python新手总结(二)
random模块
随机小数
- random
- uniform
随机整数
- randint
- randrange
随机抽取
- choice
- sample
打乱顺序
- shuffle
random.random() 生成:0<n<1.0
uniform(x,y) 一定范围的随机浮点数 (包左包右)
random.uniform(x,y)
randint(x,y) 随机整数 (包左包右)
randrange(x,y,z) 随机整数(包左不包右)
random.randrange(10,100,4) #输出为10到100内以4递增的序列[10,14,18,22...]
choice(seq) 从序列中获取一个随机元素,参数seq表示有序类型,并不是一种特定类型,泛指list tuple 字符串等
import random
random.choice(range(10)) #输出0到10内随机整数
random.choice(range(10,100,2)) #输出随机值[10,12,14,16...]
random.choice("I love python") #输出随机字符I,o,v,p,y...
random.choice(("I love python")) #同上
random.choice(["I love python"]) #输出“I love python”
random.choice("I","love","python") #Error
random.choice(("I","love","python")) #输出随机字符串“I”,“love”,“python”
random.choice(["I","love","python"]) #输出随机字符串“I”,“love”,“python”
shuffle(list) 用于将一个列表中的元素打乱
sample() 从指定序列中随机获取k个元素作为一个片段返回,sample不会改变原有序列
a='1232445566'
b=[1,2,3,4,4,5]
print(random.sample(b,2))
print(random.sample(a,2))
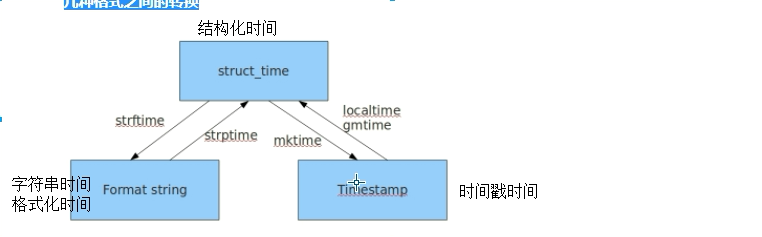
time 时间模块
time.strftime('%Y-%m-%d %H:%M:%S')
sys模块
sys 是与python解释器相关的
sys.path 寻找文件的路径
sys.modules 导入多少路径
在编译器不能运行
name=sys.argv[1] # 有点类似input() 不过input是阻塞的
pwd=sys.argv[2]
if name='alex' and pwd =='alex3714':
print('执行以下代码')
else:
exit()
os模块

print(os.getcwd()) # 在哪个地方执行这个文件,getcwd的结果就是哪个路径
removedirs
递归向上删除文件夹,只要删除当前目录之后,发现上一级目录也为空了,就把上一级目录删除
如果发现上一级目录有其他文件,就停止
os.listdir() (重要)列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方法打印

print(os.path.dirname(os.path.dirname(__file__)))#上一级再上一级目录,也就是工作区
序列化
得到一个字符串的结果,过程就叫序列化
字典/列表/数字/对象 -序列化-->字符串
为什么要序列化
- 要把内容写入文件
- 网络传输数据
eval不能随便用
dump dumps load loads
import json
dic={'aaa':'bbb','ccc':'ddd'}
str_dic=json.dumps(dic) # 序列化
print(dic)
print(str_dic,type(str_dic))
with open('json_dump','w') as f:
# f.write(str_dic) # 反序列化
json.dump(dic,f)
ret=json.loads(str_dic) # 反序列化
print(ret,type(ret))
with open('json_dump1') as f:
print(type(json.load(f)))
json的限制
json格式的key必须是字符串数据类型,如果是数字为key那么dump之后会强行转成字符串数据类型
json格式中的字符串只能是双引号
json是否支持元祖,对元组做value的字典会把元组强制转换成列表
dic={'abc':(1,2,3)}
str_dic=json.dumps(dic)
print(str_dic)
json是否支持元组做key,会报错
pickle
- pickle 支持几乎所有对象
dic={1:(12,3,4),('a','b'):4}
pic_dic=pickle.dumps(dic)# 序列化 看不见 bytes类型
print(pic_dic)
new_dic=pickle.loads(pic_dic)# 反序列化
对于对象的序列化需要这个对象对应的类在内存中
