论文阅读:Relation Structure-Aware Heterogeneous Information Network Embedding
Relation Structure-Aware Heterogeneous Information Network Embedding(RHINE) (AAAI 2019)
本文结构
- (1) 解决问题
- (2) 主要贡献
- (3) 算法原理
- (4) 实验结果
- (5) 参考文献
在文献阅读的基础上加入了自己的理解,为文献阅读笔记,如有错误望不吝指出。
(1) 解决问题
现存的HIN表征算法通常一个模型用到底,没有对不同关系进行区分,这不可避免地会影响网络表征的能力。
(2) 主要贡献
Contribution 1. 是第一个来探索HIN中关系区别的工作,并且提出了两种标准将HIN关系归类为两种,ARs (one centered by another) 和 IRs (peer to peer)。
Contribution 2. 提出了RHINE算法,为两类不同的关系都各自建立了模型,并且可以很容易联合在一起优化。
(3) 算法原理
HIN中的两类关系:
<1> ARs (Affiliation Relations,one-centered-by-another)
这类关系描述一个节点以另外一个节点为中心,一般指隶属关系,如PC关系,paper属于某个会议,这类关系的特征是一类节点度大一类节点度小,即多对一的关系。
<2> IRs (Interaction Relations,peer-to-peer)
这类关系一般指两个节点是对等关系,两个节点之间存在互动关系,如AP关系,作者写了一篇论文,这类关系的特征是两类节点的度差不多,即一对一关系。
HIN中的关系分类(两个度量指标):
<1> 基于度的度量指标
给定节点关系元组(u, r, v),以下公式度量其关系类别。

其中,t_u 表示节点类型,d_tu为平均度,即网络中存在的关系r总数 / 节点类型为t_u 的节点总数。
D(r) 越大表示两类节点的平均度差异越大,即该关系r更可能是ARs,反之D(r) 越小则表示两类节点的平均度差不多,即该关系r更可能是IRs。
<2> 基于网络稀疏度的度量指标
给定节点关系元组(u, r, v),以下公式度量其关系类别。

其中,N_r表示网络中关系r的数目,N_tu为网络中节点类型为t_u 的节点总数。
S(r) 越大表示两类节点间的联系(边)更紧密,即该关系更可能是多对一的ARs,反之S(r) 越小则表示两类节点间的联系(边)没那么紧密,即该关系r更可能是一对一的IRs。
RHINE的基本思想:为两类关系分别建立模型,最后联合优化。
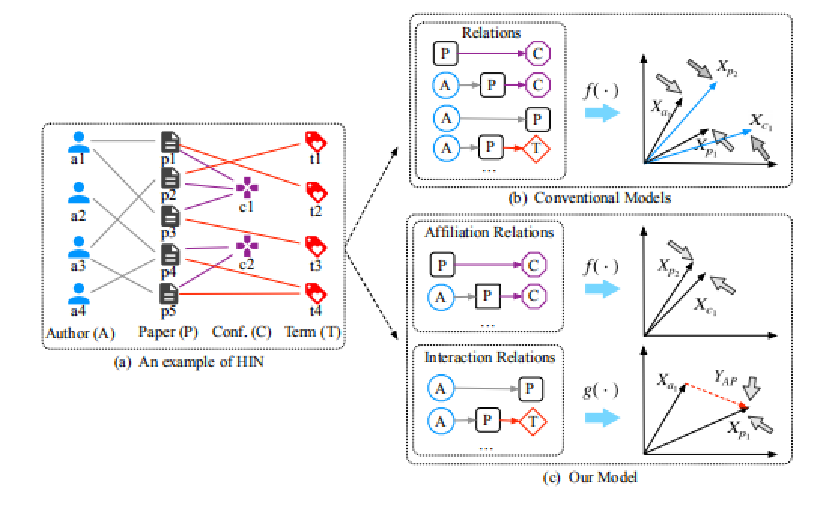
如上图(b)所示,传统HIN算法将一个模型用于捕获网络中的所有关系以此来做网络嵌入。而RHINE不同,如上图(c)所示,RHINE算法分别为两类关系建立模型。
<1> 为ARs关系建立模型:
对于ARs关系s,(p, s, q),最小化p、q在向量空间中的欧式距离,计算如下:

