手把手教你用Python爬虫煎蛋妹纸海量图片
我们的目标是用爬虫来干一件略污事情
最近听说煎蛋上有好多可爱的妹子,而且爬虫从妹子图抓起练手最好,毕竟动力大嘛。而且现在网络上的妹子很黄很暴力,一下接受太多容易营养不量,但是本着有人身体就比较好的套路,特意分享下用点简单的技术去获取资源。
以后如果有机会,再给大家说说日本爱情动(大)作(雾)片的种子搜索爬取,多多关注。

请先准备
作案工具
我们只准备最简单的
python 2.7.11
Google Chrome
安装的时候记得把pip带上,这样可以方便我们安装一些好用的包,来方便我们干坏事(学习)的过程。
需要用到的包
包括更佳符合人类的HTTP库–requests
用来解析html文件,快速提取我们需要的内容–beautifulsoup4
也可以用下面的命令快速安装
pip install requests
pip install beautifulsoup4
干正事
从一次正常需求说起
每天在互联网上冲来冲去,浏览着大量的信息,观看这各种鼻血喷发的图片,于是作为新时代青年的我们,怎么能忍受被这些大量的垃圾信息充斥的互联网,我们要反抗,我们要下载!
请,看,下,图
↓

当你在网上冲浪的时候遇到这样的图片,我就问你:
虐不虐?虐死了!
下不下?下!
开始吧
获取图片的CSS选择器的规则
首先,我们需要定位我们需要的图片
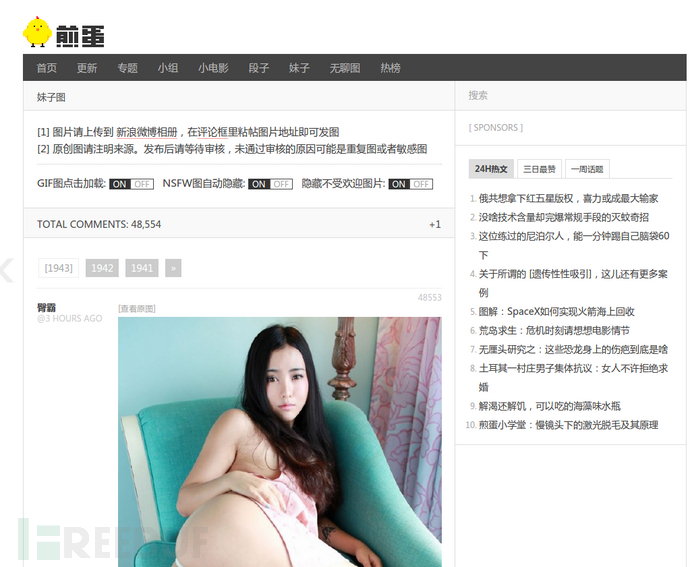
根据我们之前的准备的作案工具,使用chrome来访问网页http://jandan.net/ooxx
然后打开开发者工具菜单 -> 更多工具 -> 开发者工具
看下图右边的神器
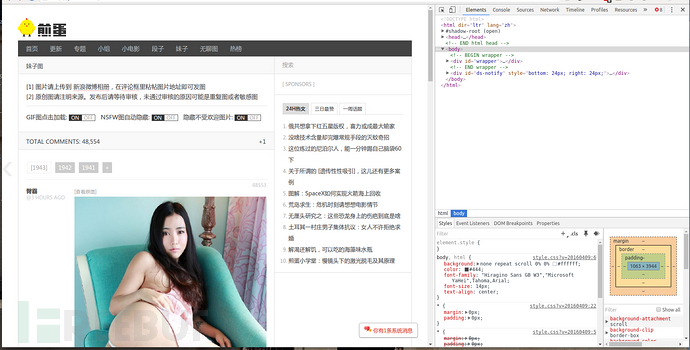
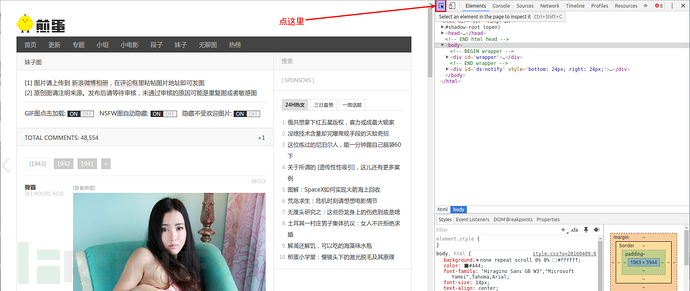
点击这个图标会出现块选择器,
鼠标移动我们感兴趣的部分
按照图片指示点击区域
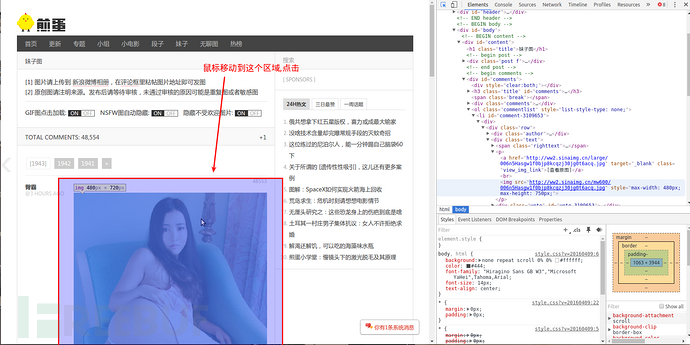
右边神器中就会出现我们所需要的img标签
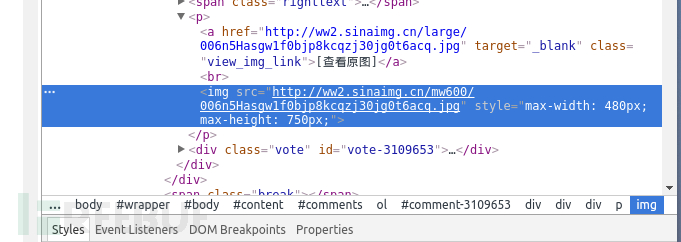
查看之前最后一个以#comments开头的标签,
它包含了所有img的子标签。
下面让我们来一些
神秘的事
打开cmd或者终端
输入python
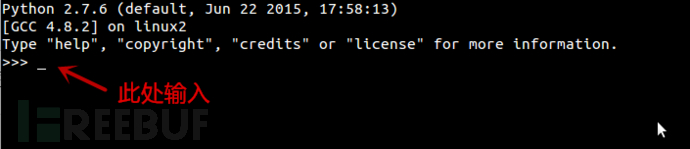
输入以下神秘代码
import requests
from bs4 import BeautifulSoup
