Flink概述| 配置
流处理技术的演变
在开源世界里,Apache Storm项目是流处理的先锋。Storm提供了低延迟的流处理,但是它为实时性付出了一些代价:很难实现高吞吐,并且其正确性没能达到通常所需的水平,换句话说,它并不能保证exactly-once,即便是它能够保证的正确性级别,其开销也相当大。
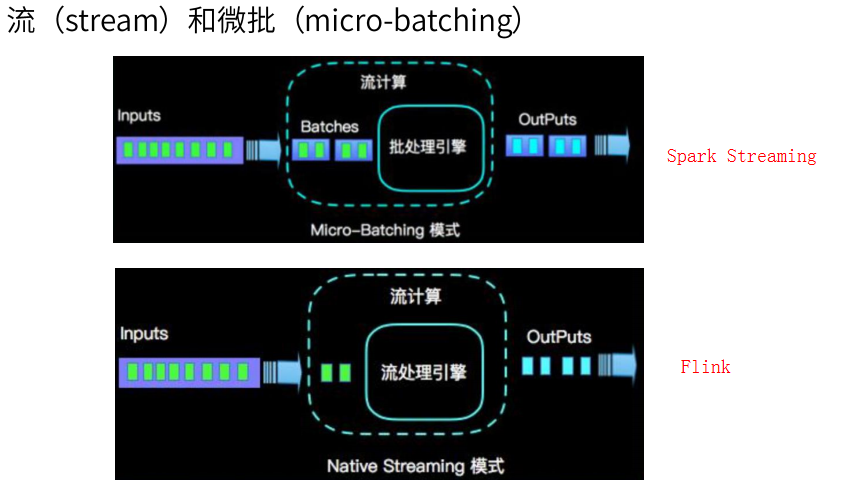
在低延迟和高吞吐的流处理系统中维持良好的容错性是非常困难的,但是为了得到有保障的准确状态,人们想到了一种替代方法:将连续时间中的流数据分割成一系列微小的批量作业。如果分割得足够小(即所谓的微批处理作业),计算就几乎可以实现真正的流处理。因为存在延迟,所以不可能做到完全实时,但是每个简单的应用程序都可以实现仅有几秒甚至几亚秒的延迟。这就是在Spark批处理引擎上运行的Spark Streaming所使用的方法。
更重要的是,使用微批处理方法,可以实现exactly-once语义,从而保障状态的一致性。如果一个微批处理失败了,它可以重新运行,这比连续的流处理方法更容易。Storm Trident是对Storm的延伸,它的底层流处理引擎就是基于微批处理方法来进行计算的,从而实现了exactly-once语义,但是在延迟性方面付出了很大的代价。
对于Storm Trident以及Spark Streaming等微批处理策略,只能根据批量作业时间的倍数进行分割,无法根据实际情况分割事件数据,并且,对于一些对延迟比较敏感的作业,往往需要开发者在写业务代码时花费大量精力来提升性能。这些灵活性和表现力方面的缺陷,使得这些微批处理策略开发速度变慢,运维成本变高。
于是,Flink出现了,这一技术框架可以避免上述弊端,并且拥有所需的诸多功能,还能按照连续事件高效地处理数据,Flink的部分特性如下图所示:
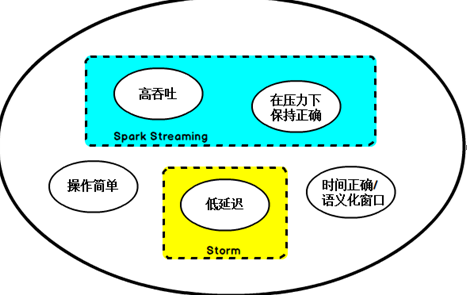
Fink

低延迟、高吞吐、结果的准确性和良好的容错性。
Flink主页在其顶部展示了该项目的理念:“Apache Flink是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架”。
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
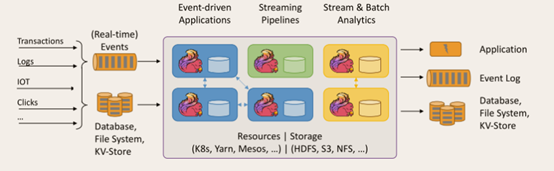
1. Flink的重要特点
① 事件驱动型(Event-driven)
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。比较典型的就是以kafka为代表的消息队列几乎都是事件驱动型应用。 事件驱动型如下图:
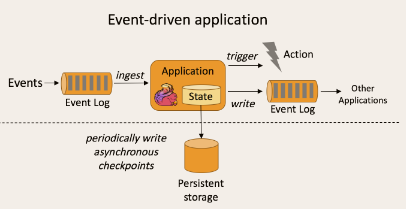
与之不同的就是SparkStreaming微批次如图:

② 流与批的世界观
批处理的特点是有界、持久、大量,非常适合需要访问全套记录才能完成的计算工作,一般用于离线统计。
流处理的特点是无界、实时, 无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。
在spark的世界观中,一切都是由批次组成的,离线数据是一个大批次,而实时数据是由一个一个无限的小批次组成的。
而在flink的世界观中,一切都是由流组成的,离线数据是有界限的流,实时数据是一个没有界限的流,这就是所谓的有界流和无界流。
