SCIP:构造数据抽象--数据结构中队列与树的解释
现在到了数学抽象中最关键的一步:让我们忘记这些符号所表示的对象。不应该在这里停滞不前,有许多操作可以应用于这些符号,而根本不必考虑它们到底代表着什么东西。
--Hermann Weyi 《思维的数学方式》
构造数据抽象
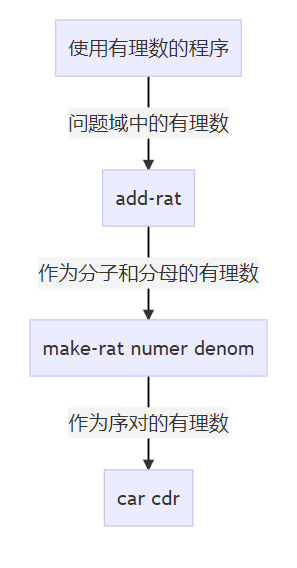
现在考虑一个完成有理数算术的系统,可以设想一个运算add-rat,以两个有理数为参数,产生它们的和。从基本数据出发,一个有理数可以看作两个整数的组合--分子和分母,其过程可以用add-rat实现,一个产生和数的分子,另一个产生和数的分母,在使用这些数据时,有很多有理数时,其对应的分子和分母成对出现,如果不加规则约束,将会使得代码越来越难读懂,所以希望考虑一种复合数据的方法,将数据“粘合”起来。
处理复合数据中的一个关键性思想是闭包的概念--也就是说,用于组合对象数据的粘合剂不但能用于组合基本的数据对象,同样也可以用于复合的数据对象;另一个关键思想是复合对象能够成为以混合与匹配的方式组合程序模块。
数据抽象导引
1)抽象数据的基本思想,就是设法构造出一些使用复合数据对象的程序,使他们就像是在“抽象数据”上操作一样。
2)一种“具体”数据表示的定义与程序中使用数据的方式无关。
[注] 与面向对象的思想相同,“类的写法”,在作者写书的那个年代,面向对象编程的概念还未成为主流,那个年代的思路为数理逻辑的方法,定义符号变量,并进行推导。上面提到的思想就是面向对象编程中类的属性和方法,只不过是用函数式编程实现。
有理数类
今天我们可能会这样构造一个Point类,从数据和操作的思路来看,面向过程和面向对象实现的功能一样。
class RationalNumber(object):
def __init__(self, x, y):
#有序对(x,y)分别表示分子和分母
self.x = x
self.y = y
def numer(self):
return self.x
def denom(self):
return self.y
def get(self):
return self.x/self.y
if __name__ =='__main__':
a = RationalNumber(4,5)
print(a.get())
有理数的运算
如果此时从顶层到底层的思路设计程序,考虑三个函数
def make_rat(n,d): 返回一个有理数:
def numer(x)返回有理数x的分子,def denom(x) 返回有理数x的分母。
两个有理数的加减乘除可以写成:
def add_rat(x,y):
return make_rat(x,y)
def make_rat(x,y):
return (numer(x)*denom(y) +numer(y)*denom(x))/(denom(x) *denom(y) )
然而numer和denom未定义,如果定义一个有序对,numer返回有序对的第一个位置(分子),denom返回有序对的第二个位置(分母),然后再来一次套娃:
x = [1,2]
y = [3,4]
z = [x,y]
def car(x):
return x[0]
def cdr(x):
return x[1]
def numer(x):
return car(x)
def denom(x):
return cdr(x)
print(numer(cdr(z)))
上述例子中的def car(x):相当于numer(x),def cdr(x):相当于denom(x)。
x=[6,9]
def print_rat(x):
print(str(numer(x))+'/'+str(denom(x)))
print_rat(x)
此时输出为:6/9,没有约分到最简形式,为了化简,考虑最大公约数
def gcd(a,b):
if b==0:
return a
else:
return gcd(b,a%b)
def print_rat1(x):
g = gcd(denom(x),numer(x))
#一定是整除的,但是python语言会自动类型转换,保留小数位,为了显示好看->int()
print(str(int(numer(x)/g))+'/'+str(int(denom(x)/g)))
print_rat1(x)
[注]: car 和cdr就是寄存器的概念Contents of Address part of Register”和 “Contents of Decrement part of Register“。
前面给出的所有有理数操作,都是基于构造函数make_rat和选择函数numer(x)和denom(x)定义出来的,数据抽象的思想就是为每一类数据对象标识出一组操作,使得对这类数据对象的所有操作都可以用这些操作来表述,而且在对这些数据进行增删改查的时候也能只能用这些操作。
(从功能上而言,make_rat拆解了一个数使其写成其他函数的组合形式,numer(x)和denom(x)这两个函数选择了有序对中数据的位置,在计算理论中,认为只要实现功能相同,即可认为是等同的)
数据意味着什么
有理数x能够写成两个整数的除法:
\]
前面提到了选择函数和构造函数的思路,有理数x在程序中也用一个有序对来表示,在python中我们使用了List来实现:
x = [a,b]
由给定的构造函数和选择函数所实现的东西,如果要严格形式化这一思想非常困难。目前存在着两种完成这一形式化的途径。
1)抽象模型的方法,它形式化了如上面有理数实例中所勾勒出的“过程加条件”的规范描述,而抽象模型方法总是基于某些已经有定义的数据对象类型,定义出一类新的数据对象。
2)代数规范。这一方式将“过程”看作是抽象代数系统的元素,系统的行为由一些对应于我们的“条件”的公理刻画,并通过抽象代数的技术去检查有关数据对象的断言。
层次性数据和闭包性质
前面在构造有理数时,序对提供了一种用于构造符合数据基本“粘合剂”,并且我们在使用时,规定了第一个位置为分子,第二个位置为分母,调用numer(x)和denom(x)时,实现的功能也只是将对应位置为数据取出而已。(注意指针的思想)
例如有理数 1/2,car和cdr分别取出第一和第二个位置的元素

此外前面提到的有序对的进一步抽象也能表示为:
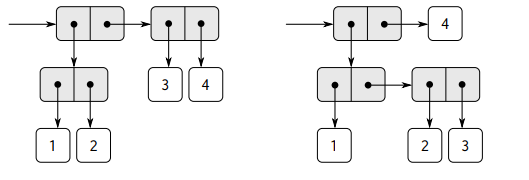
用今天的思想来看就是指针的概念,标记地址,指向数据元素,以及数据结构中提到的线性表。根据规则,组合序对建立出来的元素仍然是序对,那么就是该规则的闭包性质--通过它组合数据对象得到的结果本身还可以通过同样的操作再进行组合,通过这种性质能够建立起层次性的结构。
序列
按照SICP的思路,抽象的时候考虑两个重要的因素:
1)基本的表达式 --> 数据的基本表示
2)方法的组合和抽象 --> 怎么操作这些数据
如果回忆一下二年级学过的数据结构,写一个线性表的代码为(以增删改查中的增和遍历为例):
class Node(object):
def __init__(self, val):
# 定义当前结点值
self.val = val
self.next_node = None
class MyList(object):
def __init__(self, node):
#定义当前结点值
self.node = node
def add_node(self,node):
self.node.next_node = node
def print_all_node(self):
p_node = self.node
while p_node!=None:
print(p_node.val)
p_node = p_node.next_node
if __name__ =='__main__':
firstNode = Node(1)
secondNode = Node(2)
#列表的第一个结点
print('新建列表并插入第一个结点')
myList = MyList(firstNode)
myList.print_all_node()
#列表的第二个结点
print('列表插入第二个结点')
myList.add_node(secondNode)
myList.print_all_node()
而如果学了Python可能这样去写,并且python的List内置了append和pop方法用于元素的插入和删除
if __name__ =='__main__':
lst = [1, 2, 3]
for i in iter(lst):
print(i)
SICP中的序列和操作
在SICP中,数据组合抽象的思路,由于语言的限制,python虽然能实现和Lisp一样的功能,但是不建议这样做:
def car(z):
return z[0]
def cdr(z):
return z[1]
if __name__ =='__main__':
a = [1,[2,[3,[4,[5,None]]]]]
node1 = car(a)
print(node1)
next_iter = cdr(a)
node2 = car(next_iter)
print(node2)
序列的操作
如果是遍历序列的第n个位置,假设序列的数据表示为a=[1,2,3,4,5],那么直接返回下标即可。而如果序列的数据表示为a = [1,[2,[3,[4,[5,None]]]]],可以利用构造的car()和cdr()函数遍历:
#返回第n个位置的元素(从0开始)
def list_ref(a,n):
if n==0:
return car(n)
else:
return cdr(a,n-1)
#返回list的长度
def length_recursive(a):
if a==None:
return 0
else:
return 1 + length(cdr(a))
#返回list的长度
def length_iterative(a):
count = 0
def length_iter(a,count):
if a == None:
return count
else:
return length_iter(cdr(a),count+1)
return length_iter(a,count)
#list的拼接
# a=[1,2,3],b=[4,5]==>c=[1,2,3,4,5]
def list_append(list1,list2):
