自行去了解)。
mysql全同步复制

全同步复制,当A提交更新请求主库事务之后,不是立即返回,而是等到所有的从库节点必须收到、APPLY并且提交这些事务,主库线程才返回请求A结果,才能做后续操作。这样就解决了数据同步延迟的问题。
问题:但这个同步方案严重的问题就是写请求耗时会很长,而且会随者从库数量增加,耗时也会增加。(不推荐)
oracle共享存储
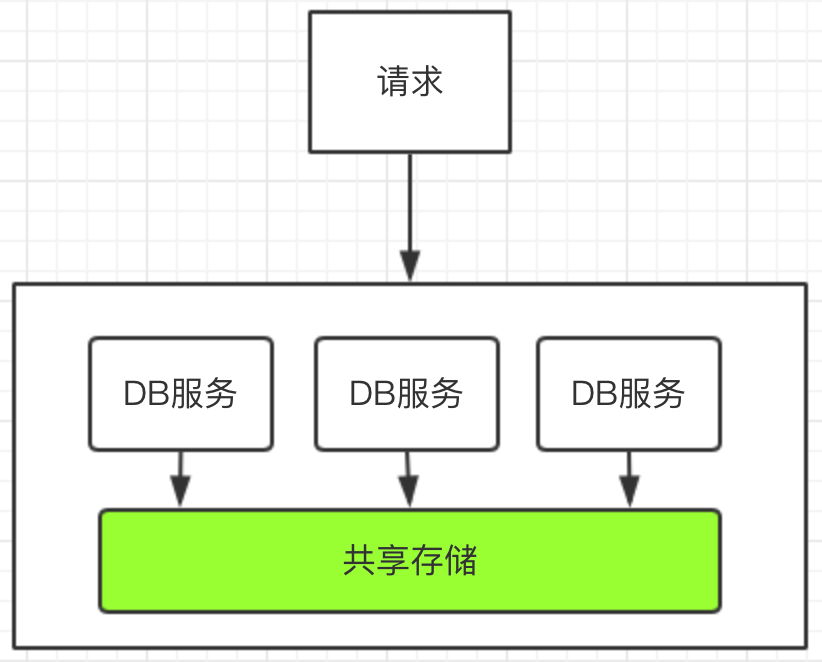
上图采用了oracle RAC方案,DB服务其实就代表一个应用服务,所有的数据存储在同一个地方,所有就不存在数据同步这个问题。当然这个部署方案不是我们严格意义上面的读写分离,存储是独立的。
方案二:不解决
我们设计任何架构方案,都要围绕着业务,如果业务能够接受可以不解决;其实很多互联网产品都有短时间的数据不一致问题。如:58同城,美团,贴吧等。
但有些场景是不允许的。如:

上图中:
1)用户写了一篇文章,点击保存按钮
2)系统执行保存方法,提示用户保存成功
3)保存成功后一般系统就会立即跳转到文章列表,按照时间倒序,最新的文章排在第一个,这个业务是很正常的,让用户可以看到自己的文章列表
4)这样就是调用获取文章列表的方法getArticleList,但这个方法是读请求,走的是从库。
5)如果出现主库和从库同步延迟,就出现了不一致。
这样用户就看不到他刚刚提交保存的文章,这个用户是接受不了的。那我们怎么解决?
