SQL Server如何提高数据库备份的速度
对于一个数据库完整备份来说,备份的速度很大程度上取决于下面两个因素:读磁盘数据、日志文件的吞吐量,写磁盘数据文件的吞吐量。
下图是备份过程中磁盘的变化情况:
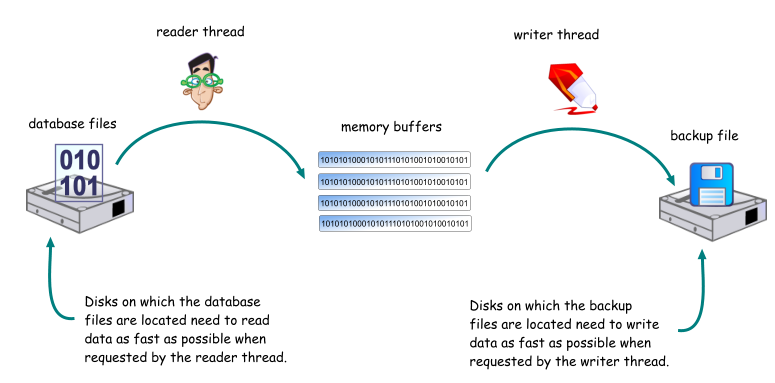
读吞吐量
读吞吐量的大小取决于磁盘读取数据的速度,而磁盘读取的速度又取决于数据文件在磁盘中的位置。因此,位于不同盘符上不同数据库文件的读取速度都不相同。
测量读吞吐量的一个方法就是进行一次数据库完整备份,然后使用Windows性能监控器(perfmon)来监控数据库文件所在磁盘的Read bytes/sec 性能计数器。保存备份文件的磁盘应该在物理上区别于数据库文件所在的磁盘,否则测量精度会不准确。当然备份同时也应该会有另外一些来自系统或是其他应用程序对磁盘的读取操作。
注意:如果你使用完整备份来监测磁盘读写吞吐量的话,那么这个测试用的备份文件应该和其他常规备份放在一起,以便恢复时使用。也就是说,如果你在测试备份文件之后又进行了常规差异备份,那么这些差异备份就会以这个测试备份为还原的起始点。
假设数据库所有文件的大小都是相等的,那么你获取的最小测量值就是你指定数据库在系统中最大的备份吞吐量了。
另一个测量读吞吐量的方法是在NUL设备上执行备份,如下:
BACKUP DATABASE AdventureWorks TO DISK = 'NUL' WITH COPY_ONLY
注意我们使用了COPY_ONLY选项,这个选项仅仅在SQL Server 2005及以上版本中才提供。你可以在SQL Server2000上执行相同的备份,只是要忽略这个选项,但是一定要小心。因为备份到NUL设备也会被认为是一个有效备份,这就意味着当你执行备份到NUL设备后,你后续的所有差异备份都将不可用,除非你在执行备份到NUL设备后,再执行一次常规的数据库完整备份。假如你执行事务日志备份到NUL设备,那么你将破坏日志恢复链,导致后续事务日志备份不可用。
如果你必须在SQL Server 2000上执行备份到NUL设备的话,一定要做好备灾恢复的准备。
假设我现在已经测量出我的AdventureWorks读吞吐量为46MB/sec。这就是说,46MB/sec是最大的备份吞吐量了,也是我的磁盘能提供给SQL Server备份读线程最快的速度了。那我们如何提高这个速度呢?使用更快的磁盘肯定是一种方法。另外的方法就是把数据库文件分散到多个物理磁盘上,以便于在读数据时可以同步创建多个读线程。减小数据库文件的碎片级别也可以提高吞吐量,特别是当数据库文件有大量碎片存在时。
写吞吐量
现在开始说说写吞吐量。执行一个文件备份,在我的系统中,我得到了如下的结果:
BACKUP DATABASE successfully processed 7529 pages in 3.300 seconds (18.688 MB/sec).
上面的结果表明写吞吐量在这里成为了瓶颈。我的磁盘可以提供46MB/sec的数据,但是写速度仅为18.688MB/sec。实际上,我把备份文件放在了同数据文件相同的磁盘上,当我把备份文件放在不同的物理磁盘上时,我得到如下的结果:
BACKUP DATABASE successfully processed 7529 pages in 1.421 seconds (43.399 MB/sec).
