scrapy基础知识之 CrawlSpiders爬取lagou招聘保存在mysql(分布式):
items.py
import scrapy
class LagouItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#id
# obj_id=scrapy.Field()
#职位名
positon_name=scrapy.Field()
#工作地点
work_place=scrapy.Field()
#发布日期
publish_time=scrapy.Field()
#工资
salary=scrapy.Field()
#工作经验
work_experience=scrapy.Field()
#学历
education=scrapy.Field()
#full_time
full_time=scrapy.Field()
#标签
tags=scrapy.Field()
#公司名字
company_name=scrapy.Field()
# #产业
# industry=scrapy.Field()
#职位诱惑
job_temptation=scrapy.Field()
#工作描述
job_desc=scrapy.Field()
#公司logo地址
logo_image=scrapy.Field()
#领域
field=scrapy.Field()
#发展阶段
stage=scrapy.Field()
#公司规模
company_size=scrapy.Field()
# 公司主页
home = scrapy.Field()
#职位发布者
job_publisher=scrapy.Field()
#投资机构
financeOrg=scrapy.Field()
#爬取时间
crawl_time=scrapy.Field()
lagou.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from LaGou.items import LagouItem
from LaGou.utils.MD5 import get_md5
from datetime import datetime class LagouSpider(CrawlSpider):
name = 'lagou'
allowed_domains = ['lagou.com']
start_urls = ['https://www.lagou.com/zhaopin/']
content_links=LinkExtractor(allow=(r"https://www.lagou.com/jobs/\d+.html"))
page_links=LinkExtractor(allow=(r"https://www.lagou.com/zhaopin/\d+"))
rules = (
Rule(content_links, callback="parse_item", follow=False),
Rule(page_links,follow=True)
) def parse_item(self, response):
item=LagouItem()
#获取到公司拉钩主页的url作为ID
# item["obj_id"]=get_md5(response.url)
#公司名称
item["company_name"]=response.xpath('//dl[@class="job_company"]//a/img/@alt').extract()[0]
# 职位
item["positon_name"]=response.xpath('//div[@class="job-name"]//span[@class="name"]/text()').extract()[0]
#工资
item["salary"]=response.xpath('//dd[@class="job_request"]//span[1]/text()').extract()[0]
# 工作地点
work_place=response.xpath('//dd[@class="job_request"]//span[2]/text()').extract()[0]
item["work_place"]=work_place.replace("/","")
# 工作经验
work_experience=response.xpath('//dd[@class="job_request"]//span[3]/text()').extract()[0]
item["work_experience"]=work_experience.replace("/","")
# 学历
education=response.xpath('//dd[@class="job_request"]//span[4]/text()').extract()[0]
item["education"]=education.replace("/","")
# full_time
item['full_time']=response.xpath('//dd[@class="job_request"]//span[5]/text()').extract()[0]
#tags
tags=response.xpath('//dd[@class="job_request"]//li[@class="labels"]/text()').extract()
item["tags"]=",".join(tags)
#publish_time
item["publish_time"]=response.xpath('//dd[@class="job_request"]//p[@class="publish_time"]/text()').extract()[0]
# 职位诱惑
job_temptation=response.xpath('//dd[@class="job-advantage"]/p/text()').extract()
item["job_temptation"]=",".join(job_temptation)
# 工作描述
job_desc=response.xpath('//dd[@class="job_bt"]/div//p/text()').extract()
item["job_desc"]=",".join(job_desc).replace("\xa0","").strip()
#job_publisher
item["job_publisher"]=response.xpath('//div[@class="publisher_name"]//span[@class="name"]/text()').extract()[0]
# 公司logo地址
logo_image=response.xpath('//dl[@class="job_company"]//a/img/@src').extract()[0]
item["logo_image"]=logo_image.replace("//","")
# 领域
field=response.xpath('//ul[@class="c_feature"]//li[1]/text()').extract()