理由: 对于ARs关系,一个节点隶属于另一个节点则它们俩共享相类似的性质,自然应该在表示空间中的距离更加相近,而欧式距离可以直接反映向量空间中两个向量的直线距离。
使用 margin-based loss 作为损失函数,建立模型如下:
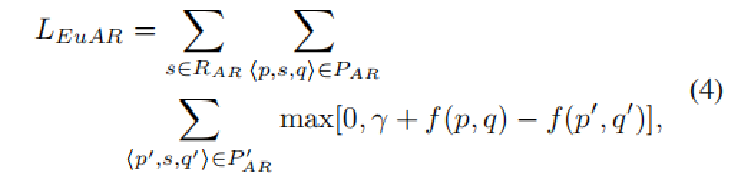
P_AR 是正样本关系三元组集合,P'_AR 是负样本关系三元组集合。
该函数的作用是使得正样本中节点对的向量尽可能相近,使得负样本中节点对的向量尽可能远离。
<2> 为IRs关系建立模型:
对于IRs关系r,(u, r, v),最小化u、v在向量空间中的平移距离(曼哈顿距离),计算如下:

理由: 对于IRs关系,两个节点是对等结构的关系,可能作者认为IRs关系没有ARs关系联系那么强,因此采用曼哈顿距离建模,并且是最小化X_u+Y_r 与 X_v 的差异。
使用 margin-based loss 作为损失函数,建立模型如下:

<3> 最终总的目标函数如下:
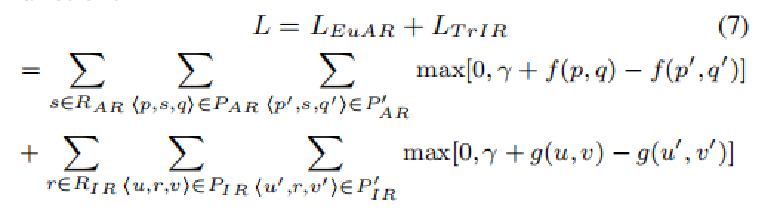
即两个目标函数简单相加在一起,联合优化,正样本为在图中依概率采样关系,负样本为将正样本中的某一端节点替换为随机节点得到。
(4) 实验结果
<1> 数据集:
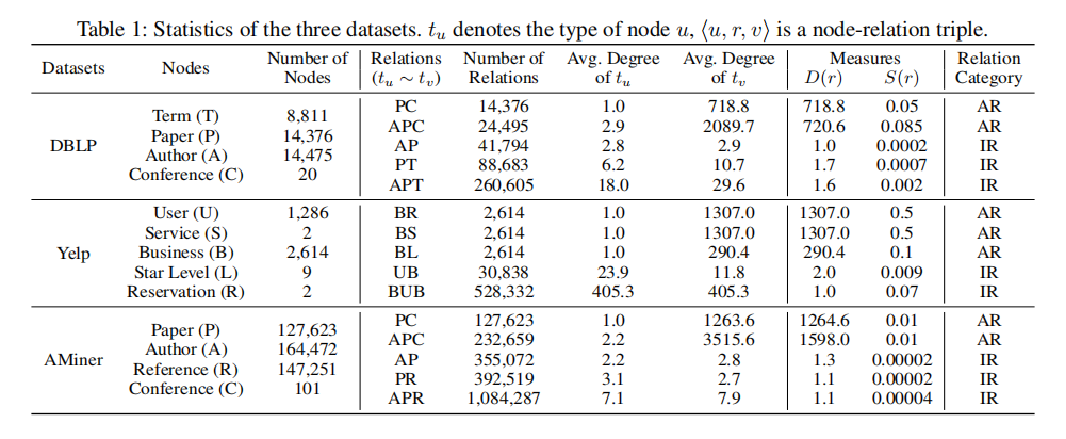
<2> 对比算法:
① DeepWalk
② LINE
③ PTE
④ ESim
⑤ HIN2Vec
⑥ Metapath2vec
<3> 节点聚类任务:
聚类算法: K-means
评测指标: NMI
实验结果:

在所有数据集上都优于对比算法。
<4> 链路预测任务:
评测指标: AUC,F1 score
实验结果:
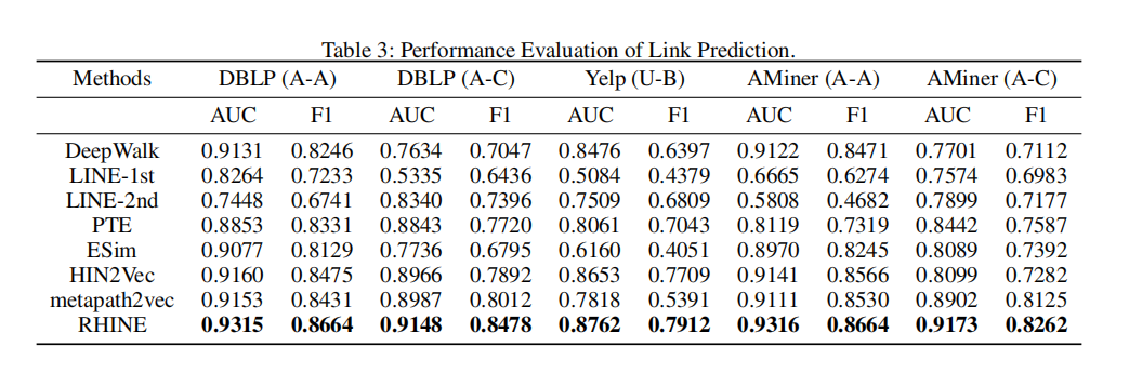
在所有数据集上都优于对比算法。
<5> 节点分类任务:
分类算法: Logistic classifier
评测指标: Micro-F1,Macro-F1
实验结果:

在大部分数据集上都优于对比算法,其中AMiner数据集上性能不如HIN2Vec,原因是对于过度捕获了PR、APR关系,因为作者写了一篇论文可能引用多篇不同领域的文献,因此引入了误差。
<6> 验证模型策略的有效性实验
实验算法:
RHINE_Eu: 只利用欧式距离来做嵌入,不区分关系类型。
RHINE_Tr: 只利用曼哈顿距离来做嵌入,不区分关系类型。
RHINE_RE: ARs关系采用曼哈顿距离,IRs关系采用欧式距离。
RHINE: 即论文所提算法,ARs关系采用欧式距离,IRs关系采用曼哈顿距离。
实验结果:
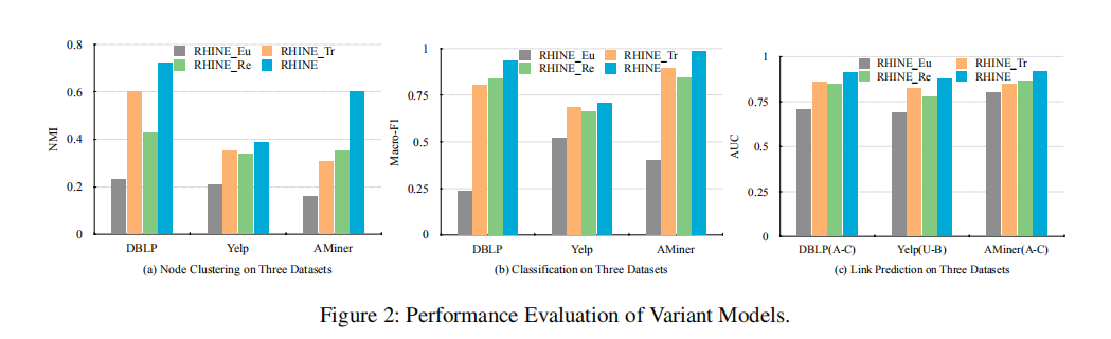
论文所提策略是有效的,图中效果最好的。
<7> 可视化实验(仅对论文节点)
实验结果:

RHINE算法不但能清晰看出四类节点,并且类簇之间的边界也是非常清晰的。
<8> 参数分析
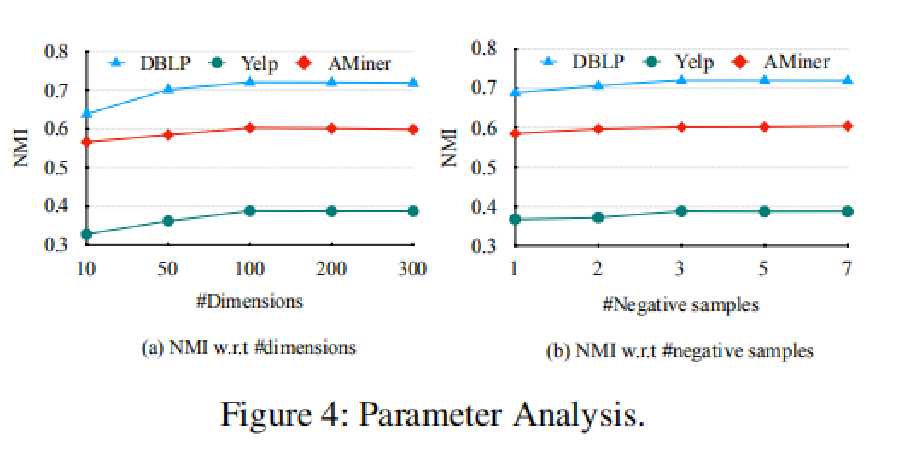
如图(a)所示,表征向量维度在100以后趋于稳定,论文中向量维度选择为100。
如图(b)所示,负样本数在3之后趋于稳定,论文中负样本数选择为3。
(5) 参考文献
1、Relation Structure-Aware Heterogeneous Information Network Embedding. Yuanfu Lu, Chuan Shi, Linmei Hu, Zhiyuan Liu. AAAI 2019.
论文阅读:Relation Structure-Aware Heterogeneous Information Network Embedding的更多相关文章
- 论文阅读 GloDyNE Global Topology Preserving Dynamic Network Embedding
11 GloDyNE Global Topology Preserving Dynamic Network Embedding link:http://arxiv.org/abs/2008.01935 ...
- 论文解读(Line)《LINE: Large-scale Information Network Embedding》
论文题目:<LINE: Large-scale Information Network Embedding>发表时间: KDD 2015论文作者: Jian Tang, Meng Qu ...
- [论文阅读笔记] Community aware random walk for network embedding
[论文阅读笔记] Community aware random walk for network embedding 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 先前许多算法都 ...
- 【论文阅读】Socially aware motion planning with deep reinforcement learning-annotated
目录 摘要部分: I. Introduction 介绍 II. Background 背景 A. Collision Avoidance with DRL B. Characterization of ...
- 【论文阅读】DSDNet Deep Structured self-Driving Network
前言引用 [2] DSDNet Deep Structured self-Driving Network Wenyuan Zeng, Shenlong Wang, Renjie Liao, Yun C ...
- 论文阅读 | RefineDet:Single-Shot Refinement Neural Network for Object Detection
论文链接:https://arxiv.org/abs/1711.06897 代码链接:https://github.com/sfzhang15/RefineDet 摘要 RefineDet是CVPR ...
- 论文阅读 | Towards a Robust Deep Neural Network in Text Domain A Survey
摘要 这篇文章主要总结文本中的对抗样本,包括器中的攻击方法和防御方法,比较它们的优缺点. 最后给出这个领域的挑战和发展方向. 1 介绍 对抗样本有两个核心:一是扰动足够小:二是可以成功欺骗网络. 所有 ...
- 论文阅读:Elastic Scaling of Stateful Network Functions
摘要: 弹性伸缩是NFV的核心承诺,但在实际应用中却很难实现.出现这种困难的原因是大多数网络函数(NFS)是有状态的,并且这种状态需要在NF实例之间共享.在满足NFS上的吞吐量和延迟要求的同时实现状态 ...
- 论文阅读:FlexGate: High-performance Heterogeneous Gateway in Data Centers
摘要: 大型数据中心通过边界上的网关对每个传入的数据包执行一系列的网络功能,例如,ACL被部署来阻止不合格的流量,而速率限制被用于防止供应商过度使用带宽,但是由于流量的规模巨大,给网关的设计和部署带来 ...
随机推荐
- Webpack 定义process.env的时机
定义 process.env的时机 如果已经提取了公共配置文件 webpack.common.js 分别定义了开发配置webpack.dev.js和生产配置webpack.prod.js 在webpa ...
- Vue 图片压缩上传: element-ui + lrz
步骤 安装依赖包 npm install --save lrz 在main.js里引入 import lrz from 'lrz' 封装 compress函数 封装上传组件 upload-image ...
- 聊聊MySQL常用的4种主从复制架构
目录 一主多从复制架构 多级复制架构 双主(Dual Master)复制架构 多源(Multi-Source)复制架构 如何优化主从延迟问题? 复制的4中常见架构有一主多从复制架构.多级复制架构.双主 ...
- Linux下mv命令高级用法
mv 也是 Linux 下一个使用频率非常高的命令,但除了一些基本用法,你还知道它的哪些高级用法呢? 1. 基本用法 移动一个/多个文件: 移动一个/多个目录: 重命名文件/目录. 这些都是很基本的用 ...
- 笔记:Linux用户管理(补充)、权限管理、内存管理、网络管理、渗透常用命令
一.用户管理(补充) 添加用户:useradd [选项] 用户名 useradd -u 5000 -g demogroup -G root -d /home/demo -s /bin/bash dem ...
- TS流解码过程-ES-PES-PTS-DTS
转载自http://blog.chinaunix.net/uid-9688646-id-1998407.html TS 流解码过程: 1. 获取TS中的PAT 2. 获取TS中的PMT 3. 根据PM ...
- Python 控制台输出时刷新当前行内容而不是输出新行
需求目标 执行Python程序的时候在控制台输出内容的时候只显示一行,然后自动刷新内容,像这样: Downloading File FooFile.txt [%] 而不是这样: Downloading ...
- CentOS7 系统基于Vim8搭建Go语言开发环境
链接:https://pdf.us/2018/11/10/2194.html 问题1:vim-go: could not find 'gopls'. Run :GoInstallBinaries to ...
- WordCount of Software Engineering
1.Github项目地址:https://github.com/BayardM/WordCount 2.PSP表格(before): PSP2.1 Personal Software Process ...
- MD笔记
1.力场中的例子电荷是有效电荷(clayff),有别于化学式中的电荷. 2.游离状态的阳离子(如层间阳离子)的电荷不能变动:而Al-O八面体.Si-O四面体中的离子(Al.Si等)电荷可以微调. 3. ...