dump的结果是bytes, dump用的f文件句柄需要以wb的形式打开,load所用的f是'rb'模式
with open('pickle_demo','wb') as f:
pickle.dump(alex,f)
with open('pickle_demo','rb') as f:
wangcai=pickle.load(f)
print(wangcai.name)
with open('pickle_demo','rb') as f:
while True: # 不知道循环几次不能用for 用while
try:
print(pickle.load(f))
except EOFError:
break
import shelve # 不建议使用
# 存值
f=shelve.open("shelve_demo")
f['key']={'k1':(1,2,3),'k2':'v2'}
f.close()
# 取值
f=shelve.open('shelve_demo')
content=f['key']
f.close()
print(content)
加密md5 sha1
# hashlib.md5()
# hashlib.sha1()
#md5是一个算法,32位的字符串 ,每个字符串是一个十六进制
# sha1也是一个算法,40位的字符串,每个字符都是一个十六进制
# 算法相对复杂 计算速度也慢
md5_obj=hashlib.md5()
md5_obj.update(s.encode('utf-8'))
res=md5_obj.hexdigest()
print(res,len(res),type(res))
# 数据库 撞库
# 加盐
md5_obj=hashlib.md5("加盐".encode('utf-8'))
md5_obj.update(s.encode('utf-8'))
# 动态加盐
username=input('username:')
passwd=input('passwd')
md5obj=hashlib.md5(username.encode('utf-8'))
md5obj.update(passwd.encode('utf-8'))
print(md5obj.hexdigest())
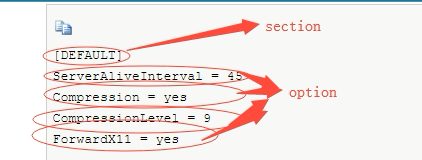
configparser模块
logging 模块
功能
- 日志格式的规范
- 操作的简化
- 日志的分级管理
logging 模块的使用
logging.basicConfig(level=logging.DEBUG) #级别
logging.debug('debug message') #调试模式
logging.info('info message') # 基础信息
logging.warning('warning message')# 警告
logging.error('error message') # 错误
logging.critical('critical message') # 严重错误
basicConfig
不能将一个log信息既能输出到屏幕上有输出到文件上
# logger 对象的形式来操作日志文件
# 创建一个logger对象
logger=logging.getLogger()
# 创建一个文件管理操作符
fh=logging.FileHandler()
# 创建一个屏幕管理操作符
sh=logging.StreamHandler()
# 创建一个日志输出的格式
format1=logging.Formatter('%(asctime)s-%(name)s-%(lecelname))
# 文件管理操作符 绑定一个格式
sh.setFormatter(format1)
# 屏幕管理操作符 绑定一个格式
# logger对象 绑定 文件管理操作符
# logger对象 绑定 屏幕管理操作符
网络编程
由于不同机器上的程序要通信,才产生了网络
server 服务端
client 客户端
b/s 架构 ----> 统一入口 (解耦分支)
b/s 和c/s 架构的关系
- b/s架构师c/s架构的一种
网关的概念
- 局域网中的机器想要访问局域网外的机器,需要通过网关
- 端口 找到的程序
- 在计算机上,没一个需要网络通信的程序,都会开一个端口
- 在同一时间只会有一个程序占用一个端口
- 不可能在同一时间有两个程序占用同一个端口
- 端口的范围0-65545,一般情况下8000之后的端口
- ip 确定唯一一台机器
- 端口--- 确定唯一的一个程序
- ip+端口 找到唯一的一台机器上的唯一的一个程序
tcp协议和udp协议
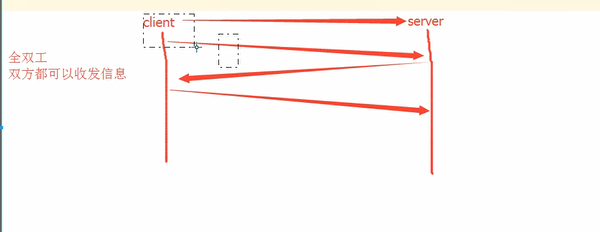
这个全双工的通信将占用两个计算机之间的通信线路,直到它被一方或双方关闭为止
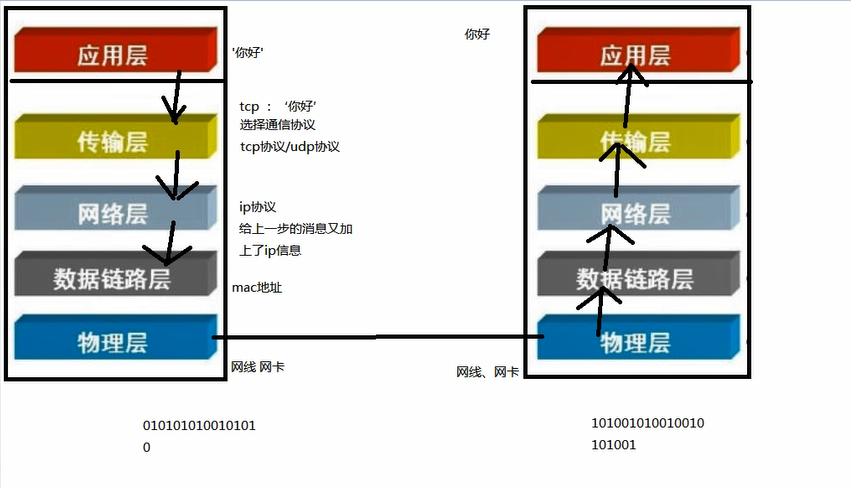
arp地址 通过ip找mac
ip协议属于网络osi 七层协议中的哪一层,网络层
tcp协议 udp协议属于传输层
arp 协议 属于数据链路层
黏包问题 不知道客户端发送的数据的长度
大文件的传输一定要按照字节读,每一次读固定的字节
> 实现一个大文件的上传或者下载---