无界数据流:无界数据流有一个开始但是没有结束,它们不会在生成时终止并提供数据,必须连续处理无界流,也就是说必须在获取后立即处理event。对于无界数据流我们无法等待所有数据都到达,因为输入是无界的,并且在任何时间点都不会完成。处理无界数据通常要求以特定顺序(例如事件发生的顺序)获取event,以便能够推断结果完整性。
有界数据流:有界数据流有明确定义的开始和结束,可以在执行任何计算之前通过获取所有数据来处理有界流,处理有界流不需要有序获取,因为可以始终对有界数据集进行排序,有界流的处理也称为批处理。
这种以流为世界观的架构,获得的最大好处就是具有极低的延迟。
③ 分层API
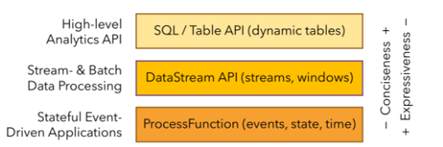
最底层级的抽象仅仅提供了有状态流,它将通过过程函数(Process Function)被嵌入到DataStream API中。底层过程函数(Process Function) 与 DataStream API 相集成,使其可以对某些特定的操作进行底层的抽象,它允许用户可以自由地处理来自一个或多个数据流的事件,并使用一致的容错的状态。除此之外,用户可以注册事件时间并处理时间回调,从而使程序可以处理复杂的计算。
大多数应用并不需要上述的底层抽象,而是针对核心API(Core APIs) 进行编程,比如DataStream API(有界或无界流数据)以及DataSet API(有界数据集)。这些API为数据处理提供了通用的构建模块,比如由用户定义的多种形式的转换(transformations),连接(joins),聚合(aggregations),窗口操作(windows)等等。
DataSet API 为有界数据集提供了额外的支持,例如循环与迭代。这些API处理的数据类型以类(classes)的形式由各自的编程语言所表示。
Table API 是以表为中心的声明式编程,其中表可能会动态变化(在表达流数据时)。Table API遵循(扩展的)关系模型:表有二维数据结构(schema)(类似于关系数据库中的表),同时API提供可比较的操作,例如select、project、join、group-by、aggregate等。Table API程序声明式地定义了什么逻辑操作应该执行,而不是准确地确定这些操作代码的看上去如何 。 尽管Table API可以通过多种类型的用户自定义函数(UDF)进行扩展,其仍不如核心API更具表达能力,但是使用起来却更加简洁(代码量更少)。除此之外,Table API程序在执行之前会经过内置优化器进行优化。
你可以在表与 DataStream/DataSet 之间无缝切换,以允许程序将 Table API 与 DataStream 以及 DataSet 混合使用。
Flink提供的最高层级的抽象是 SQL 。这一层抽象在语法与表达能力上与 Table API 类似,但是是以SQL查询表达式的形式表现程序。SQL抽象与Table API交互密切,同时SQL查询可以直接在Table API定义的表上执行。
④ 其他特点:
- 支持事件时间(event-time)和 处理时间(processing-time);
- 精确一次(exactly-once)的状态一致性保证;
- 低延迟,每秒处理数百万个事件,毫秒级延迟;
- 与众多常用存储系统的连接;
- 高可用,动态扩展,实现7 * 24小时全天候运行;

Flink集群搭建
Flink可以选择的部署方式有:
Local、Standalone(资源利用率低)、Yarn、Mesos、Docker、Kubernetes、AWS。
我们主要对Standalone模式和Yarn模式下的Flink集群部署进行分析。
Yarn模式安装
在官网下载1.10.0版本Flink(https://archive.apache.org/dist/flink/flink-1.10.0/)。
