nodejs爬虫
前言
几个月之前,有同事找我要PHP CI框架写的OA系统。他跟我说,他需要学习PHP CI框架,我建议他学习大牛写的国产优秀框架QeePHP。
我上QeePHP官网,发现官方网站打不开了,GOOGLE了一番,发现QeePHP框架已经没人维护了。API文档资料都没有了,那可怎么办?
毕竟QeePHP学习成本挺高的。GOOGLE时,我发现已经有人把文档整理好,放在自己的个人网站上了。我在想:万一放文档的个人站点也挂了,
怎么办?还是保存到自己的电脑上比较保险。于是就想着用NodeJS写个爬虫抓取需要的文档到本地。后来抓取完成之后,干脆写了一个通用版本的,
可以抓取任意网站的内容。
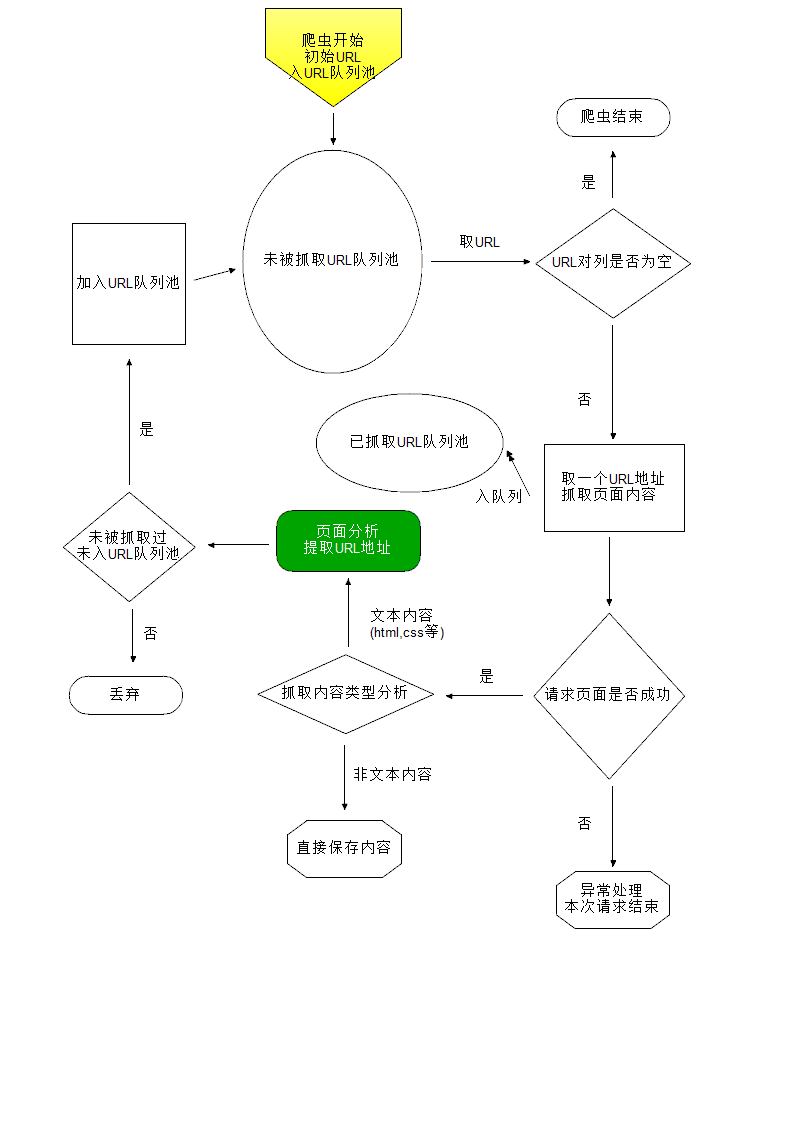
爬虫原理
抓取初始URL的页面内容,提取URL列表,放入URL队列中,
从URL队列中取一个URL地址,抓取这个URL地址的内容,提取URL列表,放入URL队列中
。。。。。。
。。。。。。
NodeJS实现源码
调用
|
1
2
3
4
5
6
7
8
9
|
var Robot = require("./robot.js");var oOptions = { domain:'baidu.com', //抓取网站的域名 saveDir:"E:\\wwwroot/baidu/", //抓取内容保存目录 debug:true, //是否开启调试模式};var o = new Robot(oOptions);o.crawl(); //开始抓取 |
后记
还有些地方需要完善
1.处理302跳转
2.处理COOKIE登陆
3.大文件偶尔会非正常退出
4.使用多进程
5.完善URL队列管理
6.异常退出之后处理
实现过程中碰到了一些问题,最后还是解决了,
爬虫原理很简单,只有真正实现过,才会对它更加理解,
原来实现不是那么简单,也是需要花时间的。
7.下载地址: https://codeload.github.com/wadeyu/nodejsrobot/zip/master
转自:http://www.cnblogs.com/wadeyu/archive/2015/07/10/4636170.html
nodejs爬虫的更多相关文章
- NodeJS 爬虫爬取LOL英雄联盟的英雄信息,批量下载英雄壁纸
工欲善其事,必先利其器,会用各种模块非常重要. 1.模块使用 (1)superagent:Nodejs中的http请求库(每个语言都有无数个,java的okhttp,OC的afnetworking) ...
