知识图谱和neo4j的基本操作
一.知识图谱的简介
1.知识图谱是什么
知识图谱本质上是语义网络(Semantic Network)的知识库
可以理解为一个关系图网络。
2.什么是图
图(Graph)是由节点(Vertex)和边(Edge)来构成,多关系图一般包含多种类型的节点和多种类型的边。
3.什么是Schema
限定待加入知识图谱数据的格式;相当于某个领域内的数据模型,包含了该领域内有意义的概念类型以及这些类型的属性
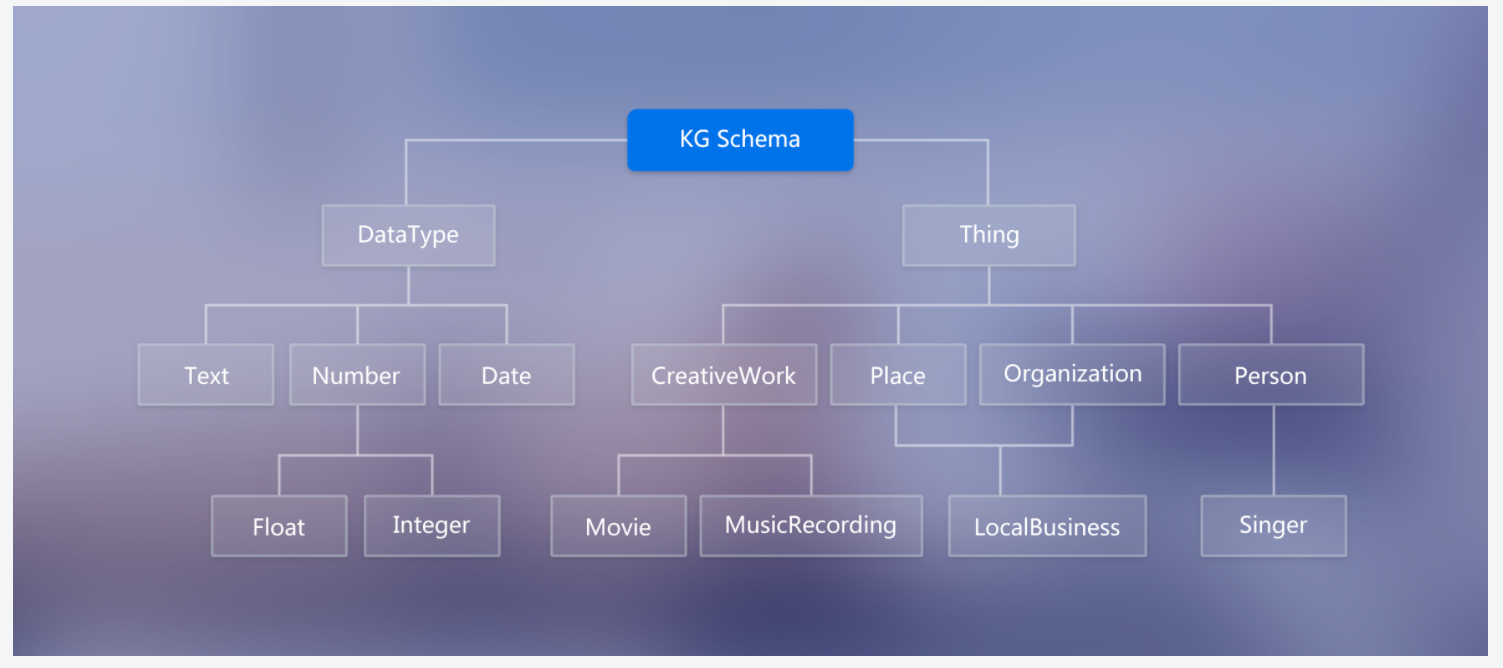
二.知识图谱的构建
1.数据来源
结构化数据和非结构化数据,前者可能是本地数据库中的信息,后者主要是在网页上抓取的信息。
2.涉及的技术
命名实体识别,关系抽取等自然语言处理技术。
三.知识图谱的存储
- 一种是基于RDF的存储;
- 另一种是基于图数据库的存储。
RDF一个重要的设计原则是数据的易发布以及共享,图数据库则把重点放在了高效的图查询和搜索上。其次,RDF以三元组的方式来存储数据而且不包含属性信息,但图数据库一般以属性图为基本的表示形式,所以实体和关系可以包含属性,这就意味着更容易表达现实的业务场景。其中Neo4j系统目前仍是使用率最高的图数据库,它拥有活跃的社区,而且系统本身的查询效率高,但唯一的不足就是不支持准分布式。
四.Neo4j的介绍
Neo4j为常用的图数据库之一。
Neo4j的安装很简单,先到官方网站Neo4j下载,下载完压缩包之后直接解压缩,然后配置好环境变量,可以按照这篇博客的方法https://www.cnblogs.com/jpfss/p/10874303.html。
之后我们在浏览器内输入http://127.0.0.1:7474/browser/就进入了Neo4j的界面。

五.Neo4j的基本操作
//删库
MATCH (n) DETACH DELETE n
//创建人物结点
CREATE (n:Person {name:'John'}) RETURN n
//创建地区结点
CREATE (n:Location {city:'Miami', state:'FL'})
//创建朋友关系
MATCH (a:Person {name:'Liz'}),
(b:Person {name:'Mike'})
MERGE (a)-[:FRIENDS]->(b)
//创建出生地关系
MATCH (a:Person {name:'John'}), (b:Location {city:'Boston'}) MERGE (a)-[:BORN_IN {year:1978}]->(b);
MATCH (a:Person {name:'Liz'}), (b:Location {city:'Boston'}) MERGE (a)-[:BORN_IN {year:1981}]->(b);
//按照出生地查询
MATCH (a:Person)-[:BORN_IN]->(b:Location {city:'Boston'}) RETURN a,b
//查询所有对外有关系的结点和类型
MATCH (a)-[r]->() RETURN a.name, type(r)
//查询所有婚姻关系的结点
MATCH (n)-[:MARRIED]-() RETURN n
//查找某人朋友的朋友
MATCH (a:Person {name:'Mike'})-[r1:FRIENDS]-()-[r2:FRIENDS]-(friend_of_a_friend) RETURN friend_of_a_friend.name AS fofName
//增加或者修改结点属性
MATCH (a:Person {name:'Liz'}) SET a.age=34
//删除结点属性