item["field"]="".join(field).strip()
# 发展阶段
stage=response.xpath('//ul[@class="c_feature"]//li[2]/text()').extract()
item["stage"]="".join(stage).strip()
# 投资机构
financeOrg=response.xpath('//ul[@class="c_feature"]//li[3]/p/text()').extract()
if financeOrg:
item["financeOrg"]="".join(financeOrg)
else:
item["financeOrg"]=""
#公司规模
if financeOrg:
company_size= response.xpath('//ul[@class="c_feature"]//li[4]/text()').extract()
item["company_size"]="".join(company_size).strip()
else:
company_size = response.xpath('//ul[@class="c_feature"]//li[3]/text()').extract()
item["company_size"] = "".join(company_size).strip()
# 公司主页
item["home"]=response.xpath('//ul[@class="c_feature"]//li/a/@href').extract()[0]
# 爬取时间
item["crawl_time"]=datetime.now() yield item
pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html import pymysql
class LagouPipeline(object): def process_item(self, item, spider):
con = pymysql.connect(host="127.0.0.1", user="root", passwd="", db="lagou",charset="utf8")
cur = con.cursor()
sql = ("insert into lagouwang(company_name,positon_name,salary,work_place,work_experience,education,full_time,tags,publish_time,job_temptation,job_desc,job_publisher,logo_image,field,stage,financeOrg,company_size,home,crawl_time)"
"VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)")
lis=(item["company_name"],item["positon_name"],item["salary"],item["work_place"],item["work_experience"],item["education"],item['full_time'],item["tags"],item["publish_time"],item["job_temptation"],item["job_desc"],item["job_publisher"],item["logo_image"],item["field"],item["stage"],item["financeOrg"],item["company_size"],item["home"],item["crawl_time"])
cur.execute(sql, lis)
con.commit()
cur.close()
con.close() return item
middlewares.py (主要是User_Agent的随机切换 没有加ip代理)
import random
from LaGou.settings import USER_AGENTS class RandomUserAgent(object):
def process_request(self, request, spider):
useragent = random.choice(USER_AGENTS) request.headers.setdefault("User-Agent", useragent)
settings.py
BOT_NAME = 'LaGou' SPIDER_MODULES = ['LaGou.spiders']
NEWSPIDER_MODULE = 'LaGou.spiders'
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 5
COOKIES_ENABLED = False
USER_AGENTS = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5"
]
DOWNLOADER_MIDDLEWARES = {
'LaGou.middlewares.RandomUserAgent': 1,
# 'LaGou.middlewares.MyCustomDownloaderMiddleware': 543,
}
ITEM_PIPELINES = {
#'scrapy_redis.pipelines.RedisPipeline':300, 'LaGou.pipelines.LagouPipeline': 300,
}
main.py(用于启动调试)
#coding=utf-8
from scrapy.cmdline import execute
execute(["scrapy","crawl","lagou"])
在settings.py配置加入如下代码会实现分布式数据保存在redis里面,怎么从redis取出数据参考前几章
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline':300, #'LaGou.pipelines.LagouPipeline': 300,
}
主要用到知识点:CrawlSpider的(LinkExtractor,Rule),内容的处理(xpath,extract),字符的处理(join,replace,strip,split),User_Agent随机切换等
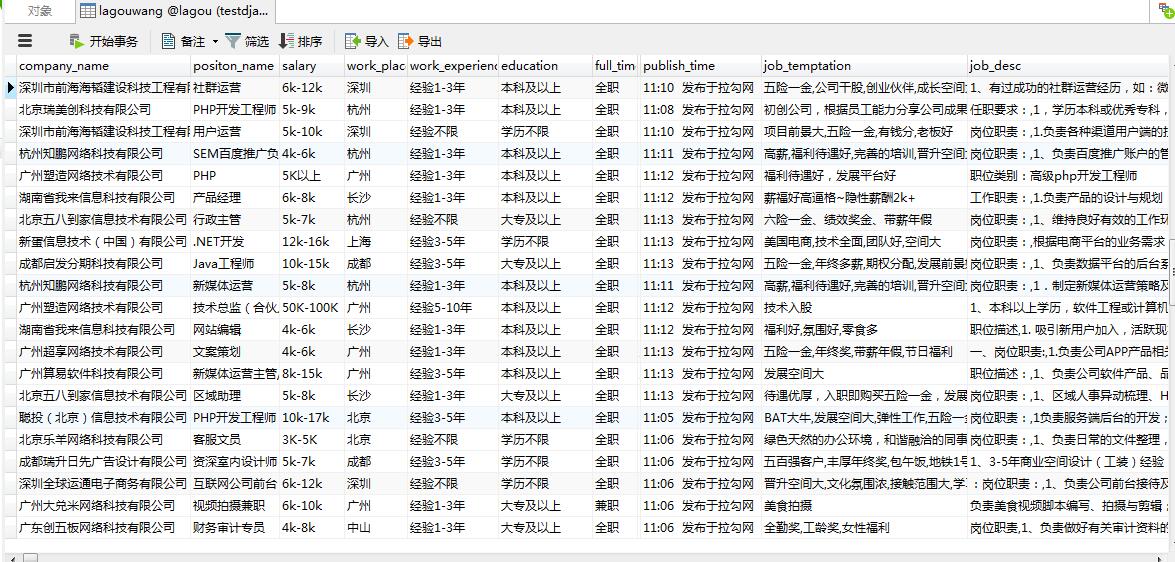
scrapy基础知识之 CrawlSpiders爬取lagou招聘保存在mysql(分布式):的更多相关文章
- scrapy基础知识之 CrawlSpiders(爬取腾讯校内招聘):
import scrapyfrom scrapy.spider import CrawlSpider,Rulefrom scrapy.linkextractors import LinkExtract ...
