Gobblin采集kafka数据
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处
找时间记录一下利用Gobblin采集kafka数据的过程,话不多说,进入正题
一.Gobblin环境变量准备
需要配置好Gobblin0.7.0工作时对应的环境变量,可以去Gobblin的bin目录的gobblin-env.sh配置,比如
export GOBBLIN_JOB_CONFIG_DIR=~/gobblin/gobblin-config-dir
export GOBBLIN_WORK_DIR=~/gobblin/gobblin-work-dir
export HADOOP_BIN_DIR=/opt/cloudera/parcels/CDH-5.4.0-1.cdh5.4.0.p0.27/lib/hadoop/bin
也可以去自己当前用户bashrc下配置,当然,确保JAVA_HOME也已经配置.
这里配置的Gobblin的配置文件目录和工作目录以及执行MR需要用到的hadoop bin目录
二.Gobblin Standalone模式配置和使用
顾名思义,就是在部署Gobblin的单节点上来采集kafka数据,没有用到Hadoop MR,配置过程如下
首先去GOBBLIN_JOB_CONFIG_DIR下,新建一个gobblinStandalone.pull配置文件,配置如下
job.name=GobblinKafkaQuickStart
job.group=GobblinKafka
job.description=Gobblin quick start job for Kafka
job.lock.enabled=false
job.schedule=0 0/3 * * * ?
kafka.brokers=datanode01:9092
source.class=gobblin.source.extractor.extract.kafka.KafkaSimpleSource
extract.namespace=gobblin.extract.kafka writer.builder.class=gobblin.writer.SimpleDataWriterBuilder
writer.file.path.type=tablename
writer.destination.type=HDFS
writer.output.format=txt data.publisher.type=gobblin.publisher.BaseDataPublisher mr.job.max.mappers=1 metrics.reporting.file.enabled=true
metrics.log.dir=${env:GOBBLIN_WORK_DIR}/metrics
metrics.reporting.file.suffix=txt bootstrap.with.offset=earliest
这里需要配置好抽取数据的kafka broker以及一些gobblin的工作组件,如source,extract,writer,publisher等,不明白的可以参考Gobblin wiki,很详细.
我这里额外配置了一个job.schedule让gobblin三分钟检查一次kafka的所有topic是否有新增,然后抽取任务就会三分钟一次定时执行.这里用的Gobblin自带的Quartz定时器.
ok,配置好以后进入Gobblin根目录,启动命令如:
bin/gobblin-standalone.sh –conffile $GOBBLIN_JOB_CONFIG_DIR/gobblinStandalone.pull start
我这里GOBBLIN_JOB_CONFIG_DIR有多个pull文件,因此需要指明,如果GOBBLIN_JOB_CONFIG_DIR下只有一个配置文件,那么直接bin/gobblin-standalone.sh start即可执行
最终抽取过来的数据会输出到GOBBLIN_WORK_DIR/job-output 中去.
三.Gobblin MapReduce模式配置和使用
这次配置Gobblin会使用MapReduce来抽取kafka数据到Hdfs,新建gobblin-mr.pull文件,配置如下
job.name=GobblinKafkaToHdfs
job.group=GobblinToHdfs1
job.description=Pull data from kafka to hdfs use Gobblin
job.lock.enabled=false
kafka.brokers=datanode01:9092 source.class=gobblin.source.extractor.extract.kafka.KafkaSimpleSource
extract.namespace=gobblin.extract.kafka
topic.whitelist=jsonTest writer.builder.class=gobblin.writer.SimpleDataWriterBuilder
simple.writer.delimiter=\n
simple.writer.prepend.size=false
writer.file.path.type=tablename
writer.destination.type=HDFS
writer.output.format=txt
writer.partitioner.class=gobblin.example.simplejson.TimeBasedJsonWriterPartitioner