解压缩 flink-1.10.0-bin-scala_2.11.tgz,进入conf目录中。
1 修改安装目录下conf文件夹内的flink-conf.yaml配置文件,指定JobManager:
[kris@hadoop101 flink-1.10.]$ vim conf/flink-conf.yaml
jobmanager.rpc.address: hadoop101
2 修改安装目录下conf文件夹内的slave配置文件,指定TaskManager:
[kris@hadoop101 flink-1.10.]$ vim conf/slaves
hadoop102
hadoop103
3 将配置好的Flink目录分发给其他的两台节点:
[kris@hadoop101 module]$ xsync flink-1.10./
standalone模式和yarn模式这两种模式配置都一样;
①. standalone模式的启动:
[kris@hadoop101 flink-1.10.]$ bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hadoop101.
Starting taskexecutor daemon on host hadoop102.
Starting taskexecutor daemon on host hadoop103.
[kris@hadoop101 flink-1.10.]$ xcall.sh jps
----------hadoop101------------
Jps
StandaloneSessionClusterEntrypoint
----------hadoop102------------
Jps
TaskManagerRunner
----------hadoop103------------
Jps
TaskManagerRunner
关闭集群:
[kris@hadoop101 flink-1.10.]$ bin/stop-cluster.sh
http://hadoop101:8081 可以对flink集群和任务进行监控管理。
standalone模式的任务提交:
① 准备数据文件
[kris@hadoop101 flink-1.10.]$ vim data/input.txt
how are you
fine thank you
i am fine too thank you
② 把数据文件分发到taskmanage 机器中
由于读取数据是从本地磁盘读取,实际任务会被分发到taskmanage的机器中,所以要把目标文件分发。
[kris@hadoop101 flink-1.10.]$ xsync data/input.txt
③ 执行程序
[kris@hadoop101 flink-1.10.]$ bin/flink run -c com.xxx.fink.app.BatchWcApp Flink-1.0-SNAPSHOT-jar-with-dependencies.jar --input data/input.txt --output data/output.csv
Starting execution of program
(am,)
(are,)
(fine,)
(how,)
(i,)
(thank,)
(too,)
(you,)
Program execution finished
Job with JobID 09ffd619992aa6e53cc36743f213629c has finished.