- Nodejs爬虫进阶教程之异步并发控制
Nodejs爬虫进阶教程之异步并发控制 之前写了个现在看来很不完美的小爬虫,很多地方没有处理好,比如说在知乎点开一个问题的时候,它的所有回答并不是全部加载好了的,当你拉到回答的尾部时,点击加载更多,回 ...
- NodeJS爬虫系统初探
NodeJS爬虫系统 NodeJS爬虫系统 0. 概论 爬虫是一种自动获取网页内容的程序.是搜索引擎的重要组成部分,因此搜索引擎优化很大程度上是针对爬虫而做出的优化. robots.txt是一个文本文 ...
- nodejs爬虫——汽车之家所有车型数据
应用介绍 项目Github地址:https://github.com/iNuanfeng/node-spider/ nodejs爬虫,爬取汽车之家(http://www.autohome.com.cn ...
- nodejs爬虫笔记(三)---爬取YouTube网站上的视频信息
思路:通过笔记(二)中代理的设置,已经可以对YouTube的信息进行爬取了,这几天想着爬取网站下的视频信息.通过分析YouTube,发现可以从订阅号入手,先选择几个订阅号,然后爬取订阅号里面的视频分类 ...
- nodejs爬虫笔记(二)---代理设置
node爬虫代理设置 最近想爬取YouTube上面的视频信息,利用nodejs爬虫笔记(一)的方法,代码和错误如下 var request = require('request'); var chee ...
- 【nodeJS爬虫】前端爬虫系列
写这篇 blog 其实一开始我是拒绝的,因为爬虫爬的就是cnblog博客园.搞不好编辑看到了就把我的账号给封了:). 言归正传,前端同学可能向来对爬虫不是很感冒,觉得爬虫需要用偏后端的语言,诸如 ph ...
- 简单实现nodejs爬虫工具
约30行代码实现一个简单nodejs爬虫工具,定时抓取网页数据. 使用npm模块 request---简单http请求客户端.(轻量级) fs---nodejs文件模块. index.js var ...
- 第一个nodejs爬虫:爬取豆瓣电影图片
第一个nodejs爬虫:爬取豆瓣电影图片存入本地: 首先在命令行下 npm install request cheerio express -save; 代码: var http = require( ...
- nodejs爬虫如何设置动态ip以及userAgent
nodejs爬虫如何设置动态ip以及userAgent 转https://blog.csdn.net/u014374031/article/details/78833765 前言 在写nodejs爬虫 ...
随机推荐
- Windows 7下搭建Jmeter测试环境
jmeter配置.安装 一. 工具描述 apache jmeter是100%的java桌面应用程序,它被设计用来加载被测试软件功能特性.度量被测试软件的性能.设计jmeter的初衷是测试web应用,后 ...
- libyuv 编译 for android
libyuv is an open source project that includes is an instrumentation framework for building dynamic ...
- 最短路(Dijkstra) POJ 1062 昂贵的聘礼
题目传送门 /* 最短路:Dijkstra算法,首先依照等级差距枚举“删除”某些点,即used,然后分别从该点出发生成最短路 更新每个点的最短路的最小值 注意:国王的等级不一定是最高的:) */ #i ...
- android 蓝牙设备监听广播
蓝牙权限 <uses-permission android:name="android.permission.BLUETOOTH" /> 1.监听手机本身蓝牙状态的广播 ...
- BZOJ3825 : [Usaco2014 Nov]Marathon
不跳过任何点的路程=dis(l,l+1)+dis(l+1,l+2)+...+dis(r-2,r-1)+dis(r-1,r) 要跳过一个点i,则要最小化dis(i,i+2)-dis(i,i+1)-dis ...
- 转载关于KeyPress和KeyDown事件的区别和联系
KeyDown:在控件有焦点的情况下按下键时发生. KeyPress:在控件有焦点的情况下按下键时发生. KeyUp:在控件有焦点的情况下释放键时发生. 1.KeyPress主要用来接收字母.数字等A ...
- const放在函数前和放在函数后
template < class T, class container = vector<T> > class MyClass{ private: T value; publi ...
- 【BZOJ】2820: YY的GCD(莫比乌斯)
http://www.lydsy.com/JudgeOnline/problem.php?id=2820 此题非常神! 下文中均默认n<m 首先根据bzoj1101的推理,我们易得对于一个数d使 ...
- 关于Ruby的一些知识
1 -9/2 = -5 当进行一个除法运算的结果是一个负数的时候,由于Ruby采取向负无穷大圆整,所以结果是-5.而由于除数是个整数,所以结果也是一个整数.而其他语言多数是向0取整. 2 连接字符串建 ...
- NSString、NSMutableString基本用法
NSString其实是一个对象类型.NSString是NSObject(Cocoa Foundation的基础对象)的子类 一.NSString的创建 1.创建常量字符串.NSString *astr ...