writer.partition.level=hourly
writer.partition.pattern=yyyy/MM/dd/HH
writer.partition.columns=time
writer.partition.timezone=Asia/Shanghai
data.publisher.type=gobblin.publisher.TimePartitionedDataPublisher mr.job.max.mappers=1 metrics.reporting.file.enabled=true
metrics.log.dir=/gobblin-kafka/metrics
metrics.reporting.file.suffix=txt bootstrap.with.offset=earliest fs.uri=master:8020
writer.fs.uri=${fs.uri}
state.store.fs.uri=${fs.uri} mr.job.root.dir=/gobblin-kafka/working
state.store.dir=/gobblin-kafka/state-store
task.data.root.dir=/jobs/kafkaetl/gobblin/gobblin-kafka/task-data
data.publisher.final.dir=/gobblintest/job-output
注意标红部分的配置第一行,我这里加了topic过滤,只对topic名称为jsonTest的主题感兴趣
因为需求是需要将gobblin的topic数据按照每天每小时来进行目录分区,具体分区目录需要根据kafka record中的时间字段来
我这里record是json格式的,时间字段格式如{…"time":"2016-10-12 00:30:20"…},因此需要继承Gobblin的TimeBasedWriterPartitioner来重写子类方法按照时间字段对hdfs的目录分区
以下配置需要注意
fs.uri=master:8020
改成自己的集群的hdfs地址
writer.partition.columns=time
这里的time和json中的时间字段保持一致即可
writer.partition.level=hourly
表示hdfs分区到小时
writer.partition.pattern=yyyy/MM/dd/HH
表示最终需要在hdfs分区的目录格式(按照自己的最终分区需求自定义即可)
writer.partitioner.class=gobblin.example.simplejson.TimeBasedJsonWriterPartitioner
重写的hdfs按照json时间字段分区的子类,代码我提交到github了,参考如下链接
将扩展后的类加入Gobblin相应的模块,我这里是放入gobblin-example模块中去了,重新build,build有问题的话请参考这篇文章
上面配置文件最后的那些路径都是hdfs路径,请确保Gobblin有读写权限
随后启动命令
bin/gobblin-mapreduce.sh --conf $GOBBLIN_JOB_CONFIG_DIR/gobblin-mr.pull
运行成功后,hdfs会出现如下目录,jsonTest是按照对应topic名称生成的,如下图
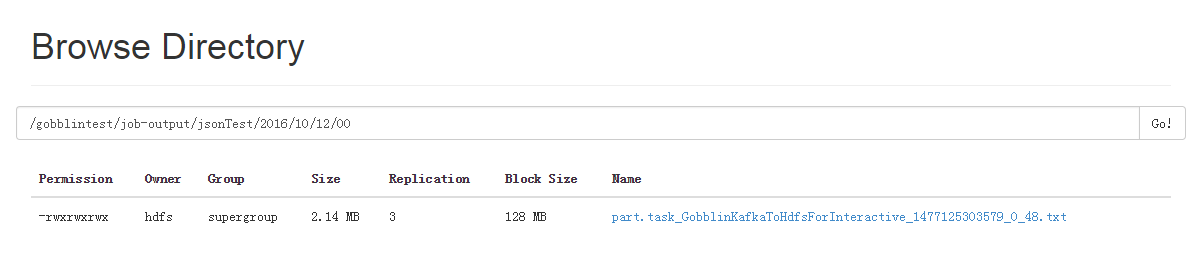
注意MR模式配置Quartz定时调度我试了好几次不起作用,因此如果需要定时执行抽取的话请利用外部的工具,比如Linux的crontab或者Oozie或者Azkaban都是可以的.
四.Gobblin使用总结
1>先熟悉Gobblin官方wiki,写的很详细
2>github上fork一个源代码仔细阅读下source,extract,partioner这块儿的代码
3>使用中遇到问题多研究Gobblin的log和Hadoop的log.
参考资料:
http://gobblin.readthedocs.io/en/latest/case-studies/Kafka-HDFS-Ingestion/
http://gobblin.readthedocs.io/en/latest/user-guide/Partitioned-Writers/
http://gobblin.readthedocs.io/en/latest/developer-guide/IDE-setup/
http://gobblin.readthedocs.io/en/latest/user-guide/FAQs/
Gobblin采集kafka数据的更多相关文章
- MongoDB -> kafka 高性能实时同步(采集)mongodb数据到kafka解决方案
写这篇博客的目的 让更多的人了解 阿里开源的MongoShake可以很好满足mongodb到kafka高性能高可用实时同步需求(项目地址:https://github.com/alibaba/Mong ...
- MongoDB -> kafka 高性能实时同步(sync 采集)mongodb数据到kafka解决方案
写这篇博客的目的 让更多的人了解 阿里开源的MongoShake可以很好满足mongodb到kafka高性能高可用实时同步需求(项目地址:https://github.com/alibaba/Mong ...
- flume采集MongoDB数据到Kafka中
环境说明 centos7(运行于vbox虚拟机) flume1.9.0(自定义了flume连接mongodb的source插件) jdk1.8 kafka(2.11) zookeeper(3.57) ...
