6.2 DataFrame
一、DataFrame概述

在Spark SQL中,DataFrame就是它的数据抽象,对DataFrame进行转换操作。
DataFrame的推出,让Spark具备了处理大规模结构化数据的能力,不仅比原有的RDD转化方式更加简单易用,而且获得了更高的计算性能Spark能够轻松实现从MySQL到DataFrame的转化,并且支持SQL查询。

- RDD是分布式的Java对象的集合,但是,对象内部结构对于RDD而言却是不可知的;
- DataFrame是一种以RDD为基础的分布式数据集,提供了详细的结构信息
RDD就像一个空旷的屋子,你要找东西要把这个屋子翻遍才能找到。DataFrame相当于在你的屋子里面打上了货架。那你只要告诉他你是在第几个货架的第几个位置,那不就是二维表吗。那就是我们DataFrame就是在RDD基础上加入了列。实际上我们处理数据就像处理二维表一样。
二、DataFrame的创建
从Spark2.0以上版本开始,Spark使用全新的SparkSession接口替代Spark1.6中的SQLContext及HiveContext接口来实现其对数据加载、转换、处理等功能。SparkSession实现了SQLContext及HiveContext所有功能

SparkSession支持从不同的数据源加载数据,并把数据转换成DataFrame,并且支持把DataFrame转换成SQLContext自身中的表,然后使用SQL语句来操作数据。SparkSession亦提供了HiveQL以及其他依赖于Hive的功能的支持。
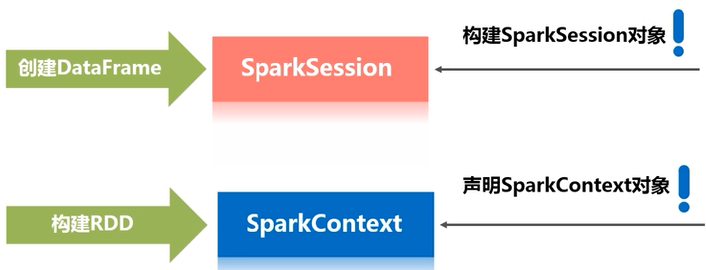
(1)如果是通过交互式shell,执行下面的语句,spark-shell自动创建一个SparkSession对象spark,SparkContext对象sc;

(2)如果是编程中,需要手动创建。(?)
在创建DataFrame之前,为了支持RDD转换为DataFrame及后续的SQL操作,需要通过import语句(即import spark.implicits._)导入相应的包,启用隐式转换。
隐式转换介绍:
- 包括隐式参数、隐式对象、隐式类
- scala独有的
- 当调用对象中不存在的方法,系统会扫描上下文和伴对象看是否有implicit方法,如果有隐式方法则调用隐式方法,隐式方法传入原生对象返回包含扩展方法的对象。
- 原类型和伴生对象都找不到的隐式值,会找手动导入的implicit Import Spark.implicit._
在创建DataFrame时,可以使用spark.read操作,从不同类型的文件中加载数据创建DataFrame,例如:
spark.read.json("people.json"):读取people.json文件创建DataFrame;在读取本地文件或HDFS文件时,要注意给出正确的文件路径;
spark.read.parquet("people.parquet"):读取people.parquet文件创建DataFrame;
spark.read.csv("people.csv"):读取people.csv文件创建DataFrame。
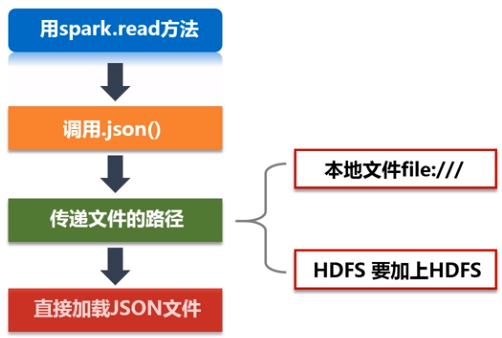