方案三:客户端保存法
这个方案是:一些业务的操作是有前端页面的,不管是网页或App等。此方案的思路就是把之前保存的文章缓存到客户端,在用户到文章列表时,数据的组成就是(客户端缓存文章 + 后端读库返回的文章数据)。客户端要做的就是缓存要设置一个时间(这个缓存时间,可以预估主库同步到从库的时间延迟);以及要做文章去重,防止读库已经同步完成,客户端缓存没有过期。
问题:客户端逻辑复杂;客户端有缓存数据大小的限制,不能保存大数据。列表分页处理复杂。
方案四:缓存标记法
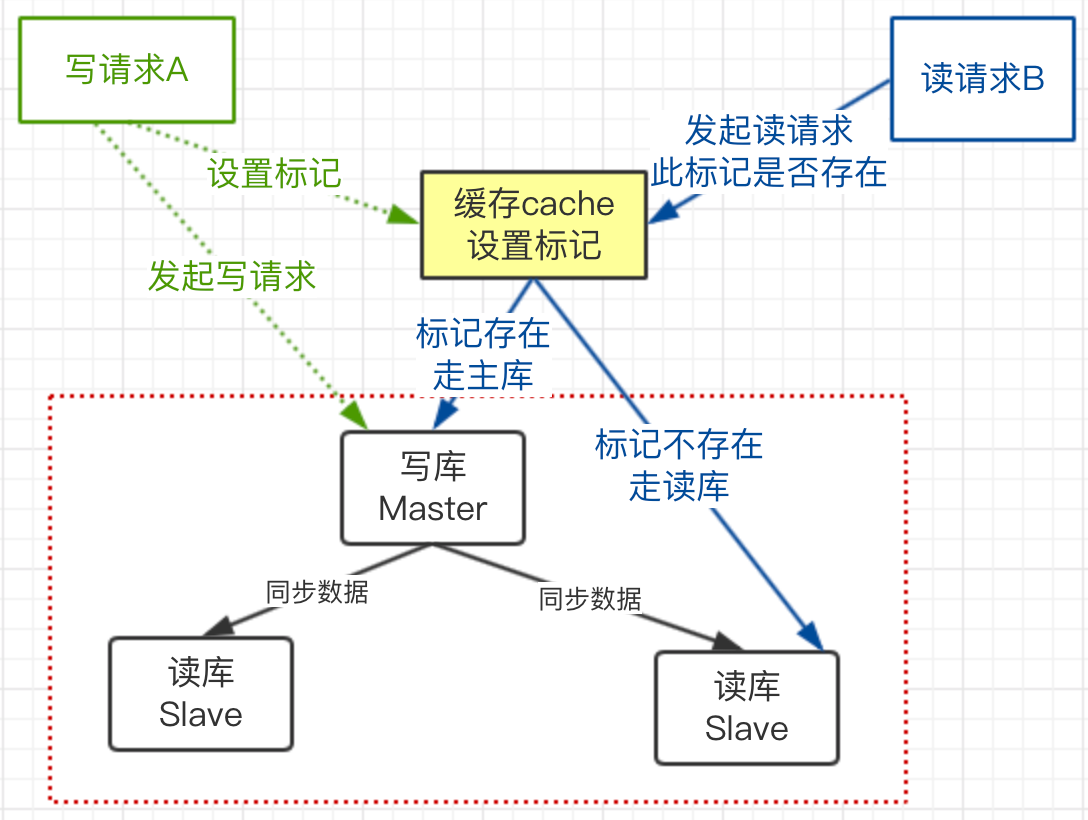
上图流程:
1)A发起写请求,更新了主库,但在缓存中设置一个标记,代表此数据已经更新,标记格式(业务代号:数据库:表:主键ID)根据自己业务场景。
2)设置此标记,要加上过期时间,可以为预估的主库和从库同步延迟的时间
3)B发起读请求的时候,先判断此请求的业务在缓存中有没有更新标记
4)如果存在标记,走主库;如果没有走从库。
这个方案就有效了解决了数据不一致的问题。
但这个方案会有个严重的问题,也就是每次的读请求都要到缓存中去判断是否存在缓存标记,如果是单机部署用的是jvm缓存,对性能还好;但如果是集群部署缓存肯定用redis,每次读都要和redis进行交互,这样肯定会影响系统吞吐量。
那怎么办?怎么办?继续往下看
方案五:本地缓存标记
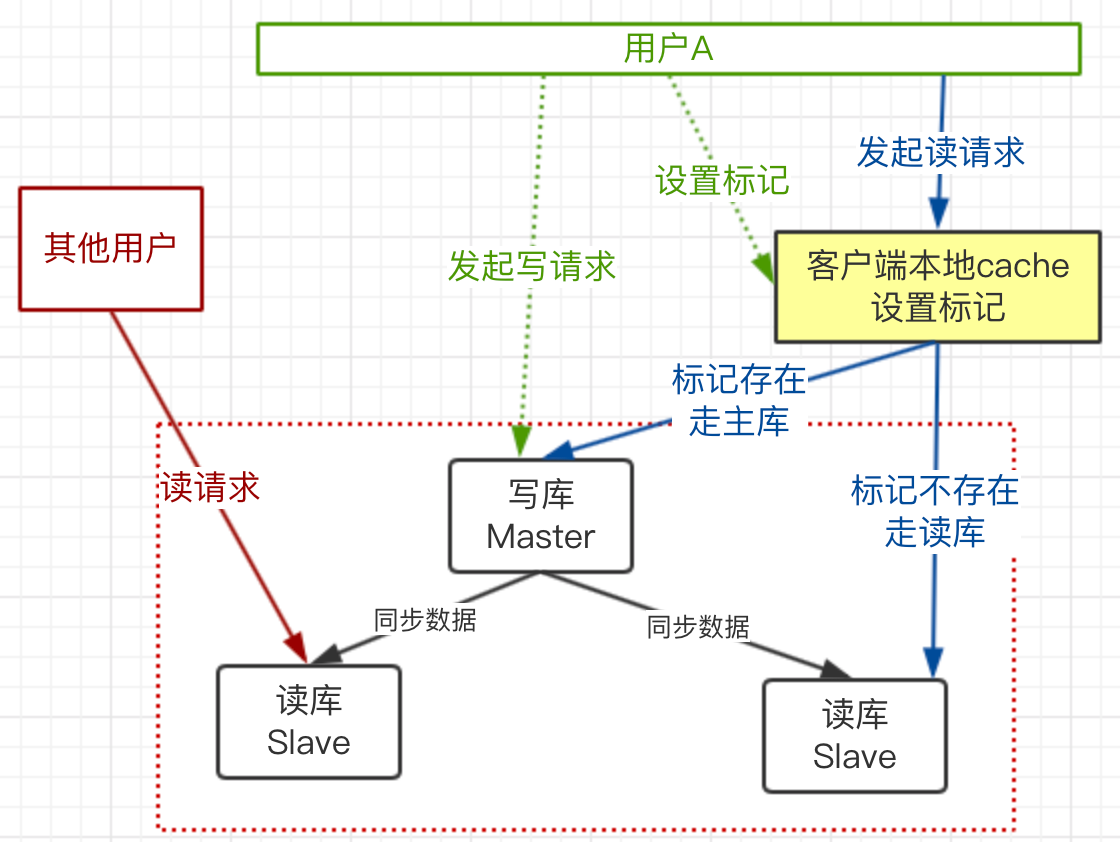
上图流程:
1)用户A发起写请求,更新了主库,并在客户端设置标记,过期时间,如:cookies
2)用户A再发起读请求时,带上这个本地标记在后端
3)后端在处理请求时,获取请求传过来的数据,看有没有这个标记(如:cookies)
4)有这个业务标记,走主库;没有走从库。
这个方案就保证了用户A的读请求肯定是数据一致的,而且没有性能问题,因为标记是本地客户端传过去的。
但有写小伙伴就会问那其他用户在本地客户端是没有这个标记的,他们走的就是从库了。那其他用户不就看不到这个数据了吗?说的对,其他用户是看不到,但看不到的时间很短,过个1~10秒就能够看到。
但这个方案解决了当前用户的数据一致性的问题,如上面举的例子,写文章,然后到文章列表,本用户是能够看到的。其他用户暂时看不到是没有关系的。还是那句话,脱离业务的方案是耍流氓。(推荐)
