Tensorflow实战第十课(RNN MNIST分类)
设置RNN的参数
我们本节采用RNN来进行分类的训练(classifiction)。会继续使用手写数据集MNIST。
让RNN从每张图片的第一行像素读到最后一行,然后进行分类判断。接下来我们导入MNIST数据并确定RNN的各种参数(hyper-parameters)
注:
参数(parameters)/参数模型
由模型通过学习得到变量,比如权重w,偏置b
超参数(hyper-parameters)/算法参数
根据经验设定,影响到权重w和偏置b的大小,比如迭代次数、隐藏层的层数、每层神经元的个数、学习速率等。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data #data
mnist = input_data.read_data_sets('MNIST_data',one_hot=True) #hyperparameters
lr = 0.001 #learing rate
training_iters = 100000 #train step 上限
batch_size = 128 n_inputs = 28 #mnist data input(img shape:28*28)
n_steps = 28 #time step
n_hidden_units = 128 #neurons in hidden layer
n_classes = 10 #mnist classes(0-9 digits)
接下来定义的是x,y的placeholder和weights,biases的初始状况
#tf graph input
x = tf.placeholder(tf.float32,[None,n_steps,n_inputs])
y = tf.placeholder(tf.float32,[None,n_classes]) #define weights & biases
weights = {
#(28,128)
'in': tf.Variable(tf.random_normal([n_inputs,n_hidden_units])),
#(128,10)
'out': tf.Variable(tf.random_normal([n_hidden_units,n_classes]))
}
biases = {
#(128,)
'in' : tf.Variable(tf.constant(0.1,shape=[n_hidden_units,])),
#(10,)
'out' : tf.Variable(tf.constant(0.1,shape=[n_classes,]))
}
定义RNN的主体结构
接着我们定义RNN主体结构,RNN共有3个组成部分(input_layer,cell,output_layer),首先我们定义input_layer:
#hidden layer for input to cell#
# 原始的 X 是 3 维数据, 我们需要把它变成 2 维数据才能使用 weights 的矩阵乘法
# X ==> (128 batches * 28 steps, 28 inputs)
X = tf.reshape(X,[-1,n_inputs]) #into hidden
#X_in = W*X + b
X_in = tf.matmul(X,weights['in'])+biases['in']
# X_in ==> (128 batches, 28 steps, 128 hidden) 换回3维
X_in = tf.reshape(X_in,[-1,n_steps,n_hidden_units])
接下来就是lstm_cell中的计算,有两种途径:
1.使用tf.nn.rnn(cell,inputs) 不推荐
2.使用tf.nndynamic_rnn(cell,inputs) 推荐
因 Tensorflow 版本升级原因,state_is_tuple = True将在之后的版本中变为默认. 对于LSTM来说,state可被分为(c_state,h_state)
#use basic lstm cell
lstm_cell = tf.contrib.rnn.BasicLSTMCell(n_hidden_units)
init_state = lstm_cell.zero_state(batch_size,dtype=tf.float32) #初始化为零
outputs, final_state = tf.nn.dynamic_rnn(lstm_cell, X_in,initial_state=init_state, time_major=False)
若使用tf.nn.dynamic_rnn(cell,inputs),我们要确定inputs的格式,tf.nn.dynamic_rnn中的time_major参数会针对不同的inputs格式有不同的值。
1.如果inputs为(batches,steps,inputs)==>time_major=False
2.如果inputs为(steps,batches,inputs)==>time_major=True
outputs, final_state = tf.nn.dynamic_rnn(lstm_cell, X_in, initial_state=init_state, time_major=False)
最后是output_layer和return的值,因为这个例子的特殊性,有两种方法可以求得results。
method 1:直接调用final_state中的h_state(final_states[1])来进行运算:
results = tf.matmul(final_state[1], weights['out']) + biases['out']
method 2:调用最后一个outputs(在这个例子中,和上面的final_states[1]是一样的):
# 把 outputs 变成 列表 [(batch, outputs)..] * steps
outputs = tf.unstack(tf.transpose(outputs, [1,0,2]))
results = tf.matmul(outputs[-1], weights['out']) + biases['out'] #选取最后一个 output
在def RNN()的最后输出results
return results
定义好了RNN主体结构后 我们就可以来计算cost 和 train_op:
pred = RNN(x, weights, biases)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(pred, y))
train_op = tf.train.AdamOptimizer(lr).minimize(cost)
训练RNN,不断输出accuracy观看结果:
correct_pred = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32)) with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
step = 0
while step * batch_size < training_iters:
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
batch_xs = batch_xs.reshape([batch_size, n_steps, n_inputs])
sess.run([train_op], feed_dict={
x: batch_xs,
y: batch_ys,
})
if step % 20 == 0:
print(sess.run(accuracy, feed_dict={
x: batch_xs,
y: batch_ys,
}))
step += 1
完整代码如下:
#RNN practice import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data #data
mnist = input_data.read_data_sets('MNIST_data',one_hot=True) #hyperparameters
lr = 0.001 #learing rate
training_iters = 100000 #train step 上限
batch_size = 128 n_inputs = 28 #mnist data input(img shape:28*28)
n_steps = 28 #time step
n_hidden_units = 128 #neurons in hidden layer
n_classes = 10 #mnist classes(0-9 digits) #tf graph input
x = tf.placeholder(tf.float32,[None,n_steps,n_inputs])
y = tf.placeholder(tf.float32,[None,n_classes]) #define weights & biases
weights = {
#(28,128)
'in': tf.Variable(tf.random_normal([n_inputs,n_hidden_units])),
#(128,10)
'out': tf.Variable(tf.random_normal([n_hidden_units,n_classes]))
}
biases = {
#(128,)
'in' : tf.Variable(tf.constant(0.1,shape=[n_hidden_units,])),
#(10,)
'out' : tf.Variable(tf.constant(0.1,shape=[n_classes,]))
} #define rnn
def RNN(X,weights,biases):
#hidden layer for input to cell#
# 原始的 X 是 3 维数据, 我们需要把它变成 2 维数据才能使用 weights 的矩阵乘法
# X ==> (128 batches * 28 steps, 28 inputs)
X = tf.reshape(X,[-1,n_inputs]) #into hidden
#X_in = W*X + b
X_in = tf.matmul(X,weights['in'])+biases['in']
# X_in ==> (128 batches, 28 steps, 128 hidden) 换回3维
X_in = tf.reshape(X_in,[-1,n_steps,n_hidden_units]) #use basic lstm cell
lstm_cell = tf.contrib.rnn.BasicLSTMCell(n_hidden_units)
init_state = lstm_cell.zero_state(batch_size,dtype=tf.float32) #初始化为零
outputs, final_state = tf.nn.dynamic_rnn(lstm_cell, X_in, initial_state=init_state, time_major=False) #hidden layer for output as the final results
outputs = tf.unstack(tf.transpose(outputs,[1,0,2]))
results = tf.matmul(outputs[-1],weights['out']+biases['out']) return results
pred = RNN(x, weights, biases)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=y))
train_op = tf.train.AdamOptimizer(lr).minimize(cost) correct_pred = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32)) with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
step = 0
while step * batch_size < training_iters:
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
batch_xs = batch_xs.reshape([batch_size, n_steps, n_inputs])
sess.run([train_op], feed_dict={
x: batch_xs,
y: batch_ys,
})
if step % 20 == 0:
print(sess.run(accuracy, feed_dict={
x: batch_xs,
y: batch_ys,
}))
step += 1
运行截图:
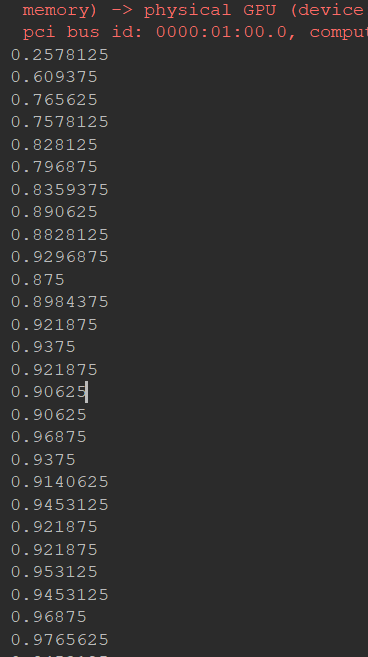
Tensorflow实战第十课(RNN MNIST分类)的更多相关文章
- TensorFlow实战第五课(MNIST手写数据集识别)
Tensorflow实现softmax regression识别手写数字 MNIST手写数字识别可以形象的描述为机器学习领域中的hello world. MNIST是一个非常简单的机器视觉数据集.它由 ...
- Tensorflow实战第十一课(RNN Regression 回归例子 )
本节我们会使用RNN来进行回归训练(Regression),会继续使用自己创建的sin曲线预测一条cos曲线. 首先我们需要先确定RNN的各种参数: import tensorflow as tf i ...
