os模块,sys模块,json和pickle模块,logging模块
OS模块
能与操作系统交互,控制文件 / 文件夹
# 创建文件夹
import os
os.mkdir(r'D:\py_case\test')
# 删除文件夹
os.rmdir(r'D:\py_case\test')
# # 列出指定目录下所有文件和子目录 (子目录文件不会列出来)
res = os.listdir(r'D:\pycharm_project\Test')
print(res)
# 打印结果:['.idea', 'ex16.py', 'test.json', 'test.pkl', 'test.py']
# 列出当前文件所在的文件夹
res = os.getcwd()
print(res)
# 打印结果: D:\pycharm_project\Test
# 列出当前文件所在的具体路径
# __file__ pycharm独有的
res = os.path.abspath(__file__) # 根据不同的操作系统更换不同的/或\
print(res) # D:\pycharm_project\Test\test.py
# 文件的文件夹
res = os.path.dirname(os.path.abspath(__file__))
print(res) # D:\pycharm_project\Test
res = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
print(res) # D:\pycharm_project
# 拼接文件路径
res = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'img', 'test.jpg')
print(res) # D:\pycharm_project\Test\img\test.jpg
# 判断路径是否存在(文件 / 文件夹都适用)
res = os.path.exists(r'D:\pycharm_project\Test\ex16.py')
print(res) # True
# 判断是否为文件
res = os.path.isfile(r'D:\pycharm_project\Test\aaa')
print(res) # False
# 删除文件
os.remove('test.txt')
# 重命名文件
os.rename('test.txt', 'test2.txt')
# 判断是否为文件夹
res = os.path.isdir(r'D:\pycharm_project\Test\aaa')
print(res) #True
# 与终端交互,输入命令
res = os.system('dir')
print(res)
res = os.walk(r'D:\pycharm_project\Test\aaa')
print(res) # <generator object walk at 0x0000027DB46916D8>
res = os.walk(r'D:\pycharm_project\Test')
# print(res)
for dir, _, files in res:
# print(i) # 所有文件夹名
# print(l) # 某个文件下对应的所有文件名
for file in files:
file_path = os.path.join(dir,file) # 拼接成所有文件名
if file_path.endswith('py'): # 拿到py文件
print(file_path)
# 打印结果:
'''
D:\pycharm_project\Test\ex16.py
D:\pycharm_project\Test\test.py
D:\pycharm_project\Test\aaa\12.py
'''
| 方法 | 详解 |
|---|---|
| os.getcwd() | 获取当前工作目录,即当前python脚本工作的目录路径 |
| os.chdir("dirname") | 改变当前脚本工作目录;相当于shell下cd |
| os.curdir | 返回当前目录: ('.') |
| os.pardir | 获取当前目录的父目录字符串名:('..') |
| os.makedirs('dirname1/dirname2') | 可生成多层递归目录 |
| os.removedirs('dirname1') | 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 |
| os.mkdir('dirname') | 生成单级目录;相当于shell中mkdir dirname |
| os.rmdir('dirname') | 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname |
| os.listdir('dirname') | 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 |
| os.remove() | 删除一个文件 |
| os.rename("oldname","newname") | 重命名文件/目录 |
| os.stat('path/filename') | 获取文件/目录信息 |
| os.sep | 输出操作系统特定的路径分隔符,win下为"",Linux下为"/" |
| os.linesep | 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" |
| os.pathsep | 输出用于分割文件路径的字符串 win下为;,Linux下为: |
| os.name | 输出字符串指示当前使用平台。win->'nt'; Linux->'posix' |
| os.system("bash command") | 运行shell命令,直接显示 |
| os.environ | 获取系统环境变量 |