那DB读写分离情况下,如何解决缓存和数据库不一致性问题呢?请看这一篇:DB读写分离情况下,如何解决缓存和数据库不一致性问题?
总结:大家应该按照自己不同的业务场景,选择不同的方案;方案各有千秋,具体看业务场景
怎么解决DB读写分离,导致数据不一致问题?的更多相关文章
- 在应用层通过spring特性解决数据库读写分离
如何配置mysql数据库的主从? 单机配置mysql主从:http://my.oschina.net/god/blog/496 常见的解决数据库读写分离有两种方案 1.应用层 http://neore ...
- (转)使用Amoeba 实现MySQL DB 读写分离
Amoeba(变形虫)项目是一个开源框架,于2008年开始发布一款 Amoeba for Mysql软件: 这个软件致力于MySQL的分布式数据库前端代理层,它主要在应用层访问MySQL的时候充当SQ ...
- 使用Amoeba 实现MySQL DB 读写分离
Amoeba(变形虫)项目是一个开源框架,于2008年开始发布一款 Amoeba for Mysql软件: 这个软件致力于MySQL的分布式数据库前端代理层,它主要在应用层访问MySQL的时候充当SQ ...
- Redis面试题记录--缓存双写情况下导致数据不一致问题
转载自:https://blog.csdn.net/lzhcoder/article/details/79469123 https://blog.csdn.net/u013374645/article ...
- 使用Spring AOP切面解决数据库读写分离
http://blog.jobbole.com/103496/ 为了减轻数据库的压力,一般会使用数据库主从(master/slave)的方式,但是这种方式会给应用程序带来一定的麻烦,比如说,应用程序如 ...
- pt-osc改表导致数据不一致案例分析
2016-06-10 李丹 dba流浪猫 我们平时除了解决自己问题外,有时候也会协助圈内人士,进行一些故障排查,此案例就是帮某公司DBA进行的故障分析,因为比较典型,特分享一下,但仅仅是分享发生的过程 ...