MATCH (a:Person {name:'Mike'}) SET a.test='test';
MATCH (a:Person {name:'Mike'}) REMOVE a.test;
六.在python中操纵neo4j
1.neo4j模块
# step 1:导入 Neo4j 驱动包
from neo4j import GraphDatabase
# step 2:连接 Neo4j 图数据库
driver = GraphDatabase.driver("bolt://localhost:7687", auth=("neo4j", "password"))
# 添加 关系 函数
def add_friend(tx, name, friend_name):
tx.run("MERGE (a:Person {name: $name}) "
"MERGE (a)-[:KNOWS]->(friend:Person {name: $friend_name})",
name=name, friend_name=friend_name)
# 定义 关系函数
def print_friends(tx, name):
for record in tx.run("MATCH (a:Person)-[:KNOWS]->(friend) WHERE a.name = $name "
"RETURN friend.name ORDER BY friend.name", name=name):
print(record["friend.name"])
# step 3:运行
with driver.session() as session:
session.write_transaction(add_friend, "Arthur", "Guinevere")
session.write_transaction(add_friend, "Arthur", "Lancelot")
session.write_transaction(add_friend, "Arthur", "Merlin")
session.read_transaction(print_friends, "Arthur")
注意这里的密码要改成自己的,否则无法正常登陆。运行完上面的脚本后,就出现了如下的结点和边:

2.py2neo模块
# step 1:导包
from py2neo import Graph, Node, Relationship # step 2:构建图
g = Graph("http://localhost:7474",auth=("neo4j","password"))
# step 3:创建节点
tx = g.begin()
a = Node("Person", name="Alice")
tx.create(a)
b = Node("Person", name="Bob")
# step 4:创建边
ab = Relationship(a, "KNOWS", b)
# step 5:运行
tx.create(ab)
tx.commit()
知识图谱和neo4j的基本操作的更多相关文章
- 简单的知识图谱,neo4j+python
因为研究方向是知识图谱,就有兴致想要构建一个简单的知识图谱,就在网上查找了一下,参考了neo4j搭建简单的金融知识图谱的思想,就着手从零开始构建. 1.首先就要考虑数据的获得,因为之前没有接触过爬虫之 ...
- 知识图谱实战开发案例剖析-番外篇(1)- Neo4j是否支持按照边权重加粗和大数量展示
一.前言 本文是<知识图谱实战开发案例完全剖析>系列文章和网易云视频课程的番外篇,主要记录学员在知识图谱等相关内容的学习 过程中,提出的共性问题进行展开讨论.该部分内容原始内容记录在网易云 ...
