Python爬取前程无忧网站上python的招聘信息
前言
文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 我姓刘却留不住你的心
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
本文获取的字段有为职位名称,公司名称,公司地点,薪资,发布时间
创建爬虫项目
scrapy startproject qianchengwuyou
cd qianchengwuyou
scrapy genspider -t crawl qcwy www.xxx.com
items中定义爬取的字段
import scrapy
class QianchengwuyouItem(scrapy.Item):
# define the fields for your item here like:
job_title = scrapy.Field()
company_name = scrapy.Field()
company_address = scrapy.Field()
salary = scrapy.Field()
release_time = scrapy.Field()
qcwy.py文件内写主程序
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from qianchengwuyou.items import QianchengwuyouItem
class QcwySpider(CrawlSpider):
name = 'qcwy'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,1.html?']
# https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,7.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=
rules = (
Rule(LinkExtractor(allow=r'https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,(\d+).html?'), callback='parse_item', follow=True),
)
def parse_item(self, response):
list_job = response.xpath('//div[@id="resultList"]/div[@class="el"][position()>1]')
for job in list_job:
item = QianchengwuyouItem()
item['job_title'] = job.xpath('./p/span/a/@title').extract_first()
item['company_name'] = job.xpath('./span[1]/a/@title').extract_first()
item['company_address'] = job.xpath('./span[2]/text()').extract_first()
item['salary'] = job.xpath('./span[3]/text()').extract_first()
item['release_time'] = job.xpath('./span[4]/text()').extract_first()
yield item
pipelines.py文件中写下载规则
import pymysql
class QianchengwuyouPipeline(object):
conn = None
mycursor = None
def open_spider(self, spider):
print('链接数据库...')
self.conn = pymysql.connect(host='172.16.25.4', user='root', password='root', db='scrapy')
self.mycursor = self.conn.cursor()
def process_item(self, item, spider):
print('正在写数据库...')
job_title = item['job_title']
company_name = item['company_name']
company_address = item['company_address']
salary = item['salary']
release_time = item['release_time']
sql = 'insert into qcwy VALUES (null,"%s","%s","%s","%s","%s")' % (
job_title, company_name, company_address, salary, release_time)
bool = self.mycursor.execute(sql)
self.conn.commit()
return item
def close_spider(self, spider):
print('写入数据库完成...')
self.mycursor.close()
self.conn.close()
settings.py文件中打开下载管道和请求头
ITEM_PIPELINES = {
'qianchengwuyou.pipelines.QianchengwuyouPipeline': 300,
}
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2'
运行爬虫,同时写入.json文件
scrapy crawl qcwy -o qcwy.json --nolog
查看数据库是否写入成功,
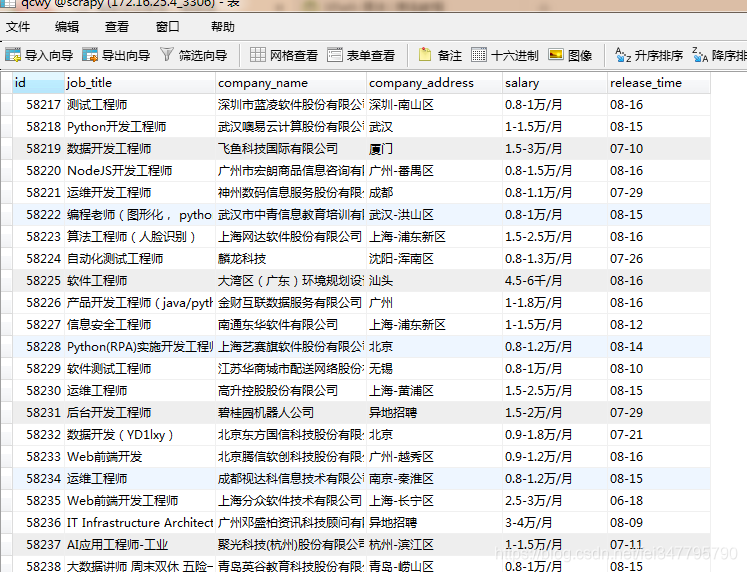
.
Python爬取前程无忧网站上python的招聘信息的更多相关文章
- 爬取前程无忧网站上python的招聘信息。
本文获取的字段有为职位名称,公司名称,公司地点,薪资,发布时间 创建爬虫项目 scrapy startproject qianchengwuyou cd qianchengwuyou scrapy g ...
- python爬取当当网的书籍信息并保存到csv文件
python爬取当当网的书籍信息并保存到csv文件 依赖的库: requests #用来获取页面内容 BeautifulSoup #opython3不能安装BeautifulSoup,但可以安装Bea ...