上面的结果已经好很多了。现在读写速度都取决于磁盘了,整体的吞吐量已经明显提高了。所以把备份文件放到不同的物理磁盘上就是一种提高写吞吐量的方法。另一个方法就是把备份分散成不同的文件。如果磁盘可以控制它的话,那么文件可以位于相同的物理磁盘上。如果不能,你最好把文件分散到不同的物理磁盘上。使用更快的磁盘存储备份文件是另一个好的选择。
然而,让我们回到第一步,再看看那个整体图。想一想备份吞吐量的第一步是读吞吐量。也就是说即使你的写吞吐量达到150MB/sec,但是如果读吞吐量只有46MB/sec的话,也无济于事,你能获得的最大备份吞吐量还是46MB/sec。
总结
首先我们总结一下我们都做了什么:
我们测量了读吞吐量为46MB/sec,我们讨论了如下方法来提高这个数值:
- 使用更快的磁盘。
- 把多个数据库文件存储在不同的物理磁盘上
- 减少数据库文件碎片级别
我们在数据库文件所在磁盘执行了备份执行,备份吞吐务为18MB/sec。很糟的速度,我们知道读吞吐量为46MB/sec,所以我们把目标放到了写吞吐量上。然后,我们把备份文件放到了与数据库文件不同的物理磁盘上。备份吞吐量为43MB/sec。速度不错。我也还可以提高这一数值吗?看起来好像是不行了。但是如果我们的写吞吐量仅仅为25MB/sec的话,我们还可以从以下几方面来考虑:
- 使用更快的磁盘进行备份
- 把备份文件分割成多个文件(在相同或不同的物理磁盘上,这取决于磁盘的吞吐量)
- 使用备份压缩工具。假如压缩速度非常好的话,那么就会减少写到磁盘上的数据量,从而加大写吞吐量。一般情况执行这种压缩程序都会消耗大量的CPU资源
补充说明
为了获得最好的备份吞吐量,下面这几点在最开始创建数据库时就应该考虑到。实际上,下面这几点也同样适用于提高你数据库的应用性能。
- 磁盘速度:使用最快的磁盘或是在预算允许的前提下进行磁盘配置来提高备份吞吐量。
- 数据库文件:把数据库文件分散到多个物理磁盘上,以便于SQL Server使用多个读线程去每个磁盘上读取数据。对比单数据文件的数据库存储来讲,多数据文件可以在很短时间内完成数据的读取。
- 使用不同的物理磁盘:SQL Server的读线程数量是基于你数据库文件所在的盘符数量的。然而,假如你的盘符是相同物理磁盘上的分区,而且你的磁盘不能满足读线程的读取要求时,你的备份吞吐量将会很差。
- 文件碎片:创建数据时指定的数据库的初始大小就相当于指定的数据库减少文件碎片的期望最大值。假如数据库文件被设置为自动增长,且设置了一个最大增长值的话,这样也要有助于减小碎片。
- 有计划的存储你的事务日志到独立的磁盘中:把你的事务日志文件存储在独立于数据库文件的磁盘中,甚至独立于操作系统或是其他经常使用I/O的应用程序,有助于在执行事务日志备份时提高读写吞吐量。事务日志的磁盘的I/O操作是自然相连的,而不是数据文件I/O那种随机的操作。把事务日志文件同数据文件放在同一个盘上的话,当数据库忙碌时,会使事务日志备份变慢。
- 有计划的存储你的备份到独立的磁盘中:把你的备份文件存储在独立于数据库文件的磁盘中,甚至独立于操作系统或是其他经常使用I/O的应用程序,有助于提高写吞吐量。
获取备份速度数据
你可以从msdb..backupset表中获取备份速度数据。backup_start_date,backup_finish_date和backup_size列提供了计算备份速度所需的所有数据细节信息。注意备份大小不是定义数据库大小所必需的,因为SQL Server 2005不备份包括已被删除数据的数据页。具体细节请参见article。
下面的脚本可以显示出你所有数据库的备份时间:
SELECT database_name, backup_start_date, CAST(CAST((backup_size / (DATEDIFF(ss, backup_start_date, backup_finish_date))) / (1024 * 1024) AS NUMERIC(8, 3)) AS VARCHAR(16)) + ' MB/sec' speed
FROM msdb..backupset
ORDER BY database_name, backup_start_date
SQL Server如何提高数据库备份的速度的更多相关文章
- SQL Server 维护计划实现数据库备份(策略实战)
一.背景 之前写过一篇关于备份的文章:SQL Server 维护计划实现数据库备份,上面文章使用完整备份和差异备份基本上能解决数据库备份的问题,但是为了保障数据更加安全,我们需要再次完善我们的备份计划 ...
- SQL Server 维护计划实现数据库备份(Step by Step)(转)
SQL Server 维护计划实现数据库备份(Step by Step) 一.前言 SQL Server 备份和还原全攻略,里面包括了通过SSMS操作还原各种备份文件的图形指导,SQL Server ...