Job Runtime: ms
④ 到目标文件夹中查看计算结果
注意:计算结果根据会保存到taskmanage的机器下,不会在jobmanage下
[kris@hadoop103 data]$ ll
总用量
-rw-rw-r--. kris kris 5月 : input.txt
-rw-rw-r--. kris kris 5月 : output.csv
⑤ 在web控制台查看计算过程 http://hadoop101:8081/
②. Yarn模式的启动和运行:
Flink提供了两种在yarn上运行的模式,分别为Session-Cluster和Per-Job-Cluster模式。
1) Session-cluster 模式:
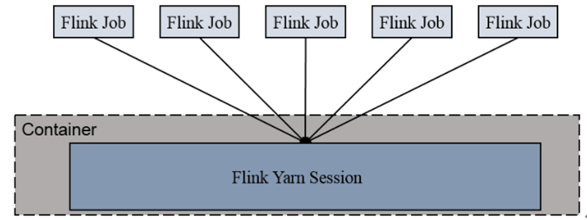
Session-Cluster模式需要先启动集群,然后再提交作业,接着会向yarn申请一块空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到yarn中的其中一个作业执行完成后,释放了资源,下个作业才会正常提交。所有作业共享Dispatcher和ResourceManager;共享资源;适合规模小执行时间短的作业。
在yarn中初始化一个flink集群,开辟指定的资源,以后提交任务都向这里提交。这个flink集群会常驻在yarn集群中,除非手工停止。
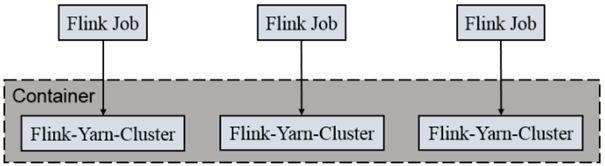
2) Per-Job-Cluster 模式:
一个Job会对应一个集群,每提交一个作业会根据自身的情况,都会单独向yarn申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享Dispatcher和ResourceManager,按需接受资源申请;适合规模大长时间运行的作业。
每次提交都会创建一个新的flink集群,任务之间互相独立,互不影响,方便管理。任务执行完成之后创建的集群也会消失。
Yarn-Session模式
- 明确虚拟机中已经设置好了环境变量HADOOP_HOME。
- 启动Hadoop集群(HDFS和Yarn)。
- 在hadoop101节点提交Yarn-Session,使用安装目录下bin目录中的yarn-session.sh脚本进行提交:
[kris@hadoop101 flink-1.10.0]$ bin/yarn-session.sh -n -s -jm -tm -nm test -d
Yarn-session模式提交就不看配置文件了,默认以命令行上的参数为准,
其中:
-n(--container):TaskManager的数量。
-s(--slots): 每个TaskManager的slot数量,默认一个slot一个core(CPU),默认每个taskmanager的slot的个数为1,有时可以多一些taskmanager,做冗余。建议设置为每个机器的CPU核数,跑在slot上的一个任务即一个线程。 比如4核CPU,-s 8,则多个slot共享一个cpu;
-jm:JobManager的内存(单位MB)。
-tm:每个taskmanager的内存(单位MB)。
-nm:yarn 的appName(现在yarn的ui上的名字)。
-d:后台执行。
启动后查看Yarn的Web页面,可以看到刚才提交的会话:

http://hadoop101:48031 可查看页面
一旦session创建成功,就可以使用./bin/flink工具向集群提交任务。
最好写全路径:
[kris@hadoop101 flink-1.10.0]$ bin/flink run -m yarn-cluster -c com.xxx.fink.app.BatchWcApp Flink-1.0-SNAPSHOT-jar-with-dependencies.jar --input data/input.txt --output data/output-yarn.csv
INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - YARN application has been deployed successfully.
Starting execution of program
(am,)
(are,)
(fine,)
(how,)
(i,)
(thank,)
(too,)
(you,)
Program execution finished
Job with JobID 281d37c037a4e56dbc558ac21b8043d9 has finished.
Job Runtime: ms
================================
查看运行最后结果在hadoop103机器上面: /opt/moudle/flink1.10.0/data/output-yarn.csv
在yarn上运行一个官方 flink job的wordCount
[kris@hadoop101 flink-1.10.]$ bin/flink run -m yarn-cluster examples/batch/WordCount.jar
(would,)
(wrong,)
(you,)
Program execution finished
Job with JobID ed51d12a4992c907b9b7e4cb2a28dc05 has finished.
