Iterative learning control for linear discrete delay systems via discrete matrix delayed exponential function approach
对于一类具有随机变迭代长度的问题,如功能性电刺激,用户可以提前结束实验过程,论文也是将离散矩阵延迟指数函数引入到状态方程中。
论文中关于迭代长度有三个定义值:\(Z^Ta\) 为最小的实验长度,\(Z^Td\) 为期望实验长度,\(Z^Tk\) 为k次迭代的实验长度。
柯西状态方程如下:
x(t+1) &=A x(t)+A_{1} x(t-\sigma)+f(t), \quad t \in \mathbb{Z}_{0}^{\infty} \\
x(t) &=\varphi(t), \quad t \in \mathbb{Z}_{-\sigma}^{0}
\end{aligned}
\]
引入离散矩阵延迟指数函数,状态x(k)的解为:
x(t)=& A^{t} e_{\sigma}^{B_{1} t} A^{-\sigma} \varphi(-\sigma)+\sum_{j=-\sigma+1}^{0} A^{(t-j)} e_{\sigma}^{B_{1}(t-\sigma-j)}[\varphi(j)-A \varphi(j-1)] \\
&+\sum_{j=1}^{t} A^{(t-j)} e_{\sigma}^{B_{1}(t-\sigma-j)} f(j-1)
\end{aligned}
\]
随机变迭代实验长度内容部分:
存在两种情况:1. \(T_k>T_d\),2. \(T_a<T_k<T_d\) 。对于第一种情况,只用Td以内的数据用来更新输入信号,对于第二情况只用\(Tk\)之内的数据进行更新。
η_k (t)为伯努利分布,其中值1表示以p(t)的概率运行到t时刻,值0表示以1-p(t)的概率不能运行到时刻t。对于Ta到Td这段时间的概率计算公式如下:
1, & t \in \mathbb{Z}_{0}^{T_{a}} \\
\sum_{i=t}^{T_{d}} p_{i}, & t \in \mathbb{Z}_{T_{a+1}}^{T_{d}} .
\end{array}\right.
\]
举一个例子通俗地讲一下,上面地内容主要是用在算法收敛性证明的。前6次迭代实验的长度如下图所示,1为上面伯努利分布的1事件,0同理。
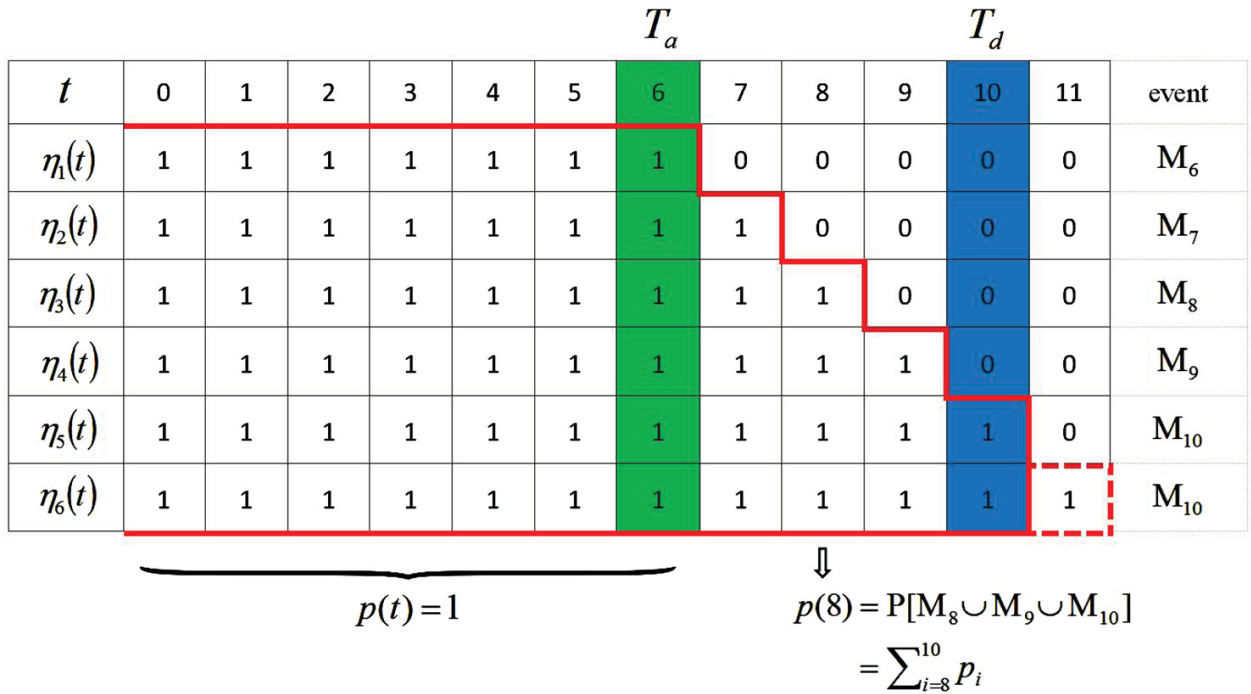
把Ta=6作为最小的运行时刻,期望运行时刻为Td=10,第一次迭代的终止时刻为6,把这个事件称之为M6,第六次迭代时,到T=11结束,即运行时刻大于Td,把这种情况同样视为M10。在上面的这张表中,运行到[7,10]的概率如下所示:其中pi为事件Mi发生的概率。那么系统能运行到时刻8的概率p(8)等于大于时刻8事件的概率3/5。
p(t)的概率表达式为:
\]
关于误差的定义
由于存在实际实验长度小于期望长度,所以这部分的误差当作0来计算:
e_{k}(t), & t \in \mathbb{Z}_{0}^{T_{k}} \\
0, & t \in \mathbb{Z}_{T_{k+1}}^{T_{d}}
\end{array}\right.
