Kaggle-SQL(1)
Getting-started-with-sql-and-bigquery
教程
结构化查询语言(SQL)是数据库使用的编程语言,它是任何数据科学家的一项重要技能。 在本课程中,您将使用BigQuery来提高SQL技能,BigQuery是一种Web服务,可用于将SQL应用于庞大的数据集。
在本课程中,您将学习访问和检查BigQuery数据集的基础知识。 在您掌握了这些基础知识之后,我们将再次建立您的SQL技能。
Your first BigQuery commands
要使用BigQuery,我们将在下面导入Python包
from google.cloud import bigquery
工作流程的第一步是创建一个Client对象。 您将很快看到,此Client对象将在从BigQuery数据集中检索信息中发挥核心作用。
# Create a "Client" object
client = bigquery.Client()
我们将使用Hacker News(一个专注于计算机科学和网络安全新闻的网站)上的帖子数据集。
在BigQuery中,每个数据集都包含在相应的项目中。 在这种情况下,我们的hacker_news数据集包含在bigquery-public-data项目中。 要访问数据集,
我们首先使用dataset()方法构造对数据集的引用。接下来,我们使用get_dataset()方法以及刚刚构造的引用来获取数据集。
# Construct a reference to the "hacker_news" dataset
dataset_ref = client.dataset("hacker_news", project="bigquery-public-data") # API request - fetch the dataset
dataset = client.get_dataset(dataset_ref)
每个数据集都只是表的集合。 您可以将数据集视为包含多个表(均由行和列组成)的电子表格文件。我们使用list_tables()方法列出数据集中的表。
# List all the tables in the "hacker_news" dataset
tables = list(client.list_tables(dataset)) # Print names of all tables in the dataset (there are four!)
for table in tables:
print(table.table_id)
output
comments
full
full_201510
stories
与获取数据集相似,我们可以获取表。 在下面的代码单元中,我们在hacker_news数据集中获取完整表。
# Construct a reference to the "full" table
table_ref = dataset_ref.table("full") # API request - fetch the table
table = client.get_table(table_ref)
Table schema
表的结构称为其架构。 我们需要了解表的架构以有效地提取所需的数据。
在此示例中,我们将调查上面获取的完整表。
# Print information on all the columns in the "full" table in the "hacker_news" dataset
table.schema
output
[SchemaField('title', 'STRING', 'NULLABLE', 'Story title', ()),
SchemaField('url', 'STRING', 'NULLABLE', 'Story url', ()),
SchemaField('text', 'STRING', 'NULLABLE', 'Story or comment text', ()),
SchemaField('dead', 'BOOLEAN', 'NULLABLE', 'Is dead?', ()),
SchemaField('by', 'STRING', 'NULLABLE', "The username of the item's author.", ()),
SchemaField('score', 'INTEGER', 'NULLABLE', 'Story score', ()),
SchemaField('time', 'INTEGER', 'NULLABLE', 'Unix time', ()),
SchemaField('timestamp', 'TIMESTAMP', 'NULLABLE', 'Timestamp for the unix time', ()),