| os.path.abspath(path) | 返回path规范化的绝对路径 |
| os.path.split(path) | 将path分割成目录和文件名二元组返回 |
| os.path.dirname(path) | 返回path的目录。其实就是os.path.split(path)的第一个元素 |
| os.path.basename(path) | 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 |
| os.path.exists(path) | 如果path存在,返回True;如果path不存在,返回False |
| os.path.isabs(path) | 如果path是绝对路径,返回True |
| os.path.isfile(path) | 如果path是一个存在的文件,返回True。否则返回False |
| os.path.isdir(path) | 如果path是一个存在的目录,则返回True。否则返回False |
| os.path.join(path1[, path2[, ...]]) | 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 |
| os.path.getatime(path) | 返回path所指向的文件或者目录的最后存取时间 |
| os.path.getmtime(path) | 返回path所指向的文件或者目录的最后修改时间 |
| os.path.getsize(path) | 返回path的大小 |
sys模块
与python解释器交互
import sys
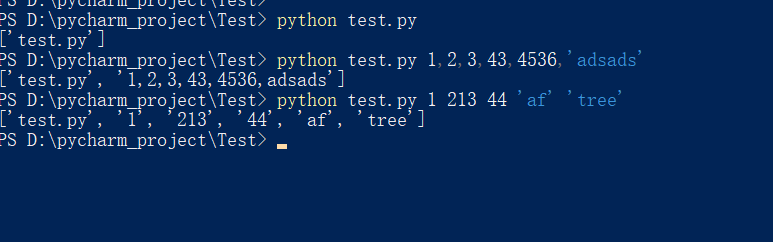
## 最常用,当使用命令行式运行文件,接收多余的参数
res = sys.argv
print(res)
| 方法 | 详解 |
|---|---|
| sys.argv | 命令行参数List,第一个元素是程序本身路径 |
| sys.modules.keys() | 返回所有已经导入的模块列表 |
| sys.exc_info() | 获取当前正在处理的异常类,exc_type、exc_value、exc_traceback当前处理的异常详细信息 |
| sys.exit(n) | 退出程序,正常退出时exit(0) |
| sys.hexversion | 获取Python解释程序的版本值,16进制格式如:0x020403F0 |
| sys.version | 获取Python解释程序的版本信息 |
| sys.maxint | 最大的Int值 |
| sys.maxunicode | 最大的Unicode值 |
| sys.modules | 返回系统导入的模块字段,key是模块名,value是模块 |
| sys.path | 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 |
| sys.platform | 返回操作系统平台名称 |
| sys.stdout | 标准输出 |
| sys.stdin | 标准输入 |
| sys.stderr | 错误输出 |
| sys.exc_clear() | 用来清除当前线程所出现的当前的或最近的错误信息 |
| sys.exec_prefix | 返回平台独立的python文件安装的位置 |
| sys.byteorder | 本地字节规则的指示器,big-endian平台的值是'big',little-endian平台的值是'little' |
| sys.copyright | 记录python版权相关的东西 |
| sys.api_version | 解释器的C的API版本 |
json和pickle模块
序列化和反序列化
- 序列化:按照特定的规则排列,把python数据类型转化为json串,便于跨平台传输
- 反序列化:把json串转化为python / java / c / php 需要的语言
Json序列化并不是python独有的,json序列化在java等语言中也会涉及到,因此使用json序列化能够达到跨平台传输数据的目的。
json数据类型和python数据类型对应关系表
| Json类型 | Python类型 |
|---|---|
| {} | dict |
| [] | list |
| "string" | str |
| 520.13 | int或float |
| true/false | True/False |
| null | None |
json模块
dic = {'a': 1, 'b': 2, 'c': None}
data = json.dumps(dic) # json串中没有单引号
print(type(data), data)
data = json.loads(data)
print(type(data), data)
# 打印结果:
'''
<class 'str'> {"a": 1, "b": 2, "c": null}
<class 'dict'> {'a': 1, 'b': 2, 'c': None}
'''
dic = {'a': 1, 'b': 2, 'c': None}
# 序列化字典为json串,并保存文件
with open('test.json', 'w', encoding='utf-8') as fw:
json.dump(dic, fw)
# 反序列化
with open(f'{"test"}.json', 'r', encoding='utf-8') as fr:
data = json.load(fr)
print(type(data), data) # <class 'dict'> {'a': 1, 'b': 2, 'c': None}
pickle
Pickle序列化和所有其他编程语言特有的序列化问题一样,它只能用于Python。但是pickle的好处是可以存储Python中的所有的数据类型,包括对象,而json不可以。
import pickle