if list1==None:
return list2
else:
return [car(list1),list_append(cdr(list1),list2)]
#list的mapping
# a = [1,2,3] ==>f(a)=[2,4,6]
def scale_list(items, factors):
if items==None:
return None
else:
return [car(items)*factors, scale_list(cdr(items),factors)]
#mapping操作的高阶抽象
def map_higher_order(f,items):
if items==None:
return None
else:
return [f(car(items)),map_higher_order(f,cdr(items))]
if __name__ =='__main__':
a = [1,[2,[3,[4,[5,None]]]]]
如果用数据结构的思路来审视:a=[1,2,3,4,5]和 a = [1,[2,[3,[4,[5,None]]]]]区别,前者可以理解为线性表,而后者为树:

序列的常规接口定义
借助数据抽象的思路来复合数据(基本表达式),其中屏蔽了程序实现的细节。有了抽象数据之后,就要考虑数据操作的抽象,即现在面向对象的软件设计中,经常提到的一些接口的设计,考虑如下两个程序:
example:以一棵树为参数,计算出奇数叶子节点的平方和
#f为函数的高阶抽象
def sum_odd_square(f,tree):
def tree_iter(tree):
if tree== None:
return 0
else:
if car(tree)%2==0:
return 0 + tree_iter(cdr(tree))
else:
return f(car(tree)) + tree_iter(cdr(tree))
return tree_iter(tree)
if __name__ == '__main__':
tree = [1, [2, [3, [4, [5, [6,None]]]]]]
print(sum_odd_square(lambda x:x*x,tree))
example:构造所有偶数的斐波那契Fib(k)的一个表,其中的k小于某个给定的整数n:
def fib(n):
if n==1:
return 1
elif n==0:
return 0
else:
return fib(n-1) + fib(n-2)
def even_fibs(n):
def next_iter(k):
if k>n:
return None
else:
val = fib(k)
if val%2==0:
return [val, next_iter(k+1)]
else:
return next_iter(k+1)
return next_iter(0)
对比两个函数的功能
def sum_odd_square(f,tree):
1)枚举树的所有叶子
2)过滤叶子结点,选择奇数
3)求平方
4)求和
def even_fibs(n):
1)枚举整数0到n
2)计算斐波那契数
3)过滤结果,取出偶数
4)将结果进行组合
filter
def filter(predicate, sequence):
if sequence ==None:
return None
else:
if predicate(car(sequence)):
return [car(sequence), filter(predicate,cdr(sequence))]
else:
return filter(predicate, cdr(sequence))
def f(z):
if z%2==0:
return True
else:
return False
print(filter(f,a))SCIP:构造数据抽象--数据结构中队列与树的解释的更多相关文章
- 数据结构中常见的树(BST二叉搜索树、AVL平衡二叉树、RBT红黑树、B-树、B+树、B*树)
树 即二叉搜索树: 1.所有非叶子结点至多拥有两个儿子(Left和Right): 2.所有结点存储一个关键字: 非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树: 如: BST树 ...
- 数据结构中很常见的各种树(BST二叉搜索树、AVL平衡二叉树、RBT红黑树、B-树、B+树、B*树)
数据结构中常见的树(BST二叉搜索树.AVL平衡二叉树.RBT红黑树.B-树.B+树.B*树) 二叉排序树.平衡树.红黑树 红黑树----第四篇:一步一图一代码,一定要让你真正彻底明白红黑树 --- ...
- 使用JavaScript的数组实现数据结构中的队列与堆栈
今天在项目中要使用JavaScript实现数据结构中的队列和堆栈,这里做一下总结. 一.队列和堆栈的简单介绍 1.1.队列的基本概念 队列:是一种支持先进先出(FIFO)的集合,即先被插入的数据,先被 ...
