百度OCR文字识别API使用心得===com.baidu.ocr.sdk.exception.SDKError[283604]
异常com.baidu.ocr.sdk.exception.SDKError[283604]App identifier unmatch.错误的packname或bundleId.logId::30309247
https://download.csdn.net/download/pyfysf/10406761
最终实现的效果(识别的有些慢,是由于我的网速原因。-_-)

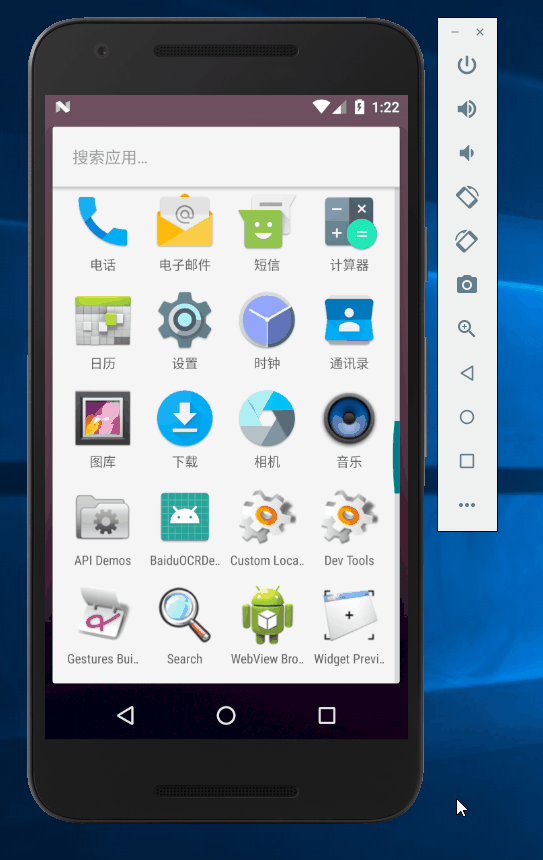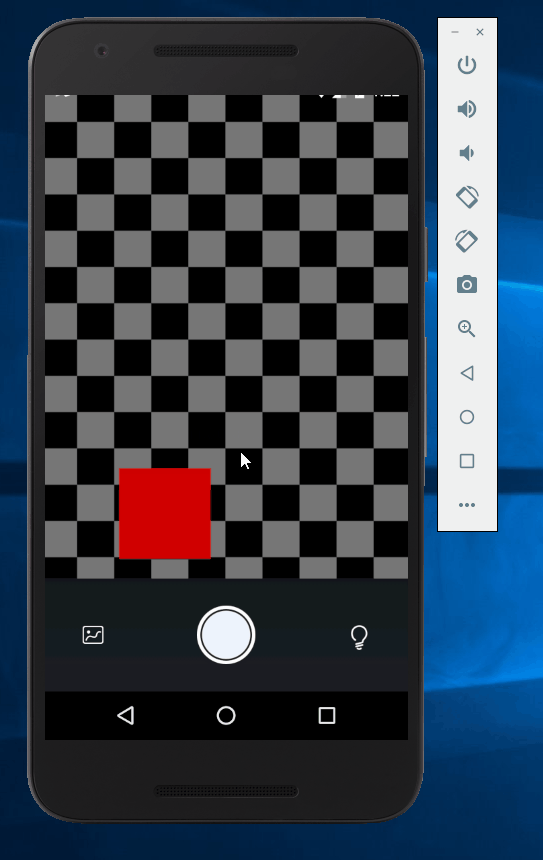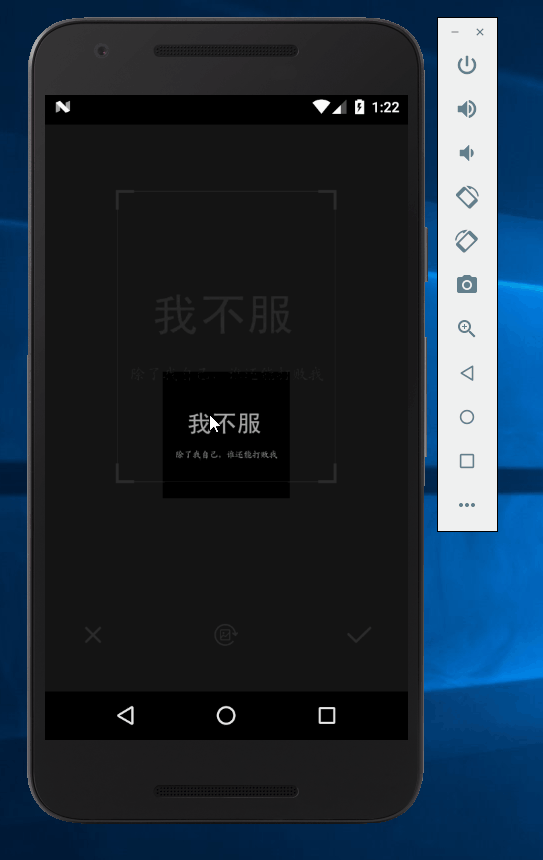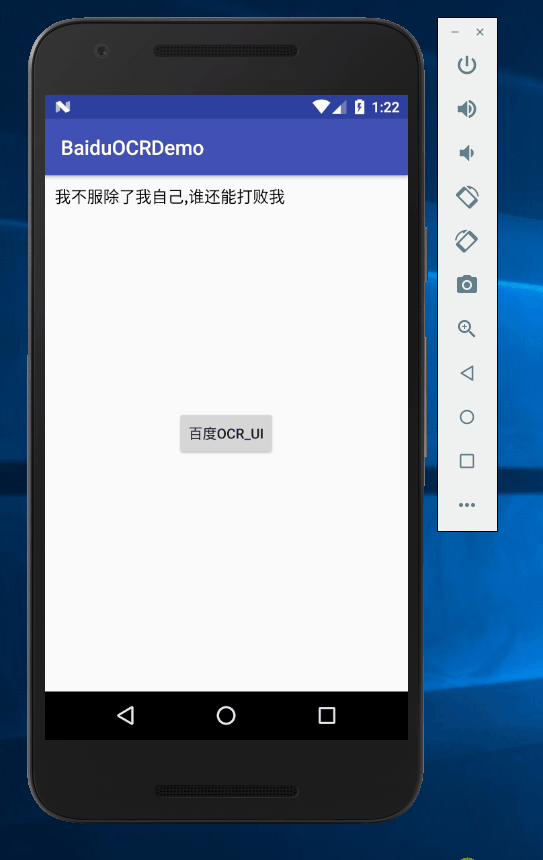
最近有个小项目使用到了OCR技术,顺便到网上搜索了一下,大家都在使用百度的API。所以我就调用了百度的接口。在使用的过程中也是遇到了各种各样的错误。
