Tensorflow学习笔记No.7
tf.data与自定义训练综合实例
使用tf.data自定义猫狗数据集,并使用自定义训练实现猫狗数据集的分类。
1.使用tf.data创建自定义数据集
我们使用kaggle上的猫狗数据以及tf.data来建立自己的猫狗数据集。
tf.data详细的使用方法中在Tensorflow学习笔记No.5中以经介绍过,这里只简略讲述。
打开kaggle中的notebook,点击右侧"+Add data",搜索如下数据集,并点击右侧"Add"。
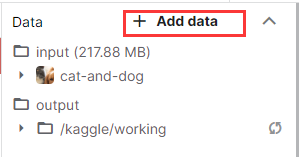

随后Cat and Dog这个数据集就会被添加在input目录下。
1.1获取图片路径
首先,导入需要的模块~
1 import tensorflow as tf
2 from tensorflow import keras
3 import matplotlib.pyplot as plt
4 %matplotlib inline
5 import numpy as np
6 import glob
7 import os
8 import pathlib
使用pathlib.path()方法获取文件目录。
文件目录如下:
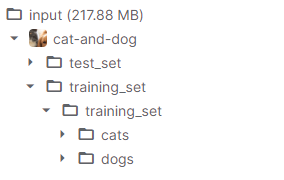
1 data_root = pathlib.Path('../input/cat-and-dog/training_set/training_set')
data_root记录了猫狗数据集在kaggle中的储存位置。
随后我们使用.glob()方法获取该路径下的所有图片路径。
1 all_image_path = list(data_root.glob('*/*.jpg'))
使用random.shuffle()方法对路径进行乱序(因为后续也会对数据进行乱序和数据增强处理,这一步可有可无),并记录图片总数。
1 import random
2 random.shuffle(all_image_path)
3 image_count = len(all_image_path)
2.2对图片进行标记
获取全部的图片后,我们要对所有的图片打上标签,以便区分图片是cat还是dog,用于后续对神经网络的训练。
首先,获取标签的名称,也就是存放图片的文件夹的名字(cats/dogs)。
1 label_name = sorted([item.name for item in data_root.glob('training_set/*')])
获取的标签名如下:

然后我们建立字典,将标签名映射为0,1。
1 name_to_indx = dict((name, indx) for indx, name in enumerate(label_name))

通过获取的图片路径将所有的图片打上标签。
1 all_image_path = [str(path) for path in all_image_path]
2 all_image_label = [name_to_indx[pathlib.Path(p).parent.name] for p in all_image_path]
2.3图像处理与数据增强
由于数据增强只需要对train数据进行增强,所以我们定义两个函数分别对train和test数据进行处理。
对读入的图片进行解码,并将尺寸归一化。
对训练集数据进行随机上下左右翻转与裁剪,增强数据。
1 def load_preprosess_image(path, label):
2 img = tf.io.read_file(path)
3 img = tf.image.decode_jpeg(img, channels = 3)
4 img = tf.image.resize(img, [320, 320])
5 #resize_with_crop_or_pad填充与裁剪
6
7 #数据增强
8 img = tf.image.random_crop(img, [256, 256, 3]) #随机裁剪
9 img = tf.image.random_flip_left_right(img) #随机左右翻转
10 img = tf.image.random_flip_up_down(img) #随机上下翻转
11 #img = tf.image.random_brightness(img, 0.5) #随机调整亮度
12 #img = tf.image.random_contrast(img, 0, 1) #随机调整对比度
13
14 img = tf.cast(img, tf.float32)
15 img = img / 255
16 label = tf.reshape(label, [1])
17 return img, label
18 #加载和预处理图片
19
20 def load_preprosess_image_test(path, label):
21 img = tf.io.read_file(path)
22 img = tf.image.decode_jpeg(img, channels = 3)
23 img = tf.image.resize(img, [256, 256])
24 #resize_with_crop_or_pad填充与裁剪
25
26 img = tf.cast(img, tf.float32)