SchemaField('type', 'STRING', 'NULLABLE', 'Type of details (comment, comment_ranking, poll, story, job, pollopt)', ()),
SchemaField('id', 'INTEGER', 'NULLABLE', "The item's unique id.", ()),
SchemaField('parent', 'INTEGER', 'NULLABLE', 'Parent comment ID', ()),
SchemaField('descendants', 'INTEGER', 'NULLABLE', 'Number of story or poll descendants', ()),
SchemaField('ranking', 'INTEGER', 'NULLABLE', 'Comment ranking', ()),
SchemaField('deleted', 'BOOLEAN', 'NULLABLE', 'Is deleted?', ())]
每个SchemaField都会告诉我们一个特定的列(也称为字段)。 按顺序,信息为:
列名
列中的字段类型(或数据类型)
列的模式(“ NULLABLE”表示列允许NULL值,并且是默认值)
该列中数据的描述
比如 SchemaField('by', 'STRING', 'NULLABLE', "The username of the item's author.", ()) 告诉我们:这个列名字为"by",数据为字符串型,允许为空,这个列存储了作者的名字
我们可以使用list_rows()方法来检查整个表的前五行,以确保这是正确的。 (有时数据库的描述已经过时,因此最好检查一下。)这将返回一个BigQuery RowIterator对象,该对象可以使用to_dataframe()方法快速转换为pandas DataFrame。
# Preview the first five lines of the "full" table
client.list_rows(table, max_results=5).to_dataframe()
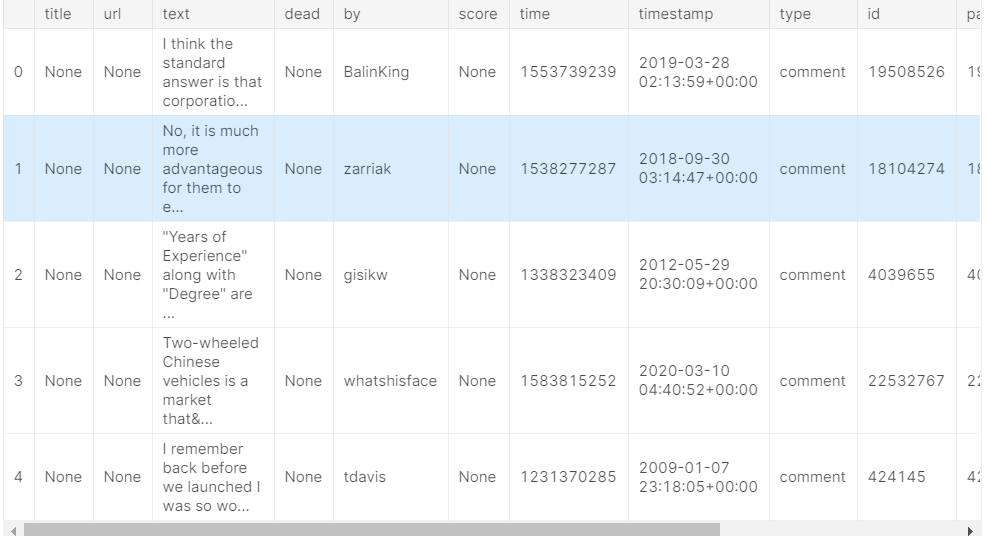
list_rows()方法还将使我们仅查看特定列中的信息。 例如,如果我们要查看by列中的前五个条目,则可以这样做:
# Preview the first five entries in the "by" column of the "full" table
client.list_rows(table, selected_fields=table.schema[:1], max_results=5).to_dataframe()
Disclaimer
在进行编码练习之前,对已经知道一些SQL的人快速声明一下:
每个Kaggle用户可以每30天免费扫描5TB。 达到该限制后,您将不得不等待重置。
到目前为止,您所看到的命令将不需要该限制的有意义的一部分。 但是某些BiqQuery数据集非常庞大。 因此,如果您已经了解SQL,请等待运行SELECT查询,直到您了解如何有效使用分配。 如果您像大多数阅读此书的人一样,则还不知道如何编写这些查询,因此您无需担心此免责声明。
Kaggle-SQL(1)的更多相关文章
- 最全数据分析资料汇总(含python、爬虫、数据库、大数据、tableau、统计学等)
一.Python基础 Python简明教程(Python3) Python3.7.4官方中文文档 Python标准库中文版 廖雪峰 Python 3 中文教程 Python 3.3 官方教程中文版 P ...
- SQL kaggle learn : WHERE AND
WHERE trip_start_timestamp Between '2017-01-01' And '2017-07-01' and trip_seconds > 0 and trip_mi ...
- SQL kaggle learn with as excercise
rides_per_year_query = """ SELECT EXTRACT(YEAR FROM trip_start_timestamp) AS year ,CO ...
- kaggle之数据分析从业者用户画像分析
数据为kaggle社区发布的数据分析从业者问卷调查分析报告,其中涵盖了关于该行业不同维度的问题及调查结果.本文的目的为提取有用的数据,进行描述性展示.帮助新从业的人员更全方位地了解这个行业. 参考学习 ...