举例:




三、DataFrame的保存
可以使用spark.write操作,把一个DataFrame保存成不同格式的文件,例如,把一个名称为df的DataFrame保存到不同格式文件中,方法如下:
df.write.json("people.json“)
df.write.parquet("people.parquet“)
df.write.csv("people.csv")
例子:从示例文件people.json中创建一个DataFrame,然后保存成csv格式文件,代码如下:

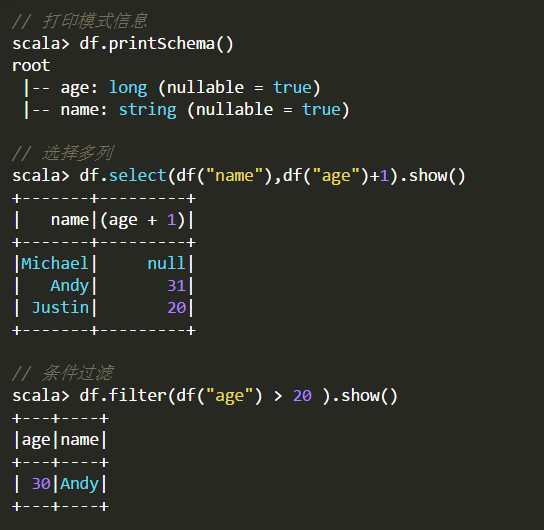
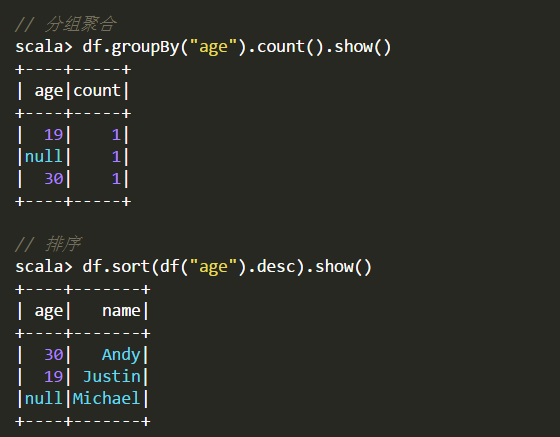
四、DataFrame的常用操作

五、从RDD转换得到DataFrame
Spark SQL支持两种方式将现有RDD转换为DataFrame。
- 第一种方法使用反射来推断RDD的schema并创建DataSet然后将其转化为DataFrame。这种基于反射方法十分简便,但是前提是在您编写Spark应用程序时就已经知道RDD的schema类型。
- 第二种方法是通过编程接口,使用您构建的StructType,然后将其应用于现有RDD。虽然此方法很麻烦,但它允许您在运行之前并不知道列及其类型的情况下构建DataSet
1.利用反射机制推断RDD模式
适用对已知数据结构的RDD转换
举例:在“/usr/local/spark/examples/src/main/resources/”目录下,有个Spark安装时自带的样例数据people.txt,其内容如下,现在要把people.txt加载到内存中生成一个DataFrame,并查询其中的数据:


在利用反射机制推断RDD模式时,需要首先定义一个case class,因为只有case class才能被Spark隐式地转换为DataFrame。


必须要把dataframe注册为临时表才能供下面的查询使用

打印dataframe


2.使用编程方式定义RDD模式
适用于事先不知道字段,通过动态的方式得到信息。
比如,现在需要通过编程方式把people.txt加载进来生成DataFrame,并完成SQL查询。