- flume实时采集mysql数据到kafka中并输出
环境说明 centos7(运行于vbox虚拟机) flume1.9.0(flume-ng-sql-source插件版本1.5.3) jdk1.8 kafka(版本忘了后续更新) zookeeper(版 ...
- C#+HtmlAgilityPack+XPath带你采集数据(以采集天气数据为例子)
第一次接触HtmlAgilityPack是在5年前,一些意外,让我从技术部门临时调到销售部门,负责建立一些流程和寻找潜在客户,最后在阿里巴巴找到了很多客户信息,非常全面,刚开始是手动复制到Excel, ...
- API例子:用Python驱动Firefox采集网页数据
1,引言 本文讲解怎样用Python驱动Firefox浏览器写一个简易的网页数据采集器.开源Python即时网络爬虫项目将与Scrapy(基于twisted的异步网络框架)集成,所以本例将使用Scra ...
- Performance Monitor采集性能数据
Performance Monitor采集性能数据 Windows本身为我们提供了很多好用的性能分析工具,大家日常都使用过资源管理器,在里面能即时直观的看到CPU占用率.物理内存使用量等信息.此外新系 ...
- java spark-streaming接收TCP/Kafka数据
本文将展示 1.如何使用spark-streaming接入TCP数据并进行过滤: 2.如何使用spark-streaming接入TCP数据并进行wordcount: 内容如下: 1.使用maven,先 ...
- 【Android 应用开发】分析各种Android设备屏幕分辨率与适配 - 使用大量真实安卓设备采集真实数据统计
.主要是为了总结一下 对这些概念有个直观的认识; . 作者 : 万境绝尘 转载请注明出处 : http://blog.csdn.net/shulianghan/article/details/198 ...
随机推荐
- linux内核分析作业8:理解进程调度时机跟踪分析进程调度与进程切换的过程
1. 实验目的 选择一个系统调用(13号系统调用time除外),系统调用列表,使用库函数API和C代码中嵌入汇编代码两种方式使用同一个系统调用 分析汇编代码调用系统调用的工作过程,特别是参数的传递的方 ...
- Java基础系列——IO流
---恢复内容开始--- Java对数据的操作都是通过流的方式,数据的输入和输出是相对内存来说的,将外设的数据读到内存:输入流:将内存的数据写到外设:输出流. 流按操作数据分为两种:字节流,字符流. ...
- .Net中的反应式编程(Reactive Programming)
系列主题:基于消息的软件架构模型演变 一.反应式编程(Reactive Programming) 1.什么是反应式编程:反应式编程(Reactive programming)简称Rx,他是一个使用LI ...
- DRY(Don't Repeat Yourself )原则
凡是写过一些代码的程序猿都能够意识到应该避免重复的代码和逻辑.我们通过提取方法,提取抽象类等等措施来达到这一目的.我们总能时不时的听到类似这样的话:”把这些公用的类放到shared项目去,别的项目还要 ...
- 探索C#之虚拟桶分片
阅读目录 背景 虚拟桶(virtual buckets) 实现 总结 背景 关于数据分片讨论最多的是一致性hash,然而它并不是分布式设计中的银弹百试百灵. 在数据稳定性要求比较高的场景下它的缺点是不 ...
- 迷你MVVM框架 avalonjs 实现上的几个难点
经过两个星期的性能优化,avalon终于实现在一个页面绑定达到上万个的时候不卡顿的目标(angular的限制是2000).现在稍作休息,总结一下avalon遇到的一些难题. 首先是如何监控的问题.所有 ...
- java.io.IOException: invalid header field
通过本文, 我们明白了什么是 jar的清单文件 MANIFEST.MF, 简单示例: E:\ws\Test\WEB-INF\classes>jar cvfm testCL.jar ListTes ...
- JAVAScript控制多个下拉框
方法:获取多选下拉框对象数组→循环判断option选项的selected属性(true为选中,false为未选中)→使用value属性取出选中项的值.实例演示如下: 这个东西我是在百度上查的,我为了方 ...
- Security8:删除Role 和 User
数据库的Role 和 User都是基于Specified DB的,在删除这些Principal之前,必须使用Use clause,切换到指定的DB中. sys.database_role_member ...
- 转帖:DotNet 资源大全中文版
(注:下面用 [$] 标注的表示收费工具,但部分收费工具针对开源软件的开发/部署/托管是免费的) API 框架 NancyFx:轻量.用于构建 HTTP 基础服务的非正式(low-ceremony)框 ...