6.2 DataFrame
一、DataFrame概述

在Spark SQL中,DataFrame就是它的数据抽象,对DataFrame进行转换操作。
DataFrame的推出,让Spark具备了处理大规模结构化数据的能力,不仅比原有的RDD转化方式更加简单易用,而且获得了更高的计算性能Spark能够轻松实现从MySQL到DataFrame的转化,并且支持SQL查询。

- RDD是分布式的Java对象的集合,但是,对象内部结构对于RDD而言却是不可知的;
- DataFrame是一种以RDD为基础的分布式数据集,提供了详细的结构信息
RDD就像一个空旷的屋子,你要找东西要把这个屋子翻遍才能找到。DataFrame相当于在你的屋子里面打上了货架。那你只要告诉他你是在第几个货架的第几个位置,那不就是二维表吗。那就是我们DataFrame就是在RDD基础上加入了列。实际上我们处理数据就像处理二维表一样。
二、DataFrame的创建
从Spark2.0以上版本开始,Spark使用全新的SparkSession接口替代Spark1.6中的SQLContext及HiveContext接口来实现其对数据加载、转换、处理等功能。SparkSession实现了SQLContext及HiveContext所有功能

SparkSession支持从不同的数据源加载数据,并把数据转换成DataFrame,并且支持把DataFrame转换成SQLContext自身中的表,然后使用SQL语句来操作数据。SparkSession亦提供了HiveQL以及其他依赖于Hive的功能的支持。
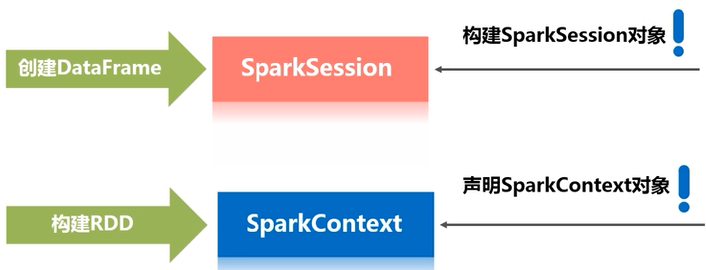
(1)如果是通过交互式shell,执行下面的语句,spark-shell自动创建一个SparkSession对象spark,SparkContext对象sc;

(2)如果是编程中,需要手动创建。(?)
在创建DataFrame之前,为了支持RDD转换为DataFrame及后续的SQL操作,需要通过import语句(即import spark.implicits._)导入相应的包,启用隐式转换。
隐式转换介绍:
- 包括隐式参数、隐式对象、隐式类
- scala独有的
- 当调用对象中不存在的方法,系统会扫描上下文和伴对象看是否有implicit方法,如果有隐式方法则调用隐式方法,隐式方法传入原生对象返回包含扩展方法的对象。
- 原类型和伴生对象都找不到的隐式值,会找手动导入的implicit Import Spark.implicit._
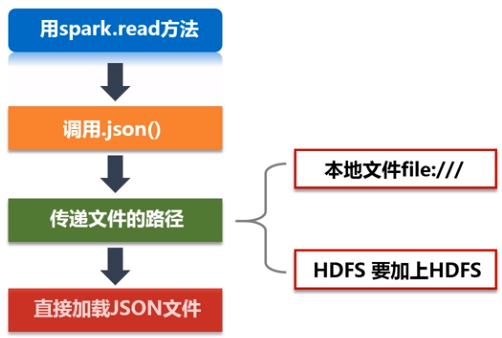
在创建DataFrame时,可以使用spark.read操作,从不同类型的文件中加载数据创建DataFrame,例如:
spark.read.json("people.json"):读取people.json文件创建DataFrame;在读取本地文件或HDFS文件时,要注意给出正确的文件路径;
spark.read.parquet("people.parquet"):读取people.parquet文件创建DataFrame;
spark.read.csv("people.csv"):读取people.csv文件创建DataFrame。

举例:




三、DataFrame的保存
可以使用spark.write操作,把一个DataFrame保存成不同格式的文件,例如,把一个名称为df的DataFrame保存到不同格式文件中,方法如下:
df.write.json("people.json“)
df.write.parquet("people.parquet“)
df.write.csv("people.csv")
例子:从示例文件people.json中创建一个DataFrame,然后保存成csv格式文件,代码如下:

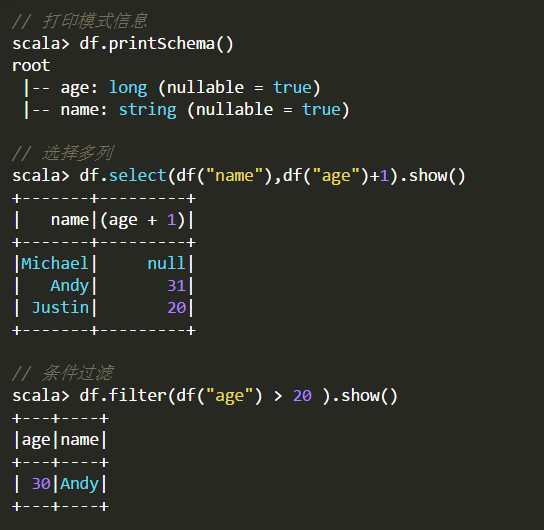
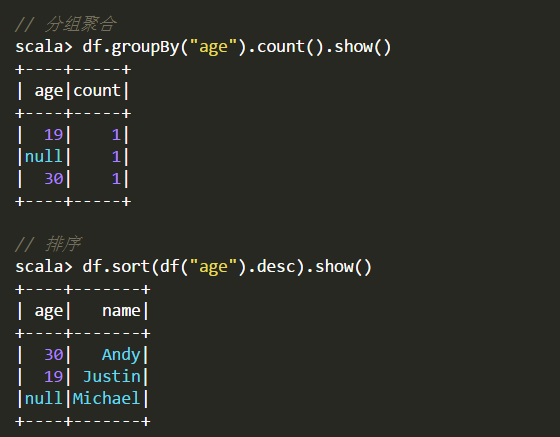
四、DataFrame的常用操作