比如TOKEN ERROR了。等等。
注册登录百度云平台
首先注册百度账号,点击这里跳转到百度API接口首页

点击控制台进行登录注册。
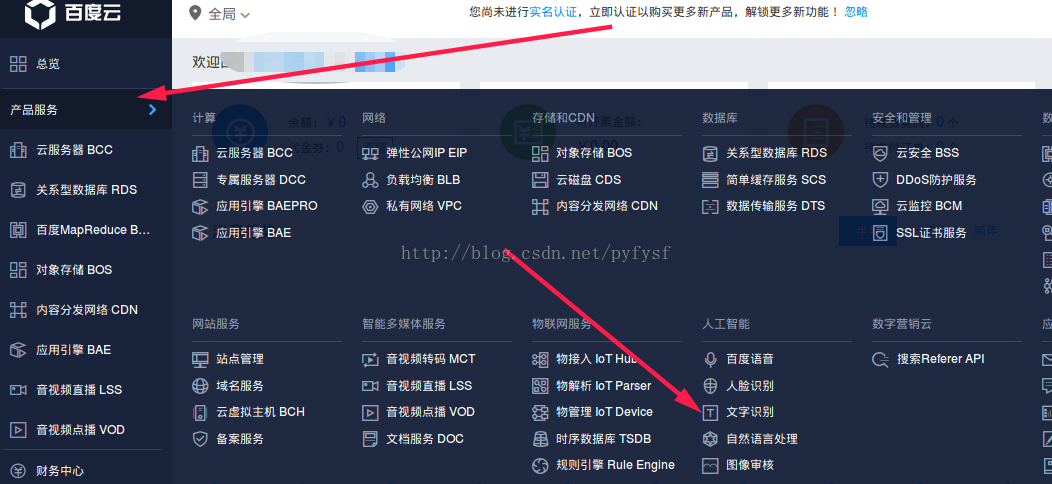
选择服务,创建应用
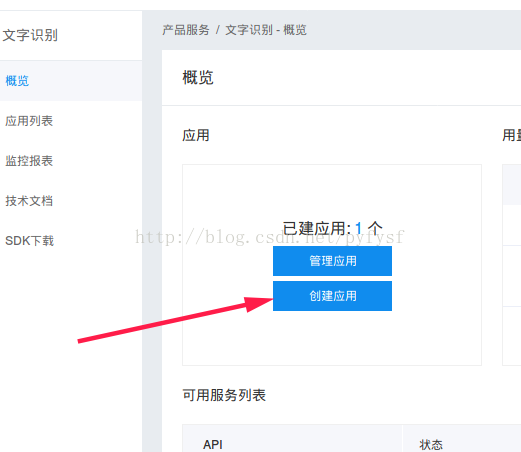
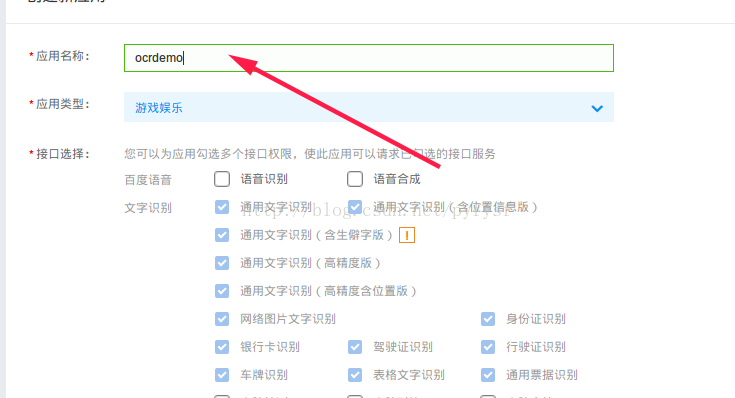
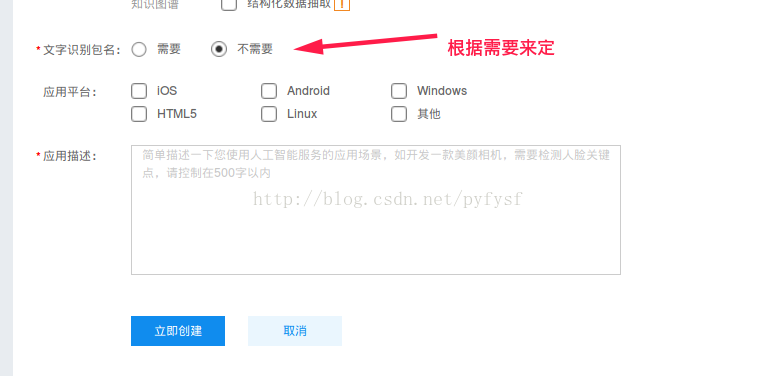
选择需要包名的朋友看过来 >>>>>https://blog.csdn.net/pyfysf/article/details/86438769
这个AK和SK是需要在代码中使用到的

配置SDK,查看文档调用接口。
点击这里进入API文档;
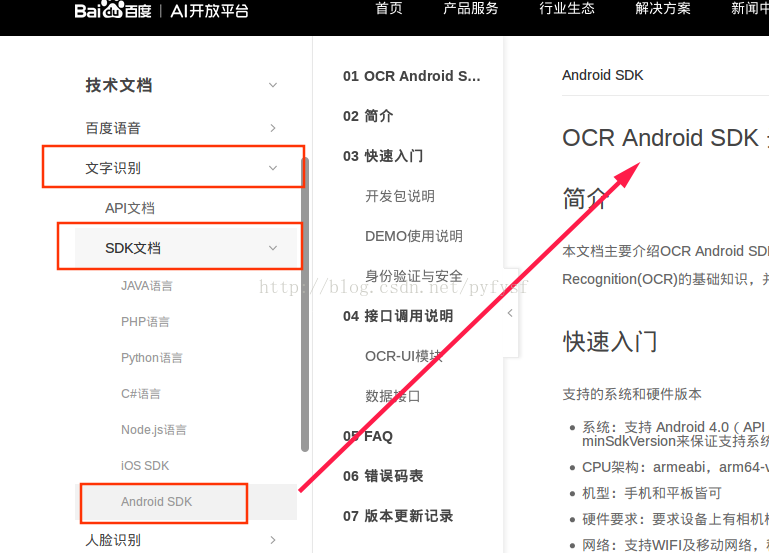
博主使用的是Android平台的SDK。
根据步骤进行SDK工程配置。
配置完工程之后博主就很惊喜的去调用方法进行写代码了。但是,logcat总是报错。说获取token失败,packname错误或者AK和SK错误。