server端
import json
import socket
import struct
sk=socket.socket()
sk.bind(('127.0.0.1',8090))
sk.listen()
buffer=1024
conn,addr=sk.accept()# 接受
head_len=conn.recv(4)
head_len=struct.unpack('i',head_len)[0]
json_head=conn.recv(head_len).decode('utf-8')
head=json.loads(json_head)
filesize=head['filesize']
with open(head['filename'],'wb') as f:
while filesize:
if filesize>=buffer:
content=conn.recv(buffer)
f.write(content)
filesize-=buffer
else:
content=conn.recv(filesize)
f.write(content)
filesize=0
break
conn.close()
sk.close()
client端
import json
import socket
import os
import struct
buffer = 1024
sk = socket.socket()
sk.connect(('127.0.0.1', 8090))
head = {# 发送文件
'filepath': r'文件路径',
'filename': r'文件名',
'filesize': None
}
file_path = os.path.join(head['filepath'], head['filename'])
filesize = os.path.getsize(file_path)
head['filesize'] = filesize
json_head = json.dumps(head) # 字典转成字符串
bytes_head = json_head.encode('utf-8') # 字符串转成bytes
print(json_head)
print(bytes_head)
head_len = len(bytes_head)# 计算head长度
pack_len = struct.pack('i', head_len)
sk.send(pack_len) # 先发报头的长度
sk.send(bytes_head)
with open(file_path, 'rb') as f:
while filesize:
if filesize > buffer:
content = f.read(buffer) # 每次读出来的内鹅绒
sk.send(content)
filesize -= buffer
else:
content = f.read(filesize)
f.read(content)
break
# 解决黏包问题
# 为什么会会出现黏包现象
# 首先 只有在TCP协议中才会出现黏包现象
# 是因为TCP协议是面向流的协议
# 在发送的数据传输的过程中还有缓存机制避免数据丢失
# 因此在连续发送小数据的时候,以及接受大小不符的时候都容易出现黏包现象
# 本质还是因为我们在接受数据的时候不知道发送的数据的长短
# 解决黏包问题
# 在传输大量数据之前先告诉接受端要发送的数据大小
# 如果想更漂亮的解决问题,可以通过struct模块来定制协议
# struct 模块
# pack unpack
# 模式: 'i'
# pack之后的长度: 4个字节
#unpack之后拿到的数据是一个元组:元组的第一个元素才是pack的值
进程
只有在运行当中的程序--进程
进程是操作系统中资源分配的最小单位
进程是怎么被调度的
- 先来先服务算法 FCFS
- 短作业优先算法
- 时间片轮转算法
- 多级反馈算法
进程
- 异步 只管调度 不等结果
- 同步 调度之后 还一定要等到结果
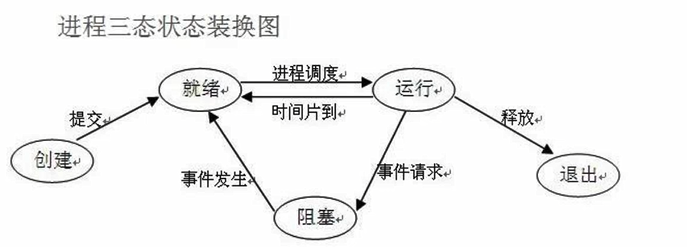
进程的状态
- 就绪 运行 阻塞
多进程
进程与进程之间是完全的数据隔离的
# from multiprocessing import Process
#
# n=100
# def func():
# global n
# n=n-1
# print(n)
#
# if __name__=='__main__':
# for i in range(10):
# p=Process(target=func)
# p.start()
# print('主进程:',n)
start 开启一个进程
join 用join 可以让主进程等待子进程结束
守护进程p.daemon=True
守护进程会随着主进程的代码执行结束而结束
正常的子进程没有执行完的时候主进程要一直等着
# 守护进程的进程的作用: 会随着主进程的代码的执行结束而结束,不会等待其他子进程
# 守护进程 要在start之前设置
# 守护进程中不能再开启子进程
def cal_time():
while True:
time.sleep(1)
print("过去了10秒")