- JavaScript学习总结(二十一)——使用JavaScript的数组实现数据结构中的队列与堆栈
今天在项目中要使用JavaScript实现数据结构中的队列和堆栈,这里做一下总结. 一.队列和堆栈的简单介绍 1.1.队列的基本概念 队列:是一种支持先进先出(FIFO)的集合,即先被插入的数据,先被 ...
- [Data Structure] 数据结构中各种树
数据结构中有很多树的结构,其中包括二叉树.二叉搜索树.2-3树.红黑树等等.本文中对数据结构中常见的几种树的概念和用途进行了汇总,不求严格精准,但求简单易懂. 1. 二叉树 二叉树是数据结构中一种重要 ...
- 浅析数据结构中栈与C实现
最近在搞摄像头驱动,o()︿︶)o 唉,别提有多烦,一堆寄存器就有人受的了--特么这不是单片机的开发,这是内核驱动开发-- 今天放松一下,我们来看看数据结构中的栈,这节的知识点可以说是数据结构中最容易 ...
- jvm 中内存的栈和数据结构中的栈的区别
1.常见的数据结构:栈.队列.数组.链表和红黑树,java内存划分 2.JYM中的栈是先进先出,先入栈的先执行: 2.数据结构中的栈是先进后出,类似手枪的弹夹,先进入的子弹最后才发射: 3.数据结构中 ...
- python爬取股票最新数据并用excel绘制树状图
大家好,最近大A的白马股们简直 跌妈不认,作为重仓了抱团白马股基金的养鸡少年,每日那是一个以泪洗面啊. 不过从金融界最近一个交易日的大盘云图来看,其实很多中小股还是红色滴,绿的都是白马股们. 以下截图 ...
- 数据结构中的棧在C#中的实现
数据结构中的棧在C#中的实现 一.大致学习 棧是一种面向表的数据结构,棧中的数据只能在标的某一短进行添加和删除操作,是一种典型的(LIFO)数据结构. 现实生活中的理解:自助餐厅的盘子堆,人们总是从顶 ...
随机推荐
- Python Tutorials
Python Tutorials Real Python https://realpython.com/ https://realpython.com/courses/ https://realpyt ...
- illustrating javascript prototype & prototype chain
illustrating javascript prototype & prototype chain 图解 js 原型和原型链 proto & prototype func; // ...
- node.js delete directory & file system
node.js delete directory & file system delete a not empty directory https://nodejs.org/api/fs.ht ...
- Flutter & UI system & GUI & API & SDK
Flutter & UI system & GUI & API & SDK https://book.flutterchina.club/chapter14/flutt ...
- js 增加数组的嵌套层数
class A {} const proxy = new Proxy(new A(), { get(o, k) { if (!/\d+/.test(k.toString())) return o[k] ...
- PAA房产,一家有温度的房产公司
PAUL ADAMS ARCHITECT房产(以下简称PAA,公司编号:07635831)对每一个客户从心出,为他们选择优质房源,为他们缔造家的温暖.PAA房产,是一家有温度的房产公司. PAA房产( ...
- PAUL ADAMS ARCHITECT:澳洲房贷最低利率来袭
11月3日澳洲储备银行宣布将官方现金利率从0.25%降至0.1%,破历史最低纪录.此次澳洲储备银行降息的目的主要是为了刺激经济走出全球经济危机引发的衰退.据了解,这已经是澳洲今年第三次降息,也是自20 ...
- pytorch中修改后的模型如何加载预训练模型
问题描述 简单来说,比如你要加载一个vgg16模型,但是你自己需要的网络结构并不是原本的vgg16网络,可能你删掉某些层,可能你改掉某些层,这时你去加载预训练模型,就会报错,错误原因就是你的模型和原本 ...
- Dockerfile多阶段构建原理和使用场景
本文转载自Dockerfile多阶段构建原理和使用场景 导语 Docker 17.05版本以后,新增了Dockerfile多阶段构建.所谓多阶段构建,实际上是允许一个Dockerfile 中出现多个 ...
- 剑指 Offer 56 - I. 数组中数字出现的次数 + 分组异或
剑指 Offer 56 - I. 数组中数字出现的次数 Offer_56_1 题目描述 解题思路 java代码 /** * 方法一:数位方法 */ class Offer_56_1_2 { publi ...