27 img = img / 255
28 label = tf.reshape(label, [1])
29 return img, label
30 #加载和预处理图片
通过tf.data.Dataset.from_tensor_slices()方法建立数据集。
1 dataset = tf.data.Dataset.from_tensor_slices((all_image_path, all_image_label))
将数据集分割为训练集与测试集,并分别使用预处理函数对图片进行处理。
1 test_count = int(image_count * 0.2)
2 train_count = image_count - test_count
3 train_dataset = dataset.skip(test_count)
4 test_dataset = dataset.take(test_count)
5
6 train_dataset = train_dataset.map(load_preprosess_image)
7 test_dataset = test_dataset.map(load_preprosess_image_test)
对训练集和测试集划分BATCH_SIZE。
1 BATCH_SIZE = 16
2 train_dataset = train_dataset.shuffle(train_count).batch(BATCH_SIZE)
3 test_dataset = test_dataset.batch(BATCH_SIZE)
注:此时的train_dataset与test_dataset都是可迭代对象,我们可以使用迭代器查看数据。
1 img, label = next(iter(train_dataset))
2 plt.imshow(img[0]) #由于这个东西运行的很慢,这里就不展示运行结果了,这两行代码同样可有可无。
2.使用自定义训练训练神经网络
2.1建立神经网络模型
我们仿照VGG_16制作一个网络模型(不完全相同)。
1 model = keras.Sequential()
2 model.add(keras.layers.Conv2D(64, (3, 3), input_shape = (256, 256, 3),padding = 'same', activation = 'relu'))
3 model.add(keras.layers.BatchNormalization())
4 model.add(keras.layers.Conv2D(64, (3, 3), activation = 'relu'))
5 model.add(keras.layers.BatchNormalization())
6 model.add(keras.layers.MaxPooling2D())
7 model.add(keras.layers.Conv2D(128, (3, 3), activation = 'relu'))
8 model.add(keras.layers.BatchNormalization())
9 model.add(keras.layers.Conv2D(128, (3, 3), activation = 'relu'))
10 model.add(keras.layers.BatchNormalization())
11 model.add(keras.layers.MaxPooling2D())
12 model.add(keras.layers.Conv2D(256, (3, 3), activation = 'relu'))
13 model.add(keras.layers.BatchNormalization())
14 model.add(keras.layers.Conv2D(256, (3, 3), activation = 'relu'))
15 model.add(keras.layers.BatchNormalization())
16 model.add(keras.layers.Conv2D(256, (3, 3), activation = 'relu'))
17 model.add(keras.layers.BatchNormalization())
18 model.add(keras.layers.MaxPooling2D())
19 model.add(keras.layers.Conv2D(512, (3, 3), activation = 'relu'))
20 model.add(keras.layers.BatchNormalization())
21 model.add(keras.layers.Conv2D(512, (3, 3), activation = 'relu'))
22 model.add(keras.layers.BatchNormalization())
23 model.add(keras.layers.Conv2D(512, (3, 3), activation = 'relu'))
24 model.add(keras.layers.BatchNormalization())
25 model.add(keras.layers.MaxPooling2D())