\]
两种学习控制律
\]
\]
对于(9)式要把期望时间间隔设置为0到Td+1。算法的收敛性略(其实是我不会)。
代码见GITHUB
Iterative learning control for linear discrete delay systems via discrete matrix delayed exponential function approach的更多相关文章
- A Statistical View of Deep Learning (IV): Recurrent Nets and Dynamical Systems
A Statistical View of Deep Learning (IV): Recurrent Nets and Dynamical Systems Recurrent neural netw ...
- 机器学习---最小二乘线性回归模型的5个基本假设(Machine Learning Least Squares Linear Regression Assumptions)
在之前的文章<机器学习---线性回归(Machine Learning Linear Regression)>中说到,使用最小二乘回归模型需要满足一些假设条件.但是这些假设条件却往往是人们 ...
- CheeseZH: Stanford University: Machine Learning Ex5:Regularized Linear Regression and Bias v.s. Variance
源码:https://github.com/cheesezhe/Coursera-Machine-Learning-Exercise/tree/master/ex5 Introduction: In ...
- Andrew Ng Machine Learning 专题【Linear Regression】
此文是斯坦福大学,机器学习界 superstar - Andrew Ng 所开设的 Coursera 课程:Machine Learning 的课程笔记. 力求简洁,仅代表本人观点,不足之处希望大家探 ...
- 机器学习---用python实现最小二乘线性回归算法并用随机梯度下降法求解 (Machine Learning Least Squares Linear Regression Application SGD)
在<机器学习---线性回归(Machine Learning Linear Regression)>一文中,我们主要介绍了最小二乘线性回归算法以及简单地介绍了梯度下降法.现在,让我们来实践 ...
- 转载 Deep learning:二(linear regression练习)
前言 本文是多元线性回归的练习,这里练习的是最简单的二元线性回归,参考斯坦福大学的教学网http://openclassroom.stanford.edu/MainFolder/DocumentPag ...
- [笔记]机器学习(Machine Learning) - 01.线性回归(Linear Regression)
线性回归属于回归问题.对于回归问题,解决流程为: 给定数据集中每个样本及其正确答案,选择一个模型函数h(hypothesis,假设),并为h找到适应数据的(未必是全局)最优解,即找出最优解下的h的参数 ...
- Machine Learning No.1: Linear regression with one variable
1. hypothsis 2. cost function: 3. Goal: 4. Gradient descent algorithm repeat until convergence { (fo ...
- Machine Learning No.2: Linear Regression with Multiple Variables
1. notation: n = number of features x(i) = input (features) of ith training example = value of feat ...
随机推荐
- 【从零开始撸一个App】RecyclerView的使用
目标 前段时间打造了一款简单易用功能全面的图片上传组件,现在就来将上传的图片以图片集的形式展现到App上.出于用户体验考虑,加载新图片采用[无限]滚动模式,Android平台上我们优选Recycler ...
- PTA甲级—链表
1032 Sharing (25分) 回顾了下链表的基本使用,这题就是判断两个链表是否有交叉点. 我最开始的做法就是用cnt[]记录每个节点的入度,发现入度为2的节点即为答案.后来发现这里忽略了两个链 ...
- 【poj 1988】Cube Stacking(图论--带权并查集)
题意:有N个方块,M个操作{"C x":查询方块x上的方块数:"M x y":移动方块x所在的整个方块堆到方块y所在的整个方块堆之上}.输出相应的答案. 解法: ...
- - Visible Trees HDU - 2841 容斥原理
题意: 给你一个n*m的矩形,在1到m行,和1到n列上都有一棵树,问你站在(0,0)位置能看到多少棵树 题解: 用(x,y)表示某棵树的位置,那么只要x与y互质,那么这棵树就能被看到.不互质的话说明前 ...
- hdu2126 Buy the souvenirs
Problem Description When the winter holiday comes, a lot of people will have a trip. Generally, ther ...
- C#程序报找不到时区错误
原因:win10电脑里的时区在win7里不全有 解决:将win10时区注册表导出,在win7电脑上安装 时区注册表路径:HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Wi ...
- ef学习记录
EF Core (EntityFramework Core)是实体关系映射(O/RM)数据库访问框架.这个模式的好处就是让开发人员可以用对象模型来操作数据库,这是一种对开发人员较为友好的方式. O/R ...
- Selenium+Python之下拉菜单的定位
1.通过selenium.webdriver.support.ui的Select进行定位 下拉菜单如下图: 定位代码(选择Male): from selenium.webdriver.support. ...
- canvas画布基本知识点总结
HTML5的canvas元素使用JavaScript画图: <canvas width="600" height="400"> </canva ...
- Google PageSpeed Insights : 网站性能优化检测工具
1 1 https://developers.google.com/speed/pagespeed/insights/ PageSpeed Insights 使您的网页在所有设备上都能快速加载. 分析 ...