res = requests.get('http://jandan.net/ooxx')
html = BeautifulSoup(res.text)
for index, each in enumerate(html.select('#comments img')):
with open('{}.jpg'.format(index), 'wb') as jpg:
jpg.write(requests.get(each.attrs['src'], stream=True).content)
现在偷偷看一下你的当前目录
是不是有很多(污)的图片
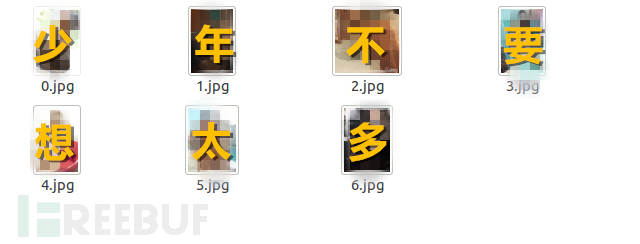
咳咳是这样的
↓
名词解释
网络爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
爬虫的使用对很多工作都是很有用的,但是对一般的社区,也需要付出代价。使用爬虫的代价包括:
网络资源:在很长一段时间,爬虫使用相当的带宽高度并行地工作。
服务器超载:尤其是对给定服务器的访问过高时。
质量糟糕的爬虫,可能导致服务器或者路由器瘫痪,或者会尝试下载自己无法处理的页面。
个人爬虫,如果过多的人使用,可能导致网络或者服务器阻塞。
适用场景
1 为您的应用系统等检测“机器人”数据流量
2 为您的业务系统提供恶意IP、手机号码数据,为恶意注册、登录、交易、刷单、黄牛等场景提供数据支持
3 为企业内部风控部门提供多纬度、分场景、更及时、全局联防的底层数据支撑
4 对恶意爬虫(爬取企业核心数据等)多纬度数据支撑
5 其他……
是不是还不够
行踪不定的下期预告
看着上面规整的排版——前后有序、图文并茂,不就是练手爬虫技术最好的机会吗?今天就到这里了,读取下一页什么的就靠你自己探索,我将会在下个系列给你一个参考方法,希望你持续关注。
手把手教你用Python爬虫煎蛋妹纸海量图片的更多相关文章
- [Python爬虫]煎蛋网OOXX妹子图爬虫(1)——解密图片地址
之前在鱼C论坛的时候,看到很多人都在用Python写爬虫爬煎蛋网的妹子图,当时我也写过,爬了很多的妹子图片.后来煎蛋网把妹子图的网页改进了,对图片的地址进行了加密,所以论坛里面的人经常有人问怎么请求的 ...
- python 爬虫煎蛋网
import urllib.request import os from urllib import error import re import base64 def url_open(url): ...