if __name__=='__main__':
p=Process(target=cal_time())
p.daemon=True # 一定在开启进程之前设置
p.start()
for i in range(100):
time.sleep(0.1)
print('*'*i)
# p.is_alive() # 是否活着 True 代表进程还在False代表进程不在了
# p.terminatr() # 结束一个进程但是这个进程不会立刻被杀死
import time
from multiprocessing import Process
def func():
print('wahaha')
time.sleep(4)
print('qqxing')
if __name__=='__main__':
p=Process(target=func)
p.start()
print(p.is_alive())
p.terminate() # 关闭进程 异步
print(p.is_alive())
# 属性
# pid 查看这个进程 进程id
# name 查看这个进程的名字
class MyProcess(Process):
def run(self):
print('wahaha',self.name,self.pid)
time.sleep(5)
print('qqxing',self.name,self.pid)
if __name__=='__main__':
p= MyProcess()
p.start()
print(p.pid)
锁
lock.acquire() # 需要锁 拿钥匙
lock.release() # 释放锁 还钥匙
买票
import random
import time
from multiprocessing import Lock
from multiprocessing import Process
def search(i):
with open('ticket') as f:
print(i,json.load(f)['count'])
def get(i):
with open('ticket') as f:
ticket_num=json.load(f)['count']
time.sleep(random.random())
if ticket_num>0:
with open('ticket','w') as f:
json.dump({'count':ticket_num-1},f)
print('%s买到票了'%i)
else:
print('%s没票'%i)
def task(i,lock):
search(i) #查看票
lock.acquire()
get(i) #抢票
lock.release()
if __name__=='__main__':
lock=Lock()
for i in range(20):
p=Process(target=task,args=(i,lock))
p.start()
信号量
# 信号量
import random
import time
from multiprocessing import Semaphore, Process
# sem.acquire() # 需要钥匙
# print(0)
# sem.acquire() # 需要钥匙
# print(1)
# sem.acquire() # 需要钥匙
# print(2)
# sem.acquire() # 需要钥匙
# print(3)
# sem.acquire() # 需要钥匙
# print(4)
# 迷你唱吧 20个人 同一时间只能有4个人进去唱歌
def sing(i,sem):
sem.acquire()
print('%s:进入 ktv'%i)
time.sleep(random.randint(1,10))
print('%s: 出来 ktv'%i)
sem.release()
if __name__=='__main__':
sem = Semaphore(4)
for i in range(20):
Process(target=sing,args=(i,sem)).start()
事件
from multiprocessing import Event # 事件
e=Event() # 实例化一个事件 标志/交通信号灯
e.set() # 将标志变成非阻塞/交通灯变绿
e.wait() # 刚实例化出来的一个事件对象,默认的信号是阻塞信号/默认是红灯
# 执行到wait,要先看灯,绿灯行红灯停,如果在停的过程中,灯绿了,就变成非阻塞的
e.clear() # 将标志又变成阻塞/交通灯变红
e.is_set() # 是否则色 True 就是绿灯 False 就是红灯
# 红绿灯
import time
import random
def triffic_lifht(e):
while True:
if e.is_set():
time.sleep(3)
print('红灯亮')
e.clear() # 绿变红
else:
time.sleep(3)
print('绿灯亮')
e.set() # 红变绿
def car(i, e):
e.wait()
print('%s车通过' % i)