se = {1, 3, 4, 5, 6}
with open('test.pkl', 'wb') as fw:
pickle.dump(se, fw)
se = {1, 3, 4, 5, 6}
def func():
x = 3
def wrapper():
print(x)
return wrapper
with open('test.pkl', 'wb') as fw:
pickle.dump(func, fw)
with open('test.pkl', 'rb') as fr:
data = pickle.load(fr)
# print(data)
res = data()
res()
logging模块
v1:
import logging
# 日志级别(如果不设置,默认显示30以上)
logging.info('info') # 10
logging.debug('debug') # 20
logging.warning('warning') # 30
logging.error('error') # 40
logging.critical('critical') # 50
# 打印结果:
'''
WARNING:root:warning
ERROR:root:error
CRITICAL:root:critical
'''
v2:
import logging
# 日志的基本配置
logging.basicConfig(filename='access.log',
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
level=10) # level是等级,10以上的都记录日志
logging.info('正常信息') # 10
logging.debug('调试信息') # 20
logging.warning('警告信息') # 30
logging.error('报错信息') # 40
logging.critical('严重错误信息') # 50
# 会创建一个access.log日志:
'''
2019-09-27 21:57:45 PM - root - DEBUG -test: 调试信息
2019-09-27 21:57:45 PM - root - INFO -test: 正常信息
2019-09-27 21:57:45 PM - root - WARNING -test: 警告信息
2019-09-27 21:57:45 PM - root - ERROR -test: 报错信息
2019-09-27 21:57:45 PM - root - CRITICAL -test: 严重错误信息
'''
v3: 自定义配置
import logging
# 1. 配置logger对象
cwz_logger = logging.Logger('cwz')
neo_logger = logging.Logger('neo')
# 2. 配置格式
formmater1 = logging.Formatter('%(asctime)s - %(name)s -%(thread)d - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p ', )
formmater2 = logging.Formatter('%(asctime)s : %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p', )
formmater3 = logging.Formatter('%(name)s %(message)s', )
# 3. 配置handler --> 往文件打印or往终端打印
h1 = logging.FileHandler('cwz.log')
h2 = logging.FileHandler('neo.log')
sm = logging.StreamHandler()
# 4. 给handler配置格式
h1.setFormatter(formmater1)
h2.setFormatter(formmater2)
sm.setFormatter(formmater3)
# 5. 把handler绑定给logger对象
cwz_logger.addHandler(h1)
cwz_logger.addHandler(sm)
neo_logger.addHandler(h2)
# 6. 直接使用
cwz_logger.info(f'cwz 购买 变形金刚 8个')
os模块,sys模块,json和pickle模块,logging模块的更多相关文章
- 023--python os、sys、json、pickle、xml模块
一.os模块 os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 >>> os.getcwd() 'C:\\Python36' os.chdir(&quo ...
- 第九节:os、sys、json、pickle、shelve模块
OS模块: os.getcwd()获取当前路径os.chdir()改变目录os.curdir返回当前目录os.pardir()父目录os.makedirs('a/b/c')创建多层目录os.remov ...
- python基础--常用的模块(collections、time、datetime、random、os、sys、json、pickle)
collection模块: namedtuple:它是一个函数,是用来创建一个自定义的tuple对象的,并且规定了tuple元素的个数,并可以用属性而不是索引来引用tuple的某个元素.所以我们就可以 ...
- day16-常用模块I(time、datetime、random、os、sys、json、pickle)
目录 time模块 datetime模块 random模块 os模块 sys模块 json模块与pickle模块 json pickle time模块 time模块一般用于不同时间格式的转换,在使用前 ...