- scrapy基础知识之 CrawlSpiders:
通过下面的命令可以快速创建 CrawlSpider模板 的代码: scrapy genspider -t crawl spidername xx.com LinkExtractors class sc ...
- python之scrapy爬取jingdong招聘信息到mysql数据库
1.创建工程 scrapy startproject jd 2.创建项目 scrapy genspider jingdong 3.安装pymysql pip install pymysql 4.set ...
- 将爬取的数据保存到mysql中
为了把数据保存到mysql费了很多周折,早上再来折腾,终于折腾好了 安装数据库 1.pip install pymysql(根据版本来装) 2.创建数据 打开终端 键入mysql -u root -p ...
- scrapy实战2分布式爬取lagou招聘(加入了免费的User-Agent随机动态获取库 fake-useragent 使用方法查看:https://github.com/hellysmile/fake-useragent)
items.py # -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentati ...
- scrapy基础知识之将item 通过pipeline保存数据到mysql mongoDB:
pipelines.py class xxPipeline(object): def process_item(self, item, spider): con=pymysql.connect(hos ...
- 0.Python 爬虫之Scrapy入门实践指南(Scrapy基础知识)
目录 0.0.Scrapy基础 0.1.Scrapy 框架图 0.2.Scrapy主要包括了以下组件: 0.3.Scrapy简单示例如下: 0.4.Scrapy运行流程如下: 0.5.还有什么? 0. ...
- pymysql 使用twisted异步插入数据库:基于crawlspider爬取内容保存到本地mysql数据库
本文的前提是实现了整站内容的抓取,然后把抓取的内容保存到数据库. 可以参考另一篇已经实现整站抓取的文章:Scrapy 使用CrawlSpider整站抓取文章内容实现 本文也是基于这篇文章代码基础上实现 ...
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
随机推荐
- 通通玩blend美工(1)——荧光Button
原文:通通玩blend美工(1)--荧光Button 最近老大出差去了,光做项目也有点烦,写点教程消遣消遣(注:此乃初级教程,所以第一个消遣是本人消遣,第二个是指供各位看官消遣...) 看着各位大虾出 ...
- centos7 防火墙问题
centos从7开始默认用的是firewalld,这个是基于iptables的,虽然有iptables的核心,但是iptables的服务是没安装的.所以你只要停止firewalld服务即可:sudo ...
- UWP中String类型如何转换为Windows.UI.Color
原文:UWP中String类型如何转换为Windows.UI.Color 我在学习过程中遇到的,我保存主题色为string,但在我想让StatusBar随着主题色变化时发现没法使用. ThemeCol ...
- PySide——Python图形化界面入门教程(二)
PySide——Python图形化界面入门教程(二) ——交互Widget和布局容器 ——Interactive Widgets and Layout Containers 翻译自:http://py ...
- 活锁(livelock) 专题
活锁(livelock) 活锁指的是任务或者执行者没有被阻塞,由于某些条件没有满足,导致一直重复尝试,失败,尝试,失败. 活锁和死锁的区别在于,处于活锁的实体是在不断的改变状态,所谓的“活”, 而处于 ...
- CentOS安装mysq
一安装依赖 yum -y install libaio.so.1 libgcc_s.so.1 libstdc++.so.6 yum -y update libstdc++-4.4.7-4.el6.x8 ...
- 华为ensp的安装和使用
去年学完了Cisco的路由交换,从CCNA学到CCIE.学完之后才发现,整个国内市场好像更倾向于使用华为.H3C这类国有网络设备厂商.不过还好,至少网络的基础理论知识是相同的,于是买了基本关于HUAW ...
- UAC就不能一次添加、永久信任吗?
每次都要点击确定,感觉好麻烦. 而且阻碍了某些功能的实现.
- FireUI live Preview使用方法-Berlin
这是可以让开发者事先预览 mobile 画面的作法 1.先确定 Berlin IDE Tools\Option\Form Designer 中 FireUI live Preview broad ...
- 使用Disk2VHD进行P2V转换需要知道的一些事
据不可靠统计,有「无数」工具可以实现物理机到虚拟机的(P2V)转换,虽然有很多此类工具都被开发商帖上了高价标签,但至少来自微软 Sysinternals 工具集中的 Disk2VHD 还是可以免费使用 ...