Job Runtime: ms
Accumulator Results:
- 55207241aa959f05f454d610997e5e51 (java.util.ArrayList) [ elements]
去yarn控制台查看任务状态

在提交Session的节点查看进程:
----------hadoop101------------
Jps
NodeManager
NameNode
DataNode
FlinkYarnSessionCli
YarnSessionClusterEntrypoint
----------hadoop102------------
Jps
NodeManager
DataNode
ResourceManager
----------hadoop103------------
Jps
NodeManager
DataNode
SecondaryNameNode
[kris@hadoop101 bin]$ yarn application -list
application_1572752436054_0001 test Apache Flink kris default RUNNING UNDEFINED % http://hadoop101:48031 [kris@hadoop101 bin]$ yarn application -kill application_1572752436054_0001
// :: INFO client.RMProxy: Connecting to ResourceManager at hadoop102/192.168.1.102:
Killing application application_1572752436054_0001
页面提交jar包:
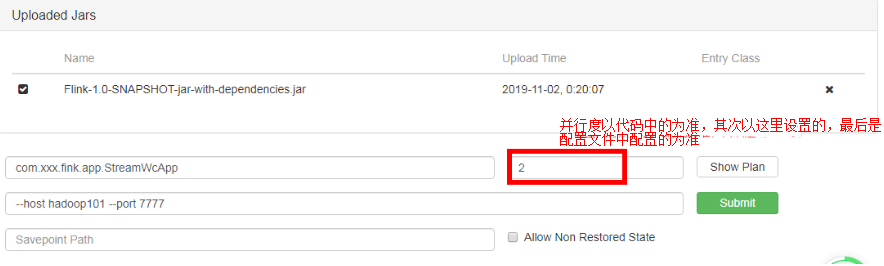
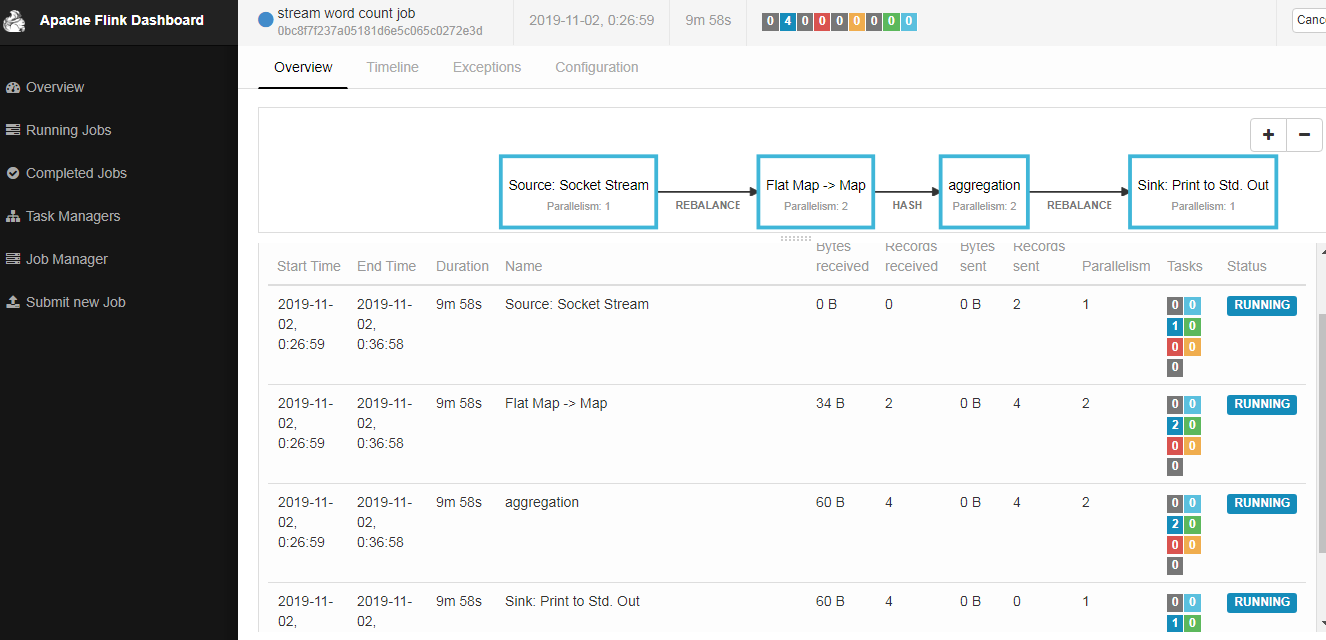
sink端,代码里边直接设置了并行度为1;前边算子的并行度,每个算子都可以单独设置并行度,(代码中没设置,以页面提交的并行度为准);
socket端不能是并行的;
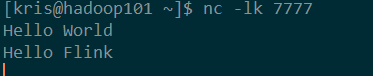
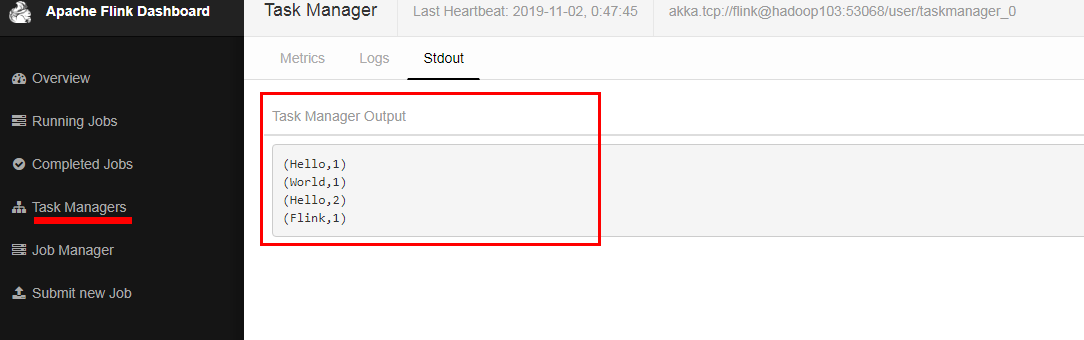
命令行提交:
启动yarn-session:
[kris@hadoop101 flink-1.7.]$ bin/yarn-session.sh -n -s -jm -tm -nm test -d

[kris@hadoop101 flink-1.7.]$ bin/flink run -c com.xxx.fink.app.StreamWcApp -p /opt/module/flink-1.7./Flink-1.0-SNAPSHOT-jar-with-dependencies.jar --host hadoop101 --port
INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Found application JobManager host name 'hadoop101' and port '' from supplied application id 'application_1572752436054_0001'
Starting execution of program