26 model.add(keras.layers.Conv2D(512, (3, 3), activation = 'relu'))
27 model.add(keras.layers.BatchNormalization())
28 model.add(keras.layers.Conv2D(512, (3, 3), activation = 'relu'))
29 model.add(keras.layers.BatchNormalization())
30 model.add(keras.layers.Conv2D(512, (3, 3), activation = 'relu'))
31 model.add(keras.layers.BatchNormalization())
32 model.add(keras.layers.MaxPooling2D())
33 model.add(keras.layers.GlobalAveragePooling2D())
34 model.add(keras.layers.Dense(1024, activation = 'relu'))
35 model.add(keras.layers.BatchNormalization())
36 model.add(keras.layers.Dense(256, activation = 'relu'))
37 model.add(keras.layers.BatchNormalization())
38 model.add(keras.layers.Dense(1))
注意!最后一层Dense层没有使用sigmoid函数进行激活。
2.2自定义模型训练策略
我们选用Adam作为优化器,并定义模型的正确率与平均损失的计算方式。
1 optimizer = tf.keras.optimizers.Adam(learning_rate = 0.001)
2 epoch_loss_avg = tf.keras.metrics.Mean('train_loss', dtype = tf.float32)#参数为name
3 train_accuracy = tf.keras.metrics.Accuracy()
4
5 epoch_loss_avg_test = tf.keras.metrics.Mean('train_loss', dtype = tf.float32)#参数为name
6 test_accuracy = tf.keras.metrics.Accuracy()
定义训练集与测试集的的训练函数。
1 def train_step(model, images, labels):
2 with tf.GradientTape() as GT: #记录梯度
3 pred = model(images, training = True)
4 loss_step = tf.keras.losses.BinaryCrossentropy(from_logits = True)(labels, pred)
5 #from_logits 模型中输出结果是否进行了激活,未激活则为True
6 grads = GT.gradient(loss_step, model.trainable_variables)
7 #计算梯度
8 optimizer.apply_gradients(zip(grads, model.trainable_variables))
9 #利用梯度对模型参数进行优化
10 epoch_loss_avg(loss_step)#计算loss
11 train_accuracy(labels, tf.cast(pred > 0, tf.int32))#计算acc
12
13 def test_step(model, images, labels):
14 pred = model(images, training = False)#pred = model.predict(images)#
15 loss_step = loss_step = tf.keras.losses.BinaryCrossentropy(from_logits = True)(labels, pred)
16
17 epoch_loss_avg_test(loss_step)#计算loss
18 test_accuracy(labels, tf.cast(pred > 0, tf.int32))#计算acc
使用with tf.GradientTape()记录训练过程中的loss值。
使用model()对训练集进行预测,在通过损失函数BinaryCrossentropy()计算loss值。
使用.gradient()方法来计算梯度,参数为,loss值与模型的可训练参数。
计算好梯度之后,使用optimizer对模型的可训练参数进行优化。
最后计算模型的平均loss与正确率。
对测试集仅进行预测计算loss与正确率即可,无需对模型参数进行更新。
2.3自定义训练过程对模型进行训练
首先,定义几个列表记录loss与acc,用来绘制训练过程的图像。
1 train_loss_result = []
2 train_acc_result = []
3
4 test_loss_result = []
5 test_acc_result = []
定义要训练的epochs,这里我们对模型训练130个epoch。
1 num_epochs = 130
定义训练函数:
1 for epoch in range(num_epochs):
2 indx = 1
3 for images, labels in train_dataset:
4 train_step(model, images, labels)
5 indx += 1
6 if(indx % 5 == 0):
7 print('.', end = '')
8 print()
9 #训练过程
10 train_loss_result.append(epoch_loss_avg.result())
11 train_acc_result.append(train_accuracy.result())
12 #记录loss与acc
13
14 for images, labels in test_dataset:
15 test_step(model, images, labels)
16
17 test_loss_result.append(epoch_loss_avg_test.result())
18 test_acc_result.append(test_accuracy.result())
19
20 print('Epoch:{}: loss:{:.3f}, acc:{:.3f}, val_loss:{:.3f}, val_acc:{:.3f}'.format(
21 epoch + 1, epoch_loss_avg.result(), train_accuracy.result(),
22 epoch_loss_avg_test.result(), test_accuracy.result()
23 ))
24
25 epoch_loss_avg.reset_states()
26 train_accuracy.reset_states()
27 #清空,统计下一个epoch的均值
28
29 epoch_loss_avg_test.reset_states()
30 test_accuracy.reset_states()
在每个epoch中,对train_dataset进行迭代,每次迭代处理的数据数量为一个BATCH_SIZE(),对每个BATCH_SIZE使用定义好的训练函数对模型进行训练,输出训练过程并使用之前定义好的列表记录训练过程。
一个epoch训练完后,对loss均值与正确率计算函数进行清空处理,为下一个epoch的训练做好准备。
2.3训练结果
点击kaggle右上角的"Save version"保存并将模型提交进行训练。
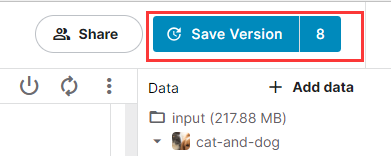
选择提交(Commit),并点击"Advanced Settings"。

选择使用GPU进行训练,否则会训练的非常缓慢。
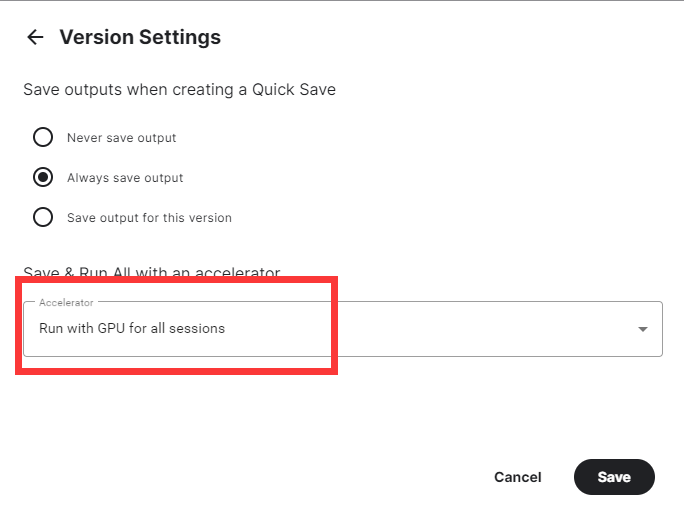
最后点击Save即可。
由于使用的网络模型较深,且参数较多,所以训练的速度很慢,大概训练了3个半小时得到如下训练结果:
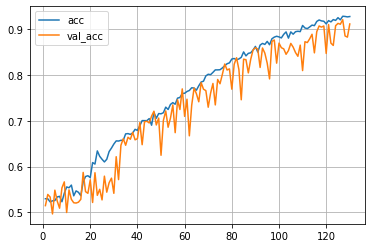
模型在训练集上达到了92.8%的正确率,在测试集上达到了91.1%的正确率。
本次更新的较为匆忙,很多API的用法没有很详细的进行介绍,后面会再次更新进行补充。
Tensorflow学习笔记No.7的更多相关文章
- Tensorflow学习笔记2:About Session, Graph, Operation and Tensor
简介 上一篇笔记:Tensorflow学习笔记1:Get Started 我们谈到Tensorflow是基于图(Graph)的计算系统.而图的节点则是由操作(Operation)来构成的,而图的各个节 ...
- Tensorflow学习笔记2019.01.22
tensorflow学习笔记2 edit by Strangewx 2019.01.04 4.1 机器学习基础 4.1.1 一般结构: 初始化模型参数:通常随机赋值,简单模型赋值0 训练数据:一般打乱 ...
- Tensorflow学习笔记2019.01.03
tensorflow学习笔记: 3.2 Tensorflow中定义数据流图 张量知识矩阵的一个超集. 超集:如果一个集合S2中的每一个元素都在集合S1中,且集合S1中可能包含S2中没有的元素,则集合S ...
- TensorFlow学习笔记之--[compute_gradients和apply_gradients原理浅析]
I optimizer.minimize(loss, var_list) 我们都知道,TensorFlow为我们提供了丰富的优化函数,例如GradientDescentOptimizer.这个方法会自 ...
- 深度学习-tensorflow学习笔记(1)-MNIST手写字体识别预备知识
深度学习-tensorflow学习笔记(1)-MNIST手写字体识别预备知识 在tf第一个例子的时候需要很多预备知识. tf基本知识 香农熵 交叉熵代价函数cross-entropy 卷积神经网络 s ...
- 深度学习-tensorflow学习笔记(2)-MNIST手写字体识别
深度学习-tensorflow学习笔记(2)-MNIST手写字体识别超级详细版 这是tf入门的第一个例子.minst应该是内置的数据集. 前置知识在学习笔记(1)里面讲过了 这里直接上代码 # -*- ...