if __name__ == '__main__':
e = Event() # 立一个红灯
tra = Process(target=triffic_lifht, args=(e,))
tra.start() # 启动一个进程来控制红绿灯
for i in range(100):
if i % 6 == 0:
time.sleep(random.randint(1, 3))
car_pro = Process(target=car, args=(i, e))
car_pro.start()
队列 Queue 管道+锁 双向通信 数据安全
# 进程之间通信 可以使用multiprocessing 的Queue模块
# 队列有两种创建方式 第一种不传参数 这个队列就没有长度限制;
# 传参数,创建一个有最大长度限制的队列
# 提供两个重要方法:put get
# qsize 不怎么准确
def q_put(q):
q.put('hello')
def q_get(q):
print(q.get())
if __name__=='__main__':
q=Queue()
p=Process(target=q_put,args=(q,))
p.start()
p1=Process(target=q_get,args=(q,))
p1.start()
#通过队列实现了 主进程与子进程的通信 子进程与子进程之间的通信
# 生产者消费者模型
# 我要生产一个数据 然后给一个函数 让这个函数依赖这个数据进行运算,拿到结果--同步过程
# 做包子和吃包子
def producer(q):# 生产者
for i in range(100):
q.put('包子%s'%i)
def couseumer(q): #消费者
for i in range(100):
time.sleep(1)
print(q.get())
if __name__=='__main__':
q=Queue(10) # 托盘
p=Process(target=producer,args=(q,))
p.start()
c=Process(target=couseumer,args=(q,))
c.start()
c1 = Process(target=couseumer, args=(q,))
c1.start()
首先 对于内存空间来说 每次只有很少的数据会在内存中
对于生产与消费之间的不平衡来说
* 增加消费者或者增加生产者来调用效率
生产者-消费者模型(很重要)
joinableQueue put 和get 的一个技术机制,每次get数据之后发送task_done.put端接收
记数-1,直到计数为0就能感知到
# # 消费者已经把生产的所有数据都处理完了
# # 主进程 producer.join() 等待生产者结束
# # 设置消费者为守护进程
import time
import random
from multiprocessing import Process, JoinableQueue
def produceer(q,food):
for i in range(5):
q.put('%s-%s'%(food,i))
print('生产了%s'%food)
time.sleep(random.random())
q.join() # 等待消费者把所有数据处理完
def consumer(q,name):
while True:
food=q.get() # 生产者不生产还是生产的慢
if food==None:break
print('%s吃了%s'%(name,food))
q.task_done()
if __name__=='__main__':
q=JoinableQueue()
p1=Process(target=produceer,args=(q,'泔水'))
p1.start()
p2=Process(target=produceer,args=(q,'骨头'))
p2.start()
c1=Process(target=consumer,args=(q,'alex'))
c1.daemon=True
c1.start()
c2=Process(target=consumer,args=(q,'sun'))
c2.daemon=True
c2.start()
p1.join() # 等待p1执行完毕
p2.join() # 等待p2执行完毕
# 生产者生产的数据全部被消费---生产者进程结束
# 主进程执行结束----消费者守护进程结束
管道(不懂) Pipe 管道 双向通信 数据不安全
# 用管道 也能实现 生产者消费者模型
# socket 接受
# 等待数据
# 数据发送到操作系统
# 从操作系统copy到进程中
# 队列=管道+锁
# 双向通信
# 数据不安全 ,没有锁的机制
# 基于管道和锁 实现了队列---队列 用在同一台机器的多个进程之间通信
进程之间的数据共享Manager
- 但是数据是不安全的
进程池 Pool
# 进程池
# 造一个池子 放4个进程(员工)来用来完成工作
# 发任务
# 循环使用池子中进程完成任务
进程池为什么出现:开过多的进程1.开启进程浪费时间2.操作系统调度太多的进程也会影响效率
开进程池: 有几个现成的进程在池子里,有任务来了,就用这个池子中的进程处理任务