- SQL Server 维护计划实现数据库备份(Step by Step)
转自:http://www.cnblogs.com/gaizai/archive/2011/11/18/2254445.html 一.前言 SQL Server 备份和还原全攻略,里面包括了通过SSM ...
- SQL Server 2012将数据库备份到网络中的共享文件夹
把计算机computer1 中的数据库备份到计算机computer2(IP:192.168.0.130)中的一个共享文件夹下 在computer2中的F盘下建一个共享文件夹叫DBBackupShare ...
- Microsoft SQL Server 2008 R2数据库备份 - 人工备份
业务介绍 数据库人工备份是指由相关管理人员通过主动的手工方式备份数据库文件.在一些特殊的时间节点,如重要资料的录入完成.软硬件环境更新前等需要特别关注数据库安全的时候,一定要进行数据库的人工备份,以保 ...
- SQL Server 维护计划(数据库备份)
公司的项目都需要定期备份,程序备份关掉iis站点复制文件就可以了,难受的地方就是数据库的备份了.服务器上装的大都是英文版,一看见英文,操作都变得小心翼翼起来,生怕哪里搞错,第二天就要被安排写辞职申请了 ...
- 【数据库-Azure SQL Database】SQL Server 如何将数据库备份到 Azure Storage
打开本地的 SQL Server Management Studio.首先创建 Credentials.命令如下: IF NOT EXISTS (SELECT * FROM sys.credent ...
- SQL Server 2008怎么自动备份数据库
在SQL Server 2008数据库中.为了防止数据的丢失我们就需要按时的来备份数据库了.要是每天都要备份的话,人工备份会很麻烦的,自动备份的话就不需要那么麻烦了,只 要设置好了,数据库就会自动在你 ...
- 【SQL Server高可用性】数据库复制:SQL Server 2008R2中通过数据库复制,把A表的数据复制到B表
原文:[SQL Server高可用性]数据库复制:SQL Server 2008R2中通过数据库复制,把A表的数据复制到B表 经常在论坛中看到有人问数据同步的技术,如果只是同步少量的表,那么可以考虑使 ...
随机推荐
- apache的安装,启动和停止
一.apache服务器的安装 安装步骤直接傻瓜式进行安装.并没有太大的难点.apache的配置是学习的重点和难点. 安装好后再浏览器地址栏输入http://localhost.若能够成功安装,则会显示 ...
- linux 系统下开机自动启动oracle 监听和实例 (亲测有效)
[oracle@oracle11g ~]$ dbstartORACLE_HOME_LISTNER is not SET, unable to auto-start Oracle Net Listene ...
- NET Framework 4.0的安装失败处理
如果是XP系统,这么做:1.开始——运行——输入cmd——回车——在打开的窗口中输入net stop WuAuServ2.开始——运行——输入%windir%3.在打开的窗口中有个文件夹叫Softwa ...
- FreeMarker与Spring MVC的结合应用
Freemarker是一种基于java的模板引擎.SpringMVC对FreeMarker进行一些配置的支持,能够利用Freemarker只关注表现层以及Spring MVC的三层分离的特点,向前端输 ...
- step by step 之餐饮管理系统五(Util模块)------附上篇日志模块源码
这段时间一直在修改日志模块,现在基本上写好了,也把注释什么的都加上了,昨天邮件发送给mark的园友一直报失败,老是退回来,真是报歉,如下图所示:
- Maven + 最新SSM整合
. 1. 开发环境搭建 参考博文:Eclipse4.6(Neon) + Tomcat8 + MAVEN3.3.9 + SVN项目完整环境搭建 2. Maven Web项目创建 2.1. 2.2. 2. ...
- javascript基础知识-对象
javascript创建对象有三种方法: 1)对象直接量 例:var empty = {}; var point = {x:1,y:4}; var book = { "main title& ...
- Linq ExecuteQuery,ExecuteCommand
//连接语句 public readonly string sqlconn = ConfigurationManager.ConnectionStrings["Transaction_9_3 ...
- Linux下oracle11gR2系统安装到数据库建立配置及最后oracle的dmp文件导入一站式操作记录
简介 之前也在linux下安装过oralce,可每次都是迷迷糊糊的,因为大脑一片空白,网上随便看见一个文档就直接复制,最后搞了乱七八糟,虽然装上了,却乱得很,现在记录下来,希望能给其他网上朋友遇到问题 ...
- 理解 Soap
http://www.cnblogs.com/yhuang/archive/2012/04/04/share_storm.html 自己也写了下: using System; using System ...