这里我就很是纳闷。我根本没有设置项目的包名,并且我的AK和SK是正确的。大家有知道解决方法,求大神在评论区指教博主。博主在这里叩谢。
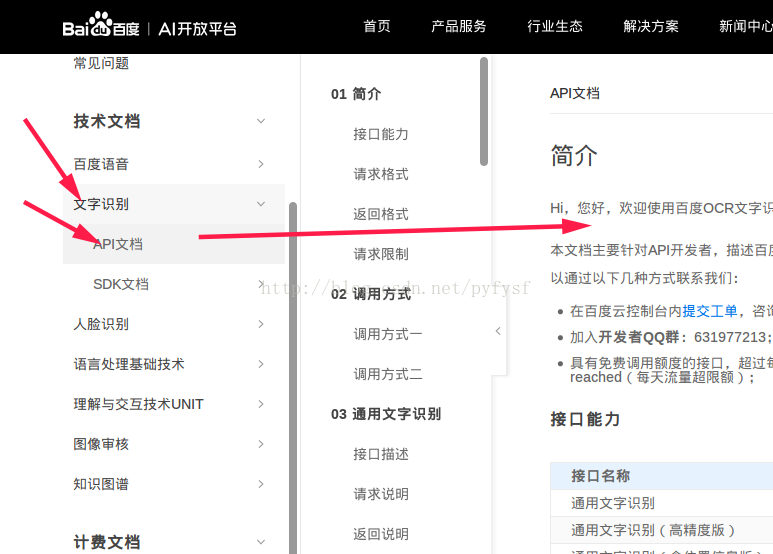
然后经过我查询资料,我选择请求API,从而不去调用百度封装的方法。
查阅API文档。
实现代码片段(不提供xml布局文件)
下面将贴一些代码片段。
博主是打开相机拍一张照片进行扫描实现OCR识别文字。百度的API可以接受本地图片的路径,或者网络上的图片URL也可以进行OCR文字扫描。
我用到了百度提供的UI,在SDK里面导入到项目里面就可以了。
/**
* 打开相机
*/
public void openCameraByBaidu() {
Intent intent = new Intent(GuideActivity.this, CameraActivity.class);
intent.putExtra(CameraActivity.KEY_OUTPUT_FILE_PATH,
FileUtil.getSaveFile(getApplication()).getAbsolutePath());
intent.putExtra(CameraActivity.KEY_CONTENT_TYPE,
CameraActivity.CONTENT_TYPE_GENERAL);
startActivityForResult(intent, OPEN_CAMERA_OK); }
拍照之后获取照片的保存路径。
@Override
protected void onActivityResult(int requestCode, int resultCode, Intent data) {
//判断请求码是否是请求打开相机的那个请求码
if (requestCode == OPEN_CAMERA_OK && resultCode == RESULT_OK) { String photoPath = FileUtil.getSaveFile(this).getAbsolutePath();
checkData(photoPath);
}
}
核心代码在这里!!