当所有的任务都处理完了,进程池关闭,回收所有的进程
from multiprocessing import Pool
# apply
def func(i):
i+=1
return i
if __name__=='__main__':
p=Pool(5)
res_l=[]
for i in range(20):
# p.apply(func,args=(i,)) # apply是同步提交任务的机制(几乎不用)
res=p.apply_async(func,args=(i,)) # apply_async 是异步提交任务的机制
res_l.append(res)
print(res.get()) # 阻塞:等待着任务的结果
p.close()# close必须加在join之前,不允许在添加新的任务了
p.join() # 等待子进程结束在往下执行
[print(i.get()) for i in res_l]
#apply_async
import time
from multiprocessing import Pool
def func(i):
time.sleep(1)
i+=1
return i
if __name__=='__main__':
p=Pool(4)
res_l=[]
for i in range(10):
res=p.apply_async(func,args=(i,))# apply target
res_l.append(res)
p.close() # 不能再往进程池中添加新的任务
p.join() # 阻塞等待 执行进程池中的所有任务直到执行结束
[print(res.get()) for res in res_l]
# map
def fun(i):
time.sleep(1)
i+=1
return i
if __name__=='__main__':
s=time.time()
p=Pool(4)
ret= p.map(fun,range(10)) # func(next(range(10))
print(ret)
print(time.time()-s)
# 参数 概念 回调函数 主进程执行, 参数是子进程执行的函数的返回值
# os.getpid()获取当前进程id os.getppid()获取父进程id
def func(i): # 多进程中的io多
print('子进程%s:%s'%(i,os.getpid))
return i*'*'
def call(arg):# 回调函数是在主进程中完成的,不能传参数,只能接受多进程中函数的返回值
print('回调:',os.getpid())
print(arg)
if __name__=='__main__':
print('---->',os.getpid())
p=Pool(5)
for i in range(10):
p.apply_async(func,args=(i,),callback=call)
p.close()
p.join()
线程
进程是资源分配的最小单位,线程是CPU调度的最小单位
每一个进程中至少有一个线程
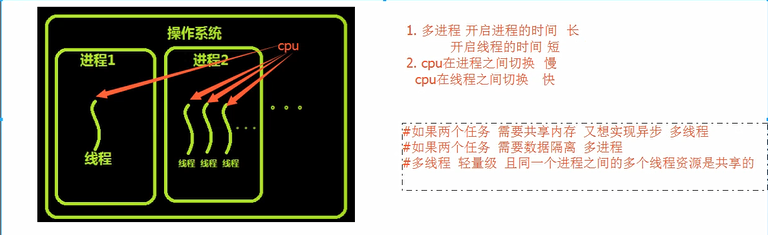
进程包含着线程
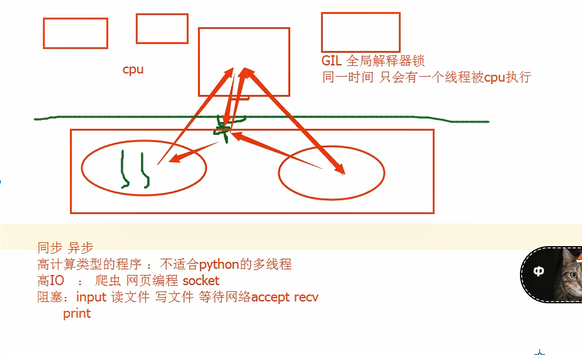
GIL 全局解释器锁 Cpython解释器
去掉GIL 保证数据安全 细粒度的锁 效率更低
一个程序中可以开启多进程多线程
import time
from threading import Thread
import os
class MyThead(Thread):
count = 0 # 静态属性
def __init__(self,arg1,arg2):
super().__init__()
self.arg1=arg1
self.arg2=arg2
def run(self):
MyThead.count += 1
time.sleep(1)
print('%s,%s,hello world,%s'%(self.arg1,self.arg2,os.getpid()))
for i in range(10):
t = MyThead(i,i*'*')
t.start()
# 计算开启的线程数量
# 多个子线程 共享 这个数据
import threading
def func(i):
time.sleep(0.5)
print(i,threading.currentThread().name,threading.currentThread().ident)
# 查看线程的默认名字,查看ident 线程id
# currentThread 查看线程的默认属性
for i in range(10):
t=threading.Thread(target=func,args=(i,))
t.start()
print(threading.enumerate()) # 返回正在运行着线程列表
print(threading.activeCount())# 统计当前有多少个线程
# 守护线程
import time
from threading import Thread
def func():
print('开始执行子线程')