[kris@hadoop101 ~]$ xcall.sh jps
----------hadoop101------------
CliFrontend ##是正在运行的jar包
Jps
NodeManager
NameNode
DataNode
FlinkYarnSessionCli
YarnSessionClusterEntrypoint
----------hadoop102------------
Jps
NodeManager
DataNode
ResourceManager
----------hadoop103------------
Jps
YarnTaskExecutorRunner
NodeManager
DataNode
SecondaryNameNode

查询
[kris@hadoop101 flink-1.7.]$ bin/flink list
INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Found application JobManager host name 'hadoop101' and port '' from supplied application id 'application_1572674361568_0001'
Waiting for response...
------------------ Running/Restarting Jobs -------------------
02.11. :: : 146b2bf2349e2fbe8596433eec572c25 : stream word count job (RUNNING)
--------------------------------------------------------------
No scheduled jobs.
取消任务
[kris@hadoop101 flink-1.7.]$ bin/flink cancel 146b2bf2349e2fbe8596433eec572c25
Per Job Cluster模式
1) 启动hadoop集群
2) 不启动yarn-session,直接执行job
./flink run –m yarn-cluster -c com.xxx.wc.StreamWordCount FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar --host hadoop101 –port
Flink概述| 配置的更多相关文章
- Apache Shiro系列之五,概述 —— 配置
Shiro设计的初衷就是可以运行于任何环境:无论是简单的命令行应用程序还是复杂的企业集群应用.由于运行环境的多样性,所以有多种配置机制可用于配置,本节我们将介绍Shiro内核支持的这几种配置机制. ...
- kerberos系列之flink认证配置
大数据安全系列的其它文章 https://www.cnblogs.com/bainianminguo/p/12548076.html-----------安装kerberos https://www. ...
- <译>Flink官方文档-Flink概述
Overview This documentation is for Apache Flink version 1.0-SNAPSHOT, which is the current developme ...