- 使用python爬取东方财富网机构调研数据
最近有一个需求,需要爬取东方财富网的机构调研数据.数据所在的网页地址为: 机构调研 网页如下所示: 可见数据共有8464页,此处不能直接使用scrapy爬虫进行爬取,因为点击下一页时,浏览器只是发起了 ...
- [转]使用python爬取东方财富网机构调研数据
最近有一个需求,需要爬取东方财富网的机构调研数据.数据所在的网页地址为: 机构调研 网页如下所示: 可见数据共有8464页,此处不能直接使用scrapy爬虫进行爬取,因为点击下一页时,浏览器只是发起了 ...
- Python爬取散文网散文
配置python 2.7 bs4 requests 安装 用pip进行安装 sudo pip install bs4 sudo pip install requests 简要说明一下bs4的使用因为是 ...
- Python 爬取赶集网租房信息
代码已久,有可能需要调整 #coding:utf-8 from bs4 import BeautifulSoup #有这个bs4不用正则也可以定位要爬取的内容了 from urlparse impor ...
- 利用python爬取贝壳网租房信息
最近准备换房子,在网站上寻找各种房源信息,看得眼花缭乱,于是想着能否将基本信息汇总起来便于查找,便用python将基本信息爬下来放到excel,这样一来就容易搜索了. 1. 利用lxml中的xpath ...
- python爬取返利网中值得买中的数据
先使用以前的方法将返利网的数据爬取下来,scrapy框架还不熟练,明日再战scrapy 查找目标数据使用的是beautifulsoup模块. 1.观察网页,寻找规律 打开值得买这块内容 1>分析 ...
- Python爬取网址中多个页面的信息
通过上一篇博客了解到爬取数据的操作,但对于存在多个页面的网址来说,使用上一篇博客中的代码爬取下来的资料并不完整.接下来就是讲解该如何爬取之后的页面信息. 一.审查元素 鼠标移至页码处右键,选择检查元素 ...
随机推荐
- filter,map,reduce三个数组高阶函数的使用
filter ,map ,reduce三个高阶函数的使用 普通方法解决数据问题 const nums1= [10,20,111,222,444,40,50] // 需求1.取出小于100的数字 // ...
- 【docker构建】基于docker构建wordpress博客网站平台
WordPress是使用PHP语言开发的博客平台,用户可以在支持PHP和MySQL数据库的服务器上架设属于自己的网站.也可以把 WordPress当作一个内容管理系统(CMS)来使用. WordPre ...
- Java题库——Chapter8 对象和类
1)________ represents an entity(实体) in the real world that can be distinctly identified. 1) _______ ...
- 移除 DevExpress 的 XtraForm 标题文字阴影
问题 在使用 DevExpress 开发 WinForm 程序时,我是使用的默认皮肤进行开发.但客户要求标题栏背景色改为蓝色,标题文字颜色改为白色. 改颜色比较简单,参考了 DevExpress Su ...
- seaborn总结
Seaborn 数据可视化基础 介绍 Matplotlib 是支持 Python 语言的开源绘图库,因为其支持丰富的绘图类型.简单的绘图方式以及完善的接口文档,深受 Python 工程师.科研学者.数 ...
- 使用Kubernetes进行ProxySQL本机群集
自v1.4.2起,ProxySQL支持本机群集.这意味着多个ProxySQL实例可识别群集; 他们了解彼此的状态,并能够通过根据配置版本,时间戳和校验和值同步最新的配置来自动处理配置更改. Proxy ...
- vue-cli3构建ts项目
1.构建项目 vue create xxx 上面的第一条,也就是 aaa 这一个选项在你第一次创建项目的时候是并不会出现的,只有你第一次创建完成项目后回提示你保存为默认配置模板,下次新建项目的时候就可 ...
- 微信小程序实现点击拍照长按录像功能
微信小程序实现点击拍照长按录像功能 代码里面注释写的都很详细,直接上代码.官方的组件属性中有触摸开始和触摸结束属性.本功能依靠这些属性实现. .wxml代码: <!-- 相机 pages/cam ...
- Spring Boot 2 + jpa + mysql例子
Spring Data框架为数据访问提供了一个通用的模型,无论访问哪种数据库,都可以使用同样的方式,主要有以下几个功能:(1)提供数据与对象映射的抽象层,同一个对象,可以被映射为不同数据库的数据:(2 ...
- Thymeleaf常用语法:模板注释
Thymeleaf模板注释分为标准HTML/XML注释.解析层注释.原型注释三种. 一.注释说明 1.标准HTML/XML注释 直接通过浏览器打开,不显示,Thymeleaf模板引擎解析也不处理,但查 ...