- python爬煎蛋妹子图
# python3 # jiandan meizi tu import urllib import urllib.request as req import os import time import ...
- [原创]手把手教你写网络爬虫(4):Scrapy入门
手把手教你写网络爬虫(4) 作者:拓海 摘要:从零开始写爬虫,初学者的速成指南! 封面: 上期我们理性的分析了为什么要学习Scrapy,理由只有一个,那就是免费,一分钱都不用花! 咦?怎么有人扔西红柿 ...
- [原创]手把手教你写网络爬虫(5):PhantomJS实战
手把手教你写网络爬虫(5) 作者:拓海 摘要:从零开始写爬虫,初学者的速成指南! 封面: 大家好!从今天开始,我要与大家一起打造一个属于我们自己的分布式爬虫平台,同时也会对涉及到的技术进行详细介绍.大 ...
- [原创]手把手教你写网络爬虫(7):URL去重
手把手教你写网络爬虫(7) 作者:拓海 摘要:从零开始写爬虫,初学者的速成指南! 封面: 本期我们来聊聊URL去重那些事儿.以前我们曾使用Python的字典来保存抓取过的URL,目的是将重复抓取的UR ...
- 手把手教你使用Python爬取西刺代理数据(下篇)
/1 前言/ 前几天小编发布了手把手教你使用Python爬取西次代理数据(上篇),木有赶上车的小伙伴,可以戳进去看看.今天小编带大家进行网页结构的分析以及网页数据的提取,具体步骤如下. /2 首页分析 ...
- [Java]使用HttpClient实现一个简单爬虫,抓取煎蛋妹子图
第一篇文章,就从一个简单爬虫开始吧. 这只虫子的功能很简单,抓取到”煎蛋网xxoo”网页(http://jandan.net/ooxx/page-1537),解析出其中的妹子图,保存至本地. 先放结果 ...
- 手把手教你吧Python应用到实际开发 不再空谈悟法☝☝☝
手把手教你吧Python应用到实际开发 不再空谈悟法☝☝☝ 想用python做机器学习吗,是不是在为从哪开始挠头?这里我假定你是新手,这篇文章里咱们一起用Python完成第一个机器学习项目.我会手把手 ...
随机推荐
- Visual Studio命令窗口
命令”窗口用于直接在 Visual Studio 集成开发环境 (IDE) 中执行命令或别名.可以执行菜单命令和不在任何菜单上显示的命令.若要显示“命令”窗口,请从“视图”菜单中选择“其他窗口”,再选 ...
- Coding the Matrix (3):矩阵
1. 矩阵与映射 矩阵和映射包含两方面的关系: 简单:已知矩阵 M, 从向量 x 映射到 M * x. (注:矩阵与行向量的点乘) 稍微复杂:已知映射 x ->M * x, 求矩阵 M. 第一种 ...
- 序列化和反序列化的几种方式(DataContractSerializer)(二)
DataContractSerializer 类 使用提供的数据协定,将类型实例序列化和反序列化为 XML 流或文档. 无法继承此类. 命名空间: System.Runtime.Serializati ...
- [设计模式] javascript 之 抽象工厂模式
抽象工厂模式说明 1. 工厂方法模式的问题: 在工厂方法模式里,创建类都需要通过 工厂类,如果要扩展程序,就必须修改工厂类,这违背了闭包原则,对扩展开放,对修改关闭:对于设计有一定的问题. 2. 如何 ...
- Nodejs学习笔记(五)--- Express安装入门与模版引擎ejs
目录 前言 Express简介和安装 运行第一个基于express框架的Web 模版引擎 ejs express项目结构 express项目分析 app.set(name,value) app.use ...
- CSS3媒体查询
随着响应式设计模型的诞生,Web网站又要发生翻天腹地的改革浪潮,可能有些人会觉得在国内IE6用户居高不下的情况下,这些新的技术还不会广泛的蔓延下去,那你就错了,如今淘宝,凡客,携程等等公司都已经在大胆 ...
- 旅行(Dijkstra)问题
问题:输入: 输入数据有多组,每组的第一行是三个整数T,S和D,表示有T条路,和草儿家相邻的城市的有S个,草儿想去的地方有D个: 接着有T行,每行有三个整数a,b,time,表示a,b城市之间的车 ...
- bzoj 1193 贪心
如果两点的曼哈顿距离在一定范围内时我们直接暴力搜索就可以得到答案,那么开始贪心的跳,判断两点横纵坐标的差值,差值大的方向条2,小的条1,不断做,直到曼哈顿距离较小时可以暴力求解. 备注:开始想的是确定 ...
- codevs1500 后缀排序
题目描述 Description 天凯是MIT的新生.Prof. HandsomeG给了他一个长度为n的由小写字母构成的字符串,要求他把该字符串的n个后缀(suffix)从小到大排序. 何谓后缀?假设 ...
- PL/0编译器(java version)–Praser.java
1: package compiler; 2: 3: import java.io.IOException; 4: import java.util.BitSet; 5: 6: /** 7: ...