- os常用模块,json,pickle,shelve模块,正则表达式(实现运算符分离),logging模块,配置模块,路径叠加,哈希算法
一.os常用模块 显示当前工作目录 print(os.getcwd()) 返回上一层目录 os.chdir("..") 创建文件包 os.makedirs('python2/bin ...
- python之模块(os、sys、json、subprocess)
目录 os模块 sys模块 json模块 subprocess模块 os模块 os模块主要是与操作系统打交道. 导入os模块 import os 创建单层文件夹,路径必须要存在 os.mkdir(路径 ...
- python json、 pickle 、shelve 模块
json 模块 用于序列化的模块 json,用于字符串 和 python数据类型间进行转换 Json模块提供了四个功能:dumps.dump.loads.load #!/usr/bin/env pyt ...
- CSIC_716_20191118【常用模块的用法 Json、pickle、collections、openpyxl】
序列化模块 序列化:将python或其他语言中的数据类型,转变成字符串类型. python中的八大数据类型回顾:int float str list tuple dict set bool 反序列化: ...
- (十四)json、pickle与shelve模块
任何语言,都有自己的数据类型,那么不同的语言怎么找到一个通用的标准? 比如,后端用Python写的,前端是js,那么后端如果传一个dic字典给前端,前端肯定不认. 所以就有了序列化这个概念. 什么是序 ...
- 20、Python常用模块sys、random、hashlib、logging
一.sys运行时环境模块 sys模块负责程序与python解释器的交互,提供了一系列的函数和变量,用于操控python的运行时环境. 用法: sys.argv:命令行参数List,第一个元素是程序本身 ...
随机推荐
- 爬虫---Beautiful Soup 初始
我们在工作中,都会听说过爬虫,那么什么是爬虫呢? 什么是网络爬虫 爬虫基本原理 所谓网络爬虫就是一个自动化数据采集工具,你只要告诉它要采集哪些数据,丢给它一个 URL,就能自动地抓取数据了.其背后的基 ...
- nginx搭建代理服务器与负载均衡器
一.代理服务器 服务 功能 配置语法 默认 配置位置 配置举例 结果验证 备注 代理服务 反向代理 proxy_pass URL location.if in location.limit_exc ...
- 2、zabbix3.4的安装
系统版本:centos7 数据库版本:mysql二进制安装5.7 zabbix:阿里云安装3.4 一.Zabbix的安装 Zabbix3.4版本官方安装手册链接:https://www.zabbix. ...
- Centos 7 LAMP+wordpress
一.简介 LAMP--->Linux(OS).Apache(http服务器),MySQL(有时也指MariaDB,数据库) 和PHP的第一个字母,一般用来建立web应用平台. 它是 ...
- idea之前的版本
https://www.jetbrains.com/idea/download/previous.html
- C++ trais技术 模板特化的应用
// traits 的应用 /////////////////////////////////////////// // traits template <typename T> clas ...
- 【Eureka篇三】EurekaServer服务注册中心(1)
注:在前面[Rest微服务案例(二)]的基础上进行操作. 1. 新建Maven Module,子模块名称为microservicecloud-eureka-7001,packaging为jar模式 & ...
- OpenDaylight开发hello-world项目之开发环境搭建
OpenDaylight开发hello-world项目之开发环境搭建 OpenDaylight开发hello-world项目之开发工具安装 OpenDaylight开发hello-world项目之代码 ...
- Java 并发系列之十三:安全发布
1. 定义 发布对象(Publish): 使一个对象能够被当前范围之外的代码所使用 对象逸出(Escape): 一种错误的发布.当一个对象还没有构造完成时,就使它被其他线程所见 1.1 发布对象 pu ...
- python接口自动化3-发送post及其他请求
前言 发过get请求相信学习post请求也很快学会,无非就是多了传参时的类型与参数格式.在我常见的post请求中用到最多的是json格式,但也有用其它,下面将介绍常用的参数类型格式. 一.Post请求 ...