请求百度文字识别API,进行图片OCR识别。我用的是xutils3.0请求的网络。可以使用HTTPConnection发起get请求。
/**
* 请求百度API接口,进行获取数据
*
* @param filePath
*/
private void checkData(String filePath) { try { //把图片文件转换为字节数组
byte[] imgData = FileUtil.readFileByBytes(filePath); //对字节数组进行Base64编码
String imgStr = Base64Util.encode(imgData);
final String params = URLEncoder.encode("image", "UTF-8") + "=" + URLEncoder.encode(imgStr, "UTF-8"); RequestParams entiry = new RequestParams(ConstantValue.BAIDU_TOKEN_URL); x.http().get(entiry, new Callback.CommonCallback<String>() {
@Override
public void onSuccess(final String result) {
Gson gson = new Gson();
TokenInfo tokenInfo = gson.fromJson(result, TokenInfo.class); final String access_token = tokenInfo.getAccess_token(); new Thread() {
public void run() { //
public static final String BAIDU_TOKEN_URL
= "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=" + 你在百度控制台创建的AK+ "&client_secret=" +
你在百度控制台创建的SK; String resultStr = HttpUtil.post(ConstantValue.BAIDU_INTER_URL, access_token, params);
Log.e("MainActivity", "MainActivity onSuccess()" + resultStr);
Message msg = Message.obtain();
msg.obj = resultStr;
msg.what = PRESER_IMG_OK;
handler.sendMessage(msg);
}
}.start();
}
@Override
public void onError(Throwable ex, boolean isOnCallback) { }
@Override
public void onCancelled(CancelledException cex) {
}
@Override
public void onFinished() {
}
});
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
解析数据,官方返回的是一个json串。所以我们进行解析数据
private static Handler handler = new Handler() {
public void handleMessage(Message msg) {
switch (msg.what) {
case PRESER_IMG_OK:
String data = (String) msg.obj;
preserData(data);
break;
}
}
};
private static void preserData(String data) {
Gson gson = new Gson();
WordInfo wordInfo = gson.fromJson(data, WordInfo.class);
if(wordInfo.getError_code() != null) {
if (wordInfo.getError_code() == 17 || wordInfo.getError_code() == 19 || wordInfo.getError_code() == 18) {
Toast.makeText(MyApp.getContext(), "请求量超出限额", Toast.LENGTH_SHORT).show();
return;
}
}
if (wordInfo.getWords_result() == null || wordInfo.getWords_result_num() < 0 || wordInfo.getWords_result().size() == 0) {
Toast.makeText(MyApp.getContext(), "文字扫描识别失败,请重试", Toast.LENGTH_SHORT).show();
return;
}
wordInfo.getWords_result() ;//这里面就是扫描出来的数据
}
FileUtil和HttpUtils
public static File getSaveFile(Context context) {
File file = new File(context.getFilesDir(), "pic.jpg");
return file;
}
/**
* 根据文件路径读取byte[] 数组
*/
public static byte[] readFileByBytes(String filePath) throws IOException {
File file = new File(filePath);
if (!file.exists()) {
throw new FileNotFoundException(filePath);
} else {
ByteArrayOutputStream bos = new ByteArrayOutputStream((int) file.length());
BufferedInputStream in = null;
try {
in = new BufferedInputStream(new FileInputStream(file));
short bufSize = 1024;
byte[] buffer = new byte[bufSize];
int len1;
while (-1 != (len1 = in.read(buffer, 0, bufSize))) {
bos.write(buffer, 0, len1);
}
byte[] var7 = bos.toByteArray();
return var7;
} finally {
try {
if (in != null) {
in.close();
}
} catch (IOException var14) {
var14.printStackTrace();
}
bos.close();
}
}
}
}
/**
* http 工具类
*/
public class HttpUtil {
public static String post(String requestUrl, String accessToken, String params) {
try {
String generalUrl = requestUrl + "?access_token=" + accessToken;