- tensorflow学习笔记(4)-学习率
tensorflow学习笔记(4)-学习率 首先学习率如下图 所以在实际运用中我们会使用指数衰减的学习率 在tf中有这样一个函数 tf.train.exponential_decay(learning ...
- tensorflow学习笔记(3)前置数学知识
tensorflow学习笔记(3)前置数学知识 首先是神经元的模型 接下来是激励函数 神经网络的复杂度计算 层数:隐藏层+输出层 总参数=总的w+b 下图为2层 如下图 w为3*4+4个 b为4* ...
- tensorflow学习笔记(2)-反向传播
tensorflow学习笔记(2)-反向传播 反向传播是为了训练模型参数,在所有参数上使用梯度下降,让NN模型在的损失函数最小 损失函数:学过机器学习logistic回归都知道损失函数-就是预测值和真 ...
- tensorflow学习笔记(1)-基本语法和前向传播
tensorflow学习笔记(1) (1)tf中的图 图中就是一个计算图,一个计算过程. 图中的constant是个常量 计 ...
随机推荐
- C#开发PACS医学影像处理系统(六):加载Dicom影像
对于一款软件的扩展性和维护性来说,上层业务逻辑和UI表现一定要自己开发才有控制权,否则项目上线之后容易被掣肘, 而底层图像处理,我们不需要重复造轮子,这里推荐使用fo-dicom,同样基于Dicom3 ...
- pycharm之ctrl+鼠标滚轮调整字体大小
按照图示设置,可以添加:ctrl+鼠标滚轮调整字体大小功能 1. 2.
- Linux磁盘管理及LVM讲解(1)
硬盘接口 从整体的角度上,硬盘接口分为IDE.SATA.SCSI和SAS四种,IDE接口硬盘多用于家用产品中,也部分应用于服务器,SCSI接口的硬盘则主要应用于服务器市场,而SAS只在高端服务器上,价 ...
- 属性序列化自定义与字母表排序-JSON框架Jackson精解第3篇
Jackson是Spring Boot默认的JSON数据处理框架,但是其并不依赖于任何的Spring 库.有的小伙伴以为Jackson只能在Spring框架内使用,其实不是的,没有这种限制.它提供了很 ...
- Mybatis快速逆向生成代码
先下载生成器的文件, 并在eclipse或者IDEA里面打开这个工程 热乎乎的链接 然后配置一下 选择你需要生成的数据的ip和端口 点击运行入口函数 运行成功 接着在浏览器输入localhost: 这 ...
- 永久激活(idea,pycharm等推荐使用)
二.永久激活(推荐使用)激活码激活总是过期,永久激活后,一劳永逸,不需要每次都在网上搜索激活码了. 1.下载激活插件:jetbrains-agent.jar(关注公号[吾非同]回复pycharm获取) ...
- Git裸仓库的分支(Active Branch)切换
Git裸仓库的Active Branch切换方法 在服务器上通过init --bare创建了一个裸仓库作为远程仓库使用,并且存在三个分支(master/kid/develop),但在使用中发现代码虽然 ...
- MATLAB中均值、方差、均方差的计算方法
MATLAB中均值.方差.均方差的计算方法 1. 均值 数学定义: Matlab函数:mean >>X=[1,2,3] >>mean(X)=2 如果X是一个矩阵,则其均 ...
- git 一个可以提高开发效率的命令:cherry-pick
各位码农朋友们一定有碰到过这样的情况:在develop分支上辛辛苦苦撸了一通代码后开发出功能模块A,B,C,这时老板过来说,年青人,我们现在先上线功能模块A,B.你一定心里一万只草泥马奔腾而过,但为了 ...
- Numpy-数组array操作
array是一个通用的同构数据多维容器,也就是说,其中的所有元素必须是相同类型的. 每个数组都有一个shape(一个表示各维度大小的元组)和一个dtype(一个用于说明数组数据类型的对象). 数组的形 ...