- springboot2.0+Neo4j+d3.js构建知识图谱
Welcome to the Neo4j wiki! 初衷这是一个知识图谱构建工具,最开始是对产品和领导为了做ppt临时要求配合做图谱展示的不厌其烦,做着做着就抽出一个目前看着还算通用的小工具 技术栈 ...
- [知识图谱]Neo4j知识图谱构建(neo4j-python-pandas-py2neo-v3)
neo4j-python-pandas-py2neo-v3 利用pandas将excel中数据抽取,以三元组形式加载到neo4j数据库中构建相关知识图谱 Neo4j知识图谱构建 1.运行环境: pyt ...
- [知识图谱]利用py2neo从Neo4j数据库获取数据
# -*- coding: utf-8 -*- from py2neo import Graph import json import re class Neo4jToJson(object): &q ...
- 知识图谱之图数据库Neo4j
知识图谱中的知识是通过RDF结构来进行表示的,其基本单元是事实.每个事实是一个三元组(S, P, O),在实际系统中,按照存储方式的不同,知识图谱的存储可以分为基于表结构的存储和基于图结构的存储. 基 ...
- 知识图谱里的知识存储:neo4j的介绍和使用
一般情况下,我们使用数据库查找事物间的联系的时候,只需要短程关系的查询(两层以内的关联).当需要进行更长程的,更广范围的关系查询时,就需要图数据库的功能. 而随着社交.电商.金融.零售.物联网等行 ...
- 仿Neo4j里的知识图谱,利用d3+vue开发的一个网络拓扑图
项目需要画一个类似知识图谱的节点关系图. 一开始用的是echart画的. 根据https://gallery.echartsjs.com/editor.html?c=xH1Rkt3hkb,成功画出简单 ...
- Neo4j学习——基本操作(一)
由于开始学习知识图谱,因此需要涉及到neo4j的使用一.介绍neo4j是一个图形数据库基于Java开发而成,因此需要配置jvm才可以运行配置请参考我前面的一篇blog:https://www.cnbl ...
随机推荐
- 上传到github
我是为了自己下次不用再找github上传的地方了,索性就复制了一篇 转载于 https://blog.csdn.net/m0_37725003/article/details/80904824 首先你 ...
- WPF中DatePiker值绑定以及精简查询
WPF中DatePiker值绑定以及精简查询 1.WPF中DatePiker值绑定 Xaml中值绑定使用Text <DatePicker Text="{Binding strMinDa ...
- vue2中$emit $on $off实现组件之间的联动,绝对有你想了解的
在vue2开发中,你肯定会遇到组件之间联动的问题,现在我们就来说说哪个神奇的指令可以满足我们的需求. 一.先上实例: 需求:点击A组件或者B组件可以使C组件的名称相应发生改变,同样,点击A组件也会使对 ...
- hive实例的使用
一.hive用本地文件进行词频统计 1.准备本地txt文件 2.启动hadoop,启动hive 3.创建数据库,创建文本表 4.映射本地文件的数据到文本 5.hql语句进行词频统计交将结果保存到结果表 ...
- [python学习手册-笔记]004.动态类型
004.动态类型 ❝ 本系列文章是我个人学习<python学习手册(第五版)>的学习笔记,其中大部分内容为该书的总结和个人理解,小部分内容为相关知识点的扩展. 非商业用途转载请注明作者和出 ...
- SpringBoot基于JustAuth实现第三方授权登录
1. 简介 随着科技时代日渐繁荣,越来越多的应用融入我们的生活.不同的应用系统不同的用户密码,造成了极差的用户体验.要是能使用常见的应用账号实现全应用的认证登录,将会更加促进应用产品的推广,为生活 ...
- 如何用Python 制作词云-对1000首古诗做词云分析
公号:码农充电站pro 主页:https://codeshellme.github.io 今天来介绍一下如何使用 Python 制作词云. 词云又叫文字云,它可以统计文本中频率较高的词,并将这些词可视 ...
- Spring Boot 启动事件和监听器,太强大了!
大家都知道,在 Spring 框架中事件和监听无处不在,打通了 Spring 框架的任督二脉,事件和监听也是 Spring 框架必学的核心知识之一. 一般来说,我们很少会使用到应用程序事件,但我们也不 ...
- DataGrid 字体垂直居中
如果用DataGridTextColumn作为DataGrid的列,字体垂直居中需要这样设置: <Style x:Key="Body_Content_DataGrid_Centerin ...
- 安装nodejs 版本控制器
安装下载地址: https://pan.baidu.com/s/1Ed_IPDTOHxR9NShUEau-ZA 下载好后,放在安装nodejs的文件夹下 然后敲cmd,进入安装nodejs的文件夹下. ...