五、从RDD转换得到DataFrame
Spark SQL支持两种方式将现有RDD转换为DataFrame。
- 第一种方法使用反射来推断RDD的schema并创建DataSet然后将其转化为DataFrame。这种基于反射方法十分简便,但是前提是在您编写Spark应用程序时就已经知道RDD的schema类型。
- 第二种方法是通过编程接口,使用您构建的StructType,然后将其应用于现有RDD。虽然此方法很麻烦,但它允许您在运行之前并不知道列及其类型的情况下构建DataSet
1.利用反射机制推断RDD模式
适用对已知数据结构的RDD转换
举例:在“/usr/local/spark/examples/src/main/resources/”目录下,有个Spark安装时自带的样例数据people.txt,其内容如下,现在要把people.txt加载到内存中生成一个DataFrame,并查询其中的数据:


在利用反射机制推断RDD模式时,需要首先定义一个case class,因为只有case class才能被Spark隐式地转换为DataFrame。


必须要把dataframe注册为临时表才能供下面的查询使用

打印dataframe


2.使用编程方式定义RDD模式
适用于事先不知道字段,通过动态的方式得到信息。
比如,现在需要通过编程方式把people.txt加载进来生成DataFrame,并完成SQL查询。







参考文献:
6.2 DataFrame的更多相关文章
- Spark的DataFrame的窗口函数使用
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 SparkSQL这块儿从1.4开始支持了很多的窗口分析函数,像row_number这些,平时写程 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- pandas.DataFrame对行和列求和及添加新行和列
导入模块: from pandas import DataFrame import pandas as pd import numpy as np 生成DataFrame数据 df = DataFra ...
- pandas.DataFrame排除特定行
使用Python进行数据分析时,经常要使用到的一个数据结构就是pandas的DataFrame 如果我们想要像Excel的筛选那样,只要其中的一行或某几行,可以使用isin()方法,将需要的行的值以列 ...
- Spark SQL 之 DataFrame
Spark SQL 之 DataFrame 转载请注明出处:http://www.cnblogs.com/BYRans/ 概述(Overview) Spark SQL是Spark的一个组件,用于结构化 ...
- spark dataframe 类型转换
读一张表,对其进行二值化特征转换.可以二值化要求输入类型必须double类型,类型怎么转换呢? 直接利用spark column 就可以进行转换: DataFrame dataset = hive.s ...
- 数据分析(9):DataFrame介绍
DataFrame 表格型的数据结构 创建DataFrame 可以通过传入dict的方式,DataFrame会自动加上索引,并且列会有序排列 data = {'state':['a', 'b', 'c ...
- DataFrame格式化
1.如果是格式化成Json的話直接 val rdd = df.toJSON.rdd 2.如果要指定格式需要自定义函数如下: //格式化具体字段条目 def formatItem(p:(StructFi ...
- RDD/Dataset/DataFrame互转
1.RDD -> Dataset val ds = rdd.toDS() 2.RDD -> DataFrame val df = spark.read.json(rdd) 3.Datase ...
随机推荐
- linux学习(六)计划任务命令
目录 at命令 @(计划任务命令) at命令 at命令用于指定在未来某一时间执行一个任务,该任务只能被执行一次 at [选项] [时间] f:指定包含具体指令的任务文件 q:指定新任务队列名称 l:显 ...
- sqlserver实现分隔字符串
sqlserver 使用函数实现分隔字符串 create function dbo.fn_split ( @str_source nvarchar(max), ) ) returns @temp ta ...
- Linux 打开端口方法
关闭防火墙:service iptables stop 开启防火墙:service iptables start 防火墙状态:service iptables status 永久关闭:chkconfi ...
- java8-03-Lambda表达式总结
Lambda 表达式的语法格式 基本结构 () -> {} 左侧 参数列表 右侧 方法体 (Lambda体) 1.无 ...
- LG2602/BZOJ1833 「ZJOI2010」数字计数 数位DP
问题描述 LG2602 BZOJ1833 题解 数位\(\mathrm{DP}\)板子题. 注意限制位数.前导零. \([a,b]=[1,b]-[1,a-1]\) \(\mathrm{Code}\) ...
- shell基础概念, if+命令, shell中引用python, shell脚本的几种执行方式
说明: 虚拟机中shell_test目录用来练习shell, 其中有个test.log文件用来存放日志 #!/usr/bin/bash # shell文件开头, 用来指定该文件使用哪个解释器 ...
- oracle中utl_raw
RAW,类似于CHAR,声明方式RAW(L),L为长度,以字节为单位,作为数据库列最大2000,作为变量最大32767字节.LONG RAW,类似于LONG,作为数据库列最大存储2G字节的数据,作为变 ...
- django--DateTimeField字段orm操作
django中的models.py是我们用来创建数据库里需要的表的,规定表中各个字段的类型,选择合适的字段类型尤为重要,常用的字段类型有:CharField.choice.IntegerField.T ...
- php 压缩字符串
压缩字符串: base64_encode(gzcompress(serialize($data))) 解压字符串: unserialize(gzuncompress(base64_decode($se ...
- C语言程序设计100例之(7):级数求和
例7 级数求和 题目描述 已知: Sn =1+1/2+1/3+…+1/n.显然对于任意一个整数 k,当 n 足够大的时候,Sn>k. 现给出一个整数 k,要求计算出一个最小的 n,使得 S ...