- 最近帮客户实施的基于SQL Server AlwaysOn跨机房切换项目
最近帮客户实施的基于SQL Server AlwaysOn跨机房切换项目 最近一个来自重庆的客户找到走起君,客户的业务是做移动互联网支付,是微信支付收单渠道合作伙伴,数据库里存储的是支付流水和交易流水 ...
- SQL Server 大数据搬迁之文件组备份还原实战
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 解决方案(Solution) 搬迁步骤(Procedure) 搬迁脚本(SQL Codes) ...
- Sql Server系列:分区表操作
1. 分区表简介 分区表在逻辑上是一个表,而物理上是多个表.从用户角度来看,分区表和普通表是一样的.使用分区表的主要目的是为改善大型表以及具有多个访问模式的表的可伸缩性和可管理性. 分区表是把数据按设 ...
- SQL Server中的高可用性(2)----文件与文件组
在谈到SQL Server的高可用性之前,我们首先要谈一谈单实例的高可用性.在单实例的高可用性中,不可忽略的就是文件和文件组的高可用性.SQL Server允许在某些文件损坏或离线的情况下,允 ...
- EntityFramework Core Raw SQL
前言 本节我们来讲讲EF Core中的原始查询,目前在项目中对于简单的查询直接通过EF就可以解决,但是涉及到多表查询时为了一步到位就采用了原始查询的方式进行.下面我们一起来看看. EntityFram ...
- 从0开始搭建SQL Server AlwaysOn 第一篇(配置域控)
从0开始搭建SQL Server AlwaysOn 第一篇(配置域控) 第一篇http://www.cnblogs.com/lyhabc/p/4678330.html第二篇http://www.cnb ...
随机推荐
- day53 html收尾
目录 一.解决浮动带来的影响 二.溢出属性 三.定位 四.验证浮动和定位是否脱离文档流 五.z-index模态框 六.透明度opacity 七.js简介 一.解决浮动带来的影响 块级标签内的浮动如果该 ...
- saver 的保存与恢复
模型保存,先要创建一个Saver对象:saver=tf.train.Saver(), max_to_keep 是用来设置保存模型的个数,默认为5,即保存最近的五个模型,saver=tf.train.S ...
- vue 写h5页面-摇一摇
依赖的第三方的插件 shake.js github地址: https://github.com/alexgibson/shake.js 提供一个摇一摇音效下载地址:http://aspx.sc.chi ...
- 02-URLConf调度器
1.工作原理 django通过urlconf来映射视图函数,只区分路径,不区分http方法 Django确定要使用的根URLconf模块,一般是在settings中的ROOT_URLCONF设置的值. ...
- Python3 迭代器深入解析
第6章 函数 6.1 函数的定义和调用 6.2 参数传递 6.3 函数返回值 6.4 变量作用域 6.5 匿名函数(lambda) 6.6 递归函数 6.7 迭代器 6.8 生成器 6.9 装饰器 6 ...
- Python Ethical Hacking - Packet Sniffer(1)
PACKET_SNIFFER Capture data flowing through an interface. Filter this data. Display Interesting info ...
- SQL : 把特定的数据排前面 & 分别查询几组数据的最大值
把特定的数据排前面 : 比如说,把没有审核身份证的人排最前面,然后再按userId正序排. select case when idcardverified = 1 then 0 else 1 end ...
- [jvm] -- 常用内存参数配置篇
新生代 ( Young ) 与老年代 ( Old ) 的比例的值为 1:2 ( 该值可以通过参数 –XX:NewRatio 来指定 ) Eden : from : to = 8 : 1 : 1 ( 可 ...
- nginx配置多个图片访问路径
需求:vue项目打包的时候 会将项目中的一些图片打包到/dist/static/images下,但是有时候会有一些很大的图片,需要单独存放至别的文件夹比如/home/di-img下,不能被打倒包内.部 ...
- MySQL之表关系与范式
关系: 所有的关系都是指表与表之间的关系. 将实体与实体的关系,反应到最终数据库表的设计上来,可以将关系分成三种:一对一,一对多(多对一)和多对多. 一对一: 一张表的一条记录一定只能与另外一张表的记 ...