time.sleep(3)
print('子线程执行完毕')
t=Thread(target=func)
t.setDaemon(True) # 进程设置守护进程,是一个属性 daemon=True
t.start()
t2=Thread(target=func)
t2.start()
t2.join()
# 守护线程 守护进程都是等待主线程中的代码 执行完毕
# t2=Thread(target=func)
# t2=start() -->代码执行完毕
# 守护线程就结束了
# 主线程还没结束 等待t2继承执行
from threading import RLock # 递归锁
from threading import Lock # 互斥锁
lock=RLock() # 递归锁 可以被两次acquire
# lock=Lock()
lock.acquire() # 等着钥匙
lock.acquire() # 等着钥匙
print(123)
lock.release()
lock.release()
# 递归锁 可以解决死锁问题
在多线程并发的情况下,同一个线程中,如果出现多次acquire 就可能产生死锁线程现象
信号量
面试题
[[0, 0, 0, 0, 0], [0, 1, 2, 3, 4], [0, 2, 4, 6, 8], [0, 3, 6, 9, 12]]
ret = [[i * j for j in range(5)] for i in range(4)]
print(ret)
面试题
'''
有一个文本
https://y.qq.com/
https://www.baidu.com/index.html
https://www.bilibli.com/imd.html
https://m.taobao.coom/cc.html
https://y.qq.com/
https://www.baidu.com/index.html
https://www.bilibli.com/imd.html
https://m.taobao.coom/cc.html
https://qq.lol.com/index.html
https://qq.lol.com/index.html
'''
'''
脚本输出
倒序次数 www.bilibilicom
'''
import re
from collections import Counter
with open('re.log') as f:
data = f.read()
ym_list=re.findall(r'https://(.*?)/.*?',data)
tm_dict=dict(Counter(ym_list))
#排序
ret=sorted(ym_list.items(),key=lambda x:x[1],reverse=True)
for i in ret:
print(i[1],i[0])
import random
import time
from threading import Semaphore, Thread
sem=Semaphore(5)# 一把锁有5把钥匙
def func(n,sem):
sem.acquire()
print('thread -%s'%n)
time.sleep(random.random())
print('thread -%s start'%n)
sem.release()
for i in range(20):
Thread(target=func,args=(i,sem)).start()
# 信号量和线程池有什么区别
# 相同点
#在aacquire之后,和线程池一样,同时在执行的只能有n个
# 不同点
#开的线程数不一样,线程池来说,一共就只能开5个线程,信号量有几个任务就开几个线程
# 对有信号量限制的程序来说,可以同时执行很多线程么
# 实际上 信号量并不影响线程或者进程的并发,只是在加锁的阶段进行流量限制
事件
# Event
# flag标志
# 刚刚创建的时候 flag=False
# wait() flag=False 阻塞
# # flag=True 非阻塞
# set() Fasle--> True
# clear() True-->False
# 连接mysql数据库
# 我连接三次数据库
# 每0.5秒连接一次
# 创建一个事件,来标志数据库的连接情况
# 如果连接成功就显示成功
# 否则就报错
def conn_mysql(): # 连接数据库
count=0
while not e.is_set():
if count>3:
raise TimeoutError
print('尝试连接第%s次'%count)
count+=1
e.wait(0.5) # 一直阻塞变成了只阻塞0.5
print('连接成功')
# 检测数据库的连接是否正常
def check_conn():
# 模拟连接检测的事件
time.sleep(random.randint(1,2))# 检测
e.set() # 告诉事件的标志数据库可以连接
e=Event()
check = Thread(target=check_conn)
check.start()
conn=Thread(target=conn_mysql)
conn.start()