- yum概述配置
YUM(全称为 Yellow dog Updater, Modified)是一个在Fedora和RedHat以及CentOS中的Shell前端软件包管理器.基于RPM包管理,能够从指定的服务器自动下载 ...
- 三十八. 分库分表概述 配置mycat
1.搭建mycat 分片服务器 数据库主机 192.168.4.55 使用db1库存储数据 数据库主机 192.168.4.56 使用db2库存储数据 主机 192.168.4.54 运行myca ...
- Flink概述
计算引擎 大数据计算引擎分为离线计算和实时计算,离线计算就是我们通常说的批计算,代表是Hadoop MapReduce.Hive等大数据技术.实时计算也被称作流计算,代表是Storm.Spark St ...
- 「Flink」配置使用Flink调试WebUI
很多时候,我们在IDE中编写Flink代码,我们希望能够查看到Web UI,从而来了解Flink程序的运行情况.按照以下步骤操作即可,亲测有效. 1.添加Maven依赖 <dependency& ...
- Flink的安装配置
一. Flink的下载 安装包下载地址:http://flink.apache.org/downloads.html ,选择对应Hadoop的Flink版本下载 [admin@node21 soft ...
- Flink简介及使用
一.Flink概述 官网:https://flink.apache.org/ mapreduce-->maxcompute HBase-->部门 quickBI DataV Hive--& ...
随机推荐
- Mint UI 之loadmore组件的坑:内部元素头部被遮挡了一部分
前端经常会遇到数据分页加载的需求,mint-ui组件为大家提供了loadmore组件 但是我在使用的时候,遇到了一个问题:写好布局和样式以及逻辑之后,我的mt-loadmore标签的头部总是不顶在父元 ...
- Linux---centos7.0安装、配置
参考:https://blog.csdn.net/qq_37057095/article/details/81240450
- ELK-logstash基本用法
一:logstash介绍 Logstash在elk系统中为数据存储,报表查询和日志解析创建了一个功能强大的管道链.Logstash提供了多种多样的 input,filters,codecs和outpu ...
- Node.js:深入浅出 http 与 stream
原文链接:https://github.com/iNuanfeng/blog/issues/4 作者:暖风叔叔 前言 stream(流)是Node.js提供的又一个仅在服务区端可用的模块,流是一种抽象 ...
- Hadoop相关问题解决
Hadoop相关问题解决 Hive 1.查询hivemeta信息,查到的numRows为-1 集群厂商 集群版本 是否高可用 是否开启认证 cdh 不限 不限 不限 在hivemeta库中可以通过以下 ...
- 网络配置工具iproute2和net-tools的基本原理和基本使用方法
这是网络程序设计课程的第一次作业的博客,由于还是小白,分享的内容都是比较基础的东西,希望看到的各位同学可以提出指导意见,必将虚心听取. 这次分享的内容是网络配置工具iproute2和net-tools ...
- java基础面向对象总结(一)
年底了,总结下知识点和遇到过的面试题目. 1,如何理解面相对象. ‘万物皆对象’说的没错,听起来挺反感的,问一个说一个.有些话觉得用自己的话讲出来肯俗点,但可以证明你理解了一点.我理解的是:之所以叫面 ...
- 使用littlefs-fuse在PC端调试littlefs文件系统
背景 littlefs是arm面向嵌入式设备推出的一款掉电安全的小型文件系统,具有抗掉电,动态磨损均衡,RAM/ROM需求少等特点,具体介绍可见 https://github.com/ARMmbed/ ...
- Caffe源码-Net类(下)
net.cpp部分源码 // 接着上一篇博客的介绍,此部分为Net类中前向反向计算函数,以及一些与HDF5文件或proto文件相互转换的函数. template <typename Dtype& ...
- [ASP.NET Core 3框架揭秘] 跨平台开发体验: Linux
如果想体验Linux环境下开发.NET Core应用,我们有多种选择.一种就是在一台物理机上安装原生的Linux,我们可以根据自身的喜好选择某种Linux Distribution,目前来说像RHEL ...