- TensorFlow实战第八课(卷积神经网络CNN)
首先我们来简单的了解一下什么是卷积神经网路(Convolutional Neural Network) 卷积神经网络是近些年逐步兴起的一种人工神经网络结构, 因为利用卷积神经网络在图像和语音识别方面能 ...
- TensorFlow实战第七课(dropout解决overfitting)
Dropout 解决 overfitting overfitting也被称为过度学习,过度拟合.他是机器学习中常见的问题. 图中的黑色曲线是正常模型,绿色曲线就是overfitting模型.尽管绿色曲 ...
- TensorFlow实战第六课(过拟合)
本节讲的是机器学习中出现的过拟合(overfitting)现象,以及解决过拟合的一些方法. 机器学习模型的自负又表现在哪些方面呢. 这里是一些数据. 如果要你画一条线来描述这些数据, 大多数人都会这么 ...
- TensorFlow实战第四课(tensorboard数据可视化)
tensorboard可视化工具 tensorboard是tensorflow的可视化工具,通过这个工具我们可以很清楚的看到整个神经网络的结构及框架. 通过之前展示的代码,我们进行修改从而展示其神经网 ...
- TensorFlow实战第三课(可视化、加速神经网络训练)
matplotlib可视化 构件图形 用散点图描述真实数据之间的关系(plt.ion()用于连续显示) # plot the real data fig = plt.figure() ax = fig ...
- 芝麻HTTP:TensorFlow LSTM MNIST分类
本节来介绍一下使用 RNN 的 LSTM 来做 MNIST 分类的方法,RNN 相比 CNN 来说,速度可能会慢,但可以节省更多的内存空间. 初始化 首先我们可以先初始化一些变量,如学习率.节点单元数 ...
- 深度学习原理与框架-Tensorflow卷积神经网络-神经网络mnist分类
使用tensorflow构造神经网络用来进行mnist数据集的分类 相比与上一节讲到的逻辑回归,神经网络比逻辑回归多了隐藏层,同时在每一个线性变化后添加了relu作为激活函数, 神经网络使用的损失值为 ...
随机推荐
- 洛谷-P3805-Manacher模板
链接: https://www.luogu.org/problem/P3805 题意: 给出一个只由小写英文字符a,b,c...y,z组成的字符串S,求S中最长回文串的长度. 字符串长度为n 思路: ...
- MessagePack Java 0.6.X 可选字段
你可添加一个新的字段来保持可用性.在新字段中使用 @Optional 注解. @Message public static class MyMessage { public String na ...
- Jmeter(七)关联之JSON提取器
如果返回的数据是JSON格式的,我们可以用JSON提取器来提取需要的字段,这样更简单一点 Variable names:保存的变量名,后面使用${Variable names}引用 JSON Path ...
- JSTL的forEach标签中的属性具体含义
JSTL的forEach标签在JSP页面经常替代Java脚本的循环语句,生成多个记录的信息.一般只需 一个一个的展示记录即可,有些需要获取当前记录的索引.在需要获取当前记录的索引的时候可能 有点麻烦, ...
- docker下MySQL镜像的使用方法
预习: 使用到的docker命令: docker images 显示本地有的镜像 docker pull +镜像名称 从docker hub上面拉取镜像 docker run --nam ...
- 简单的SSRF的学习
自己眼中的SSRF 成因 服务端允许了 可以向其他服务器请求获取一些数据 通过各种协议 http https file等(外网服务器所在的内网进行端口的扫描指纹的识别等) 一SSRF配合redis未授 ...
- python中的fstring的 !r,!a,!s
首先是fstring的结构 f ' <text> { <expression> <optional !s, !r, or !a> <optional : fo ...
- shell编程-定时删除(30天)文件
1.创建shell touch /opt/auto-del-30-days-ago.sh chmod +x auto-del-30-days-ago.sh 2.编辑shell脚本: vi auto-d ...
- Eclipse项目迁移到MyEclipse后,继承HttpServlet报错问题
网上好多说法,比如要去对比eclipse和myeclipse的.project文件等等,但我的问题就是Libraries没有导入tomcat,导入之后,报错就消失了. 这里没有给出导入方法,只是给遇到 ...
- SRS之信号的管理:SrsSignalManager
1. 综述 SRS 中使用了 State Threads 协程库,该库对信号的处理是将信号事件转换为 I/O 事件.主要做法是:对关注的信号设置同样地信号处理函数 sig_catcher(),该函数捕 ...