参考文献:
6.2 DataFrame的更多相关文章
- Spark的DataFrame的窗口函数使用
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 SparkSQL这块儿从1.4开始支持了很多的窗口分析函数,像row_number这些,平时写程 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- pandas.DataFrame对行和列求和及添加新行和列
导入模块: from pandas import DataFrame import pandas as pd import numpy as np 生成DataFrame数据 df = DataFra ...
- pandas.DataFrame排除特定行
使用Python进行数据分析时,经常要使用到的一个数据结构就是pandas的DataFrame 如果我们想要像Excel的筛选那样,只要其中的一行或某几行,可以使用isin()方法,将需要的行的值以列 ...
- Spark SQL 之 DataFrame
Spark SQL 之 DataFrame 转载请注明出处:http://www.cnblogs.com/BYRans/ 概述(Overview) Spark SQL是Spark的一个组件,用于结构化 ...
- spark dataframe 类型转换
读一张表,对其进行二值化特征转换.可以二值化要求输入类型必须double类型,类型怎么转换呢? 直接利用spark column 就可以进行转换: DataFrame dataset = hive.s ...
- 数据分析(9):DataFrame介绍
DataFrame 表格型的数据结构 创建DataFrame 可以通过传入dict的方式,DataFrame会自动加上索引,并且列会有序排列 data = {'state':['a', 'b', 'c ...
- DataFrame格式化
1.如果是格式化成Json的話直接 val rdd = df.toJSON.rdd 2.如果要指定格式需要自定义函数如下: //格式化具体字段条目 def formatItem(p:(StructFi ...
- RDD/Dataset/DataFrame互转
1.RDD -> Dataset val ds = rdd.toDS() 2.RDD -> DataFrame val df = spark.read.json(rdd) 3.Datase ...
随机推荐
- Java实现命令行中的进度条功能
前言 最近在写一个命令行中的下载工具,既然是下载文件用的,那么实时显示下载进度是非常有必要的.因此,就有了这里对进度条的实现尝试. 预览图 还是先预览下效果图吧. 这里是cmd里面的效果,总体看着还行 ...
- qtdomdocument找不到
- 201871010123-吴丽丽《面向对象程序设计(Java)》第一周学习总结
201871010123-吴丽丽<面向对象程序设计 ...
- EXSI的使用
新建资源池 创建好的资源池和虚拟机 创建用户 角色就是权限的集合 右键点击添加. 创建完角色回到清单资源池 重点新登录 bios有一项叫来电自启动. 添加网桥
- 关于git远程
1.注册github的账户(官网;github.com ) 2.新建一个项目(在右上角点击+,选择New repository ),输入项目名和项目描述,其他可根据自己项目选填,创建完成后可查看到ht ...
- 201871010113-刘兴瑞《面向对象程序设计(java)》第七周学习总结
项目 内容 这个作业属于哪个课程 <任课教师博客主页链接> https://www.cnblogs.com/nwnu-daizh/ 这个作业的要求在哪里 <作业链接地址>htt ...
- 剑指Offer-31.整数中1出现的次数(从1到n整数中1出现的次数)(C++/Java)
题目: 求出1~13的整数中1出现的次数,并算出100~1300的整数中1出现的次数?为此他特别数了一下1~13中包含1的数字有1.10.11.12.13因此共出现6次,但是对于后面问题他就没辙了.A ...
- WPF 后台获得 数据模板里的内容控件(DataTemplate)
原文:WPF 后台获得 数据模板里的内容控件(DataTemplate) 假如 <Window.Resources> 里 有一个 Datatemplate 我想获得TextBlo ...
- 使用vmware workstation安装centos 7操作系统
安装步骤 1.点击创建虚拟机,进入新建虚拟机向导,选择自定义,典型:相当于去电脑 旗舰店里店员推荐的是一样,推荐的比一定好,自定义:是手动操作的,没有linux基础最好选择自定义.点击下一步. 2.虚 ...
- 【洛谷4585】[FJOI2015] 火星商店问题(线段树分治)
点此看题面 大致题意: 有\(n\)家店,每个商品有一个标价.每天,都可能有某家商店进货,也可能有某人去购物.一个人在购物时,会于编号在区间\([L_i,R_i]\)的商店里挑选一件进货\(d_i\) ...