URL url = new URL(generalUrl);
// 打开和URL之间的连接
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
// 设置通用的请求属性
connection.setRequestProperty("Content-Type", "application/x-www-form-urlencoded");
connection.setRequestProperty("Connection", "Keep-Alive");
connection.setUseCaches(false);
connection.setDoOutput(true);
connection.setDoInput(true);
// 得到请求的输出流对象
DataOutputStream out = new DataOutputStream(connection.getOutputStream());
out.writeBytes(params);
out.flush();
out.close();
// 建立实际的连接
connection.connect();
// 获取所有响应头字段
Map<String, List<String>> headers = connection.getHeaderFields();
// 遍历所有的响应头字段
for (String key : headers.keySet()) {
System.out.println(key + "--->" + headers.get(key));
}
// 定义 BufferedReader输入流来读取URL的响应
BufferedReader in = null;
if (requestUrl.contains("nlp"))
in = new BufferedReader(new InputStreamReader(connection.getInputStream(), "GBK"));
else
in = new BufferedReader(new InputStreamReader(connection.getInputStream(), "UTF-8"));
String result = "";
String getLine;
while ((getLine = in.readLine()) != null) {
result += getLine;
}
in.close();
System.out.println("result:" + result);
return result;
}catch (Exception e){
throw new RuntimeException(e);
}
}
}
Base64Util
/**
* http 工具类
*/
public class HttpUtil { public static String post(String requestUrl, String accessToken, String params) {
try {
String generalUrl = requestUrl + "?access_token=" + accessToken;
URL url = new URL(generalUrl);
// 打开和URL之间的连接
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
// 设置通用的请求属性
connection.setRequestProperty("Content-Type", "application/x-www-form-urlencoded");
connection.setRequestProperty("Connection", "Keep-Alive");
connection.setUseCaches(false);
connection.setDoOutput(true);
connection.setDoInput(true); // 得到请求的输出流对象
DataOutputStream out = new DataOutputStream(connection.getOutputStream());
out.writeBytes(params);
out.flush();
out.close(); // 建立实际的连接
connection.connect();
// 获取所有响应头字段
Map<String, List<String>> headers = connection.getHeaderFields();
// 遍历所有的响应头字段
for (String key : headers.keySet()) {
System.out.println(key + "--->" + headers.get(key));
}
// 定义 BufferedReader输入流来读取URL的响应
BufferedReader in = null;
if (requestUrl.contains("nlp"))
in = new BufferedReader(new InputStreamReader(connection.getInputStream(), "GBK"));
else
in = new BufferedReader(new InputStreamReader(connection.getInputStream(), "UTF-8"));
String result = "";
String getLine;
while ((getLine = in.readLine()) != null) {
result += getLine;
}
in.close();
System.out.println("result:" + result);
return result;
}catch (Exception e){
throw new RuntimeException(e);
}
}
}
这样就可以实现了。
https://download.csdn.net/download/pyfysf/10406761
有问题可以加博主QQ哦。337081267
https://download.csdn.net/download/pyfysf/10406761
百度OCR文字识别API使用心得===com.baidu.ocr.sdk.exception.SDKError[283604]的更多相关文章
- 怎么在OCR文字识别软件中安装和启动 OCR文字识别软件 Hot Folder
默认情况下,ABBYY Hot Folder 会与 ABBYY FineReader 12 一起安装到计算机中.(关于ABBYY FineReader 12请参考ABBYY FineReader 12 ...
- PHP:基于百度大脑api实现OCR文字识别
有个项目要用到文字识别,网上找了很多资料,效果不是很好,偶然的机会,接触到百度大脑.百度大脑提供了很多解决方案,其中一个就是文字识别,百度提供了三种文字识别,分别是银行卡识别.身份证识别和通用文字识别 ...
- 一篇文章搞定百度OCR图片文字识别API
一篇文章搞定百度OCR图片文字识别API https://www.jianshu.com/p/7905d3b12104
- 百度Ocr文字识别
简述 最近开发一个项目需要用到Ocr文字识别技术来识别手写文字,在评估过程中体验了百度的文字识别和腾讯的文字识别.查找官方开发文档,发现它们都有印刷体和手写体两种符合项目需求的识别模式,但是腾讯的手写 ...