- MongoDb的“not master and slaveok=false”错误及解决方法,读写分离
首先这是正常的,因为SECONDARY是不允许读写的, 在写多读少的应用中,使用Replica Sets来实现读写分离.通过在连接时指定或者在主库指定slaveOk,由Secondary来分担读的压力 ...
- 演示stop暴力停止线程导致数据不一致的问题,但是有些有趣的发现 (2017-07-03 21:25)
如注释所言 /** * Created by weiwei22 on 17/7/3. * * 这里主要是为了演示stop导致的数据不一致的问题.stop会暴力的结束线程并释放锁,所以有可能在恰好写了一 ...
- Codeigniter开发技巧:连接多个数据库(可实现DB读写分离)
在开发中,我们有时候会遇到在同一程序中链接多个数据库的需求,这对Codeigniter框架来说是很简单的,我们只需要在 database.php文件中配置少许参数即可. 默认情况下,CI配置的是链接一 ...
- 解决Redis中数据不一致问题
redis系列之数据库与缓存数据一致性解决方案 数据库与缓存读写模式策略写完数据库后是否需要马上更新缓存还是直接删除缓存? (1).如果写数据库的值与更新到缓存值是一样的,不需要经过任何的计算,可以马 ...
随机推荐
- Qt/C++音视频开发49-多级连保存和推流设计(同时保存到多个文件/推流到多个平台)
一.前言 近期遇到个用户需要多级联的保存和推流,在ffmpegsave多线程保存类中实现这个功能,越简单越好,就是在推流的同时,能够开启自动转储功能,一边推流的同时一边录像保存到本地视频文件.最初设想 ...
- Qt编写可视化大屏电子看板系统26-模块4模具进度
一.前言 模具进度主要用来展示不同的模具类别加工进度,表格的形式展示,显示内容包括模具编号.版本号.类型.状态.产品名称.计划交期.当前进度,其中进度条采用自定义控件三态进度条,有三种状态显示进度:右 ...
- Qt项目升级到Qt6经验总结
1 直观总结 增加了很多轮子,同时原有模块拆分的也更细致,估计为了方便拓展个管理. 把一些过度封装的东西移除了(比如同样的功能有多个函数),保证了只有一个函数执行该功能. 把一些Qt5中兼容Qt4的方 ...
- 由于OpenCV的#include <opencv2/opencv.hpp>文件没有放在所有的头文件之前所引起的编译时提示很多错误,如:filesystem.hpp(11,12): error C2144: 语法错误:“bool”的前面应有“;”error C4430: 缺少类型说明符 - 假定为 int。注意: C++ 不支持默认 int等
现象描述: 由于OpenCV的#include <opencv2/opencv.hpp>文件没有放在所有的其他OpenCV头文件之前所引起的编译时提示很多错误,如:filesystem.h ...
- Intellij IDEA部署Web项目到tomcat时提示:Error:Cannot build Artifact ':war exploded' because it is included into a circul
在Idea中使用Maven创建父子工程,第一个Model的那个项目可以很好的运行,在创建一个Model运行时报这个错.原因是tomcat部署了多个Web项目,可能最开始是两个项目的配置文件混用用,最后 ...
- shell脚本输出带文本颜色背景颜色自定义样式格式内容
shell脚本中 echo 和 printf 都可以输出内容.示例1: echo -e "\033[43;35m david use echo say Hello World \033[0m ...
- 转载:大模型所需 GPU 内存笔记
转载文章:大模型所需 GPU 内存笔记 引言 在运行大型模型时,不仅需要考虑计算能力,还需要关注所用内存和 GPU 的适配情况.这不仅影响 GPU 推理大型模型的能力,还决定了在训练集群中总可用的 G ...
- SQL Server与ORACLE数据库存储过程编写的几个不同之处
一直在使用SQL Server数库的存储过程进行业务数据处理,现在ORACLE上进行存储过程应用,感觉没有MSSQL的方便灵活,总结了以下几点区别: 1.入参数据类型不要书写长度.比如:userNam ...
- 玩转云端 | 拥有HBlock这项“存储盘活绝技”,数据中心也能“热辣瘦身”!
夏天马上就要到了,"瘦身"不光是特定人群的需求,也是数据中心的需求.构建轻量化.低碳化.高性价比的新型数据中心,更有效地支撑经济社会数字化转型,已成为业界主流趋势. 如何让数据中心 ...
- Python代码覆盖率工具之Coverage
Python代码覆盖率工具之Coverage 在软件开发过程中,确保代码覆盖率是质量控制的关键一环.通过测量代码覆盖率,开发者可以了解哪些部分的代码正在被测试执行,哪些部分尚未被覆盖,从而优化测试策略 ...