- MUI框架-11-MUI前端 +php后台接入百度文字识别API
MUI框架-11-MUI前端 +php后台接入百度文字识别API 这里后台不止一种,Python,Java,PHP,Node,C++,C# 都可以 这里使用的是 php 来介绍,已经解决所有问题,因为 ...
- 百度OCR 文字识别 Android安全校验
百度OCR接口使用总结: 之前总结一下关于百度OCR文字识别接口的使用步骤(Android版本 不带包名配置 安全性弱).这边博客主要介绍,百度OCR文字识别接口,官方推荐使用方式,授权文件(安全模式 ...
- 利用百度文字识别API识别图像中的文字
本文将会介绍如何使用百度AI开放平台中的文字识别服务来识别图片中的文字.百度AI开放平台的访问网址为:http://ai.baidu.com/ ,为了能够使用该平台提供的AI服务,你需要事先注册一 ...
- 百度OCR文字识别-Android安全校验
本文转载自好基友upuptop:https://blog.csdn.net/pyfysf/article/details/86438769 效果图: 如下为文章正文: 百度OCR接口使用总结:之前总结 ...
- 小白学Python——用 百度AI 实现 OCR 文字识别
百度AI功能还是很强大的,百度AI开放平台真的是测试接口的天堂,免费接口很多,当然有量的限制,但个人使用是完全够用的,什么人脸识别.MQTT服务器.语音识别等等,应有尽有. 看看OCR识别免费的量 快 ...
随机推荐
- Windows+Idea安装Hadoop开发环境
前言:这种问题,本来不应该写篇博客的,但是实在是折磨我太久了,现在终于修好了,必须记一下,否则对不起自己的时间,对自己的博客道歉 *** 简介 环境:Windows 10+JDK1.8+Intelli ...
- Qt4.85静态编译配置VS动态编译(非常详细的图文教程)
http://www.qter.org/forum.php?mod=viewthread&tid=1409&extra=page%3D1&page=1
- 多线程基础理论--C#
1.主线程 进程创建时,默认创建一个线程,这个线程就是主线程.主线程是产生其他子线程的线程,同时,主线程必须是最后一个结束执行的线程,它完成各种关闭其他子线程的操作.尽管主线程是程序开始时自动创建的, ...
- linux程序机制入门
GCC环境 类debian系统运行 apt-get install build-essential 安装gcc环境. 编写c语言程序后,运行 gcc ./hello.c 会得到一个名为 a.out 的 ...
- Spark学习之路(一)—— Spark简介
一.简介 Spark于2009年诞生于加州大学伯克利分校AMPLab,2013年被捐赠给Apache软件基金会,2014年2月成为Apache的顶级项目.相对于MapReduce的批处理计算,Spar ...
- webpack-simple之vagrant热加载
"dev": "cross-env NODE_ENV=development webpack-dev-server --host 192.168.2.10 --port ...
- 秒懂Hash算法(一):什么是Hash
Hash函数 在一般的线性表.树结构中,数据的存储位置是随机的,不像数组可以通过索引能一步查找到目标元素.为了能快速地在没有索引之类的结构中找到目标元素,需要为存储地址和值之间做一种映射关系h(key ...
- 如何用css实线所需要的小三角
使用css实现三角符号 关于使用css制作三角符号,网上有很多的例子了,在这里只是为了详细的向各位解释一下三角符号的原理 下图,是一个长宽为100px,边框宽度为100px的一个元素,由此可见,在cs ...
- Mac iTerm2使用lrzsz上传和下载文件
Mac iTerm2使用lrzsz对服务器上传和下载文件 安装工具 首先需要安装iTerm2和homebrew,在终端中执行(打开终端,使用搜索(command + space),输入terminal ...
- Programming In Lua 第十章
1,lua中的数据结构都是表来实现的.数组就是索引为数值的表. 2,矩阵就是二维数组,三角矩阵就是矩阵的一半. 3,稀疏矩阵问题: 4, 5, 6,