定时器
from threading import Timer
def hello():
while True: # 这个线程一直在
time.sleep(1)
print("hello,world")
while True: # 每隔一段时间要开启一个线程
t=Timer(1,hello()) # 定时开启一个线程 ,执行一个任务
#定时: 多久之后,单位是s
# 要执行的任务: 函数名
t.start()
#sleep的时间
# sleep的时间短 就在线程内while True
# sleep的时间长 就在主线程while True
# 条件 condition notify_all notify
def run(n):
con.acquire()
con.wait() # 等着
print("run the thread :%s"%n)
con.release()
if __name__=='__main__':
con=threading.Condition()
for i in range(10):
t=threading.Thread(target=run,args=(i,))
t.start()
while True:
inp=input('>>>')
if inp=='q':
break
con.acquire()# condition中的锁是递归锁
if inp=='all':
con.notify_all()
else:
con.notify(int(inp)) #传递信号notify(1) 可以放行一个线程
con.release()
# 优先级
import queue
# q=queue.Queue() # 队列 线程安全的
#q.get()
#q.put()
#q.qsize()
lfq=queue.LifoQueue() # 后进先出 :栈
lfq.put(1)
lfq.put(2)
lfq.put(3)
lfq.put(4)
print(lfq.get())
print(lfq.get())
print(lfq.get())
print(lfq.get())
pq=queue.PriorityQueue() #值越小越优先,值相同就先进先出
pq.put((10,'a'))
pq.put((5,'b'))
pq.put((4,'c'))
pq.put((6,'d'))
print(pq.get())
线程池
# 线程池
# 线程池和进程池
# 是用来做池操作的最近新的模块
# 开启线程需要成本 成本就开启进程要低
# 高IO的情况下 开多线程
# 所以我们不能开启任意多个线程
# 开启线程池
# futures.ThreadPoolExecutor # 线程池
# futures.ProcessPoolExecutor #进程池
from concurrent import futures
def funcname(n):
print(n)
time.sleep(random.randint(1,3))
return n*'*'
threading_pool=futures.ThreadPoolExecutor(5)
# threading_pool.map(funcname,range(10)) # map天生异步,接受可迭代对象的数据,不支持返回值
# f_lst=[]
# for i in range(10):
# f=threading_pool.submit(funcname,i) # submit 合并了创建线程对象和start的功能
# f_lst.append(f)
# threading_pool.shutdown() #close() join()
# [print(i.result()) for i in f_lst] # 一定按照顺序出结果
# #f.result() 阻塞 等f执行完得到结果
# 回调函数 add_done_callback(回调函数的名字)
def call(args):
print(args.result())
threading_pool.submit(funcname,1).add_done_callback(call)
# 统一了入口和方法,简化了操作,降低了学习的时间成本
(gevent先放放,3.7安装不上)
协程
# from greenlet import greenlet # 在单线程中切换状态的模块
# import time
#
# def eat1():
# print("吃鸡腿1")
# g2.switch()
# time.sleep(5)
# print("吃鸡翅2")
# g2.switch()
#
#
# def eat2():
# print("吃饺子1")
# g1.switch()
# time.sleep(3)
# print('白切鸡')
#
#
# g1 = greenlet(eat1)
# g2 = greenlet(eat2)
# g1.switch()
# gevent 内部封装了greenlet模块
# 切换不能规避IO时间
# 协程的切换与正常程序的执行那个效率高
IO模型

阻塞IO: 工作效率低
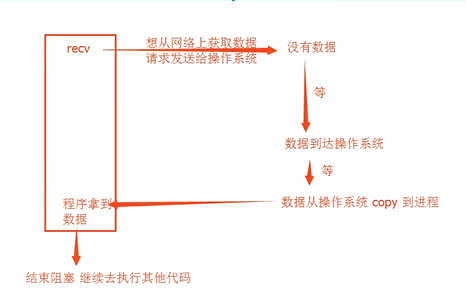
非阻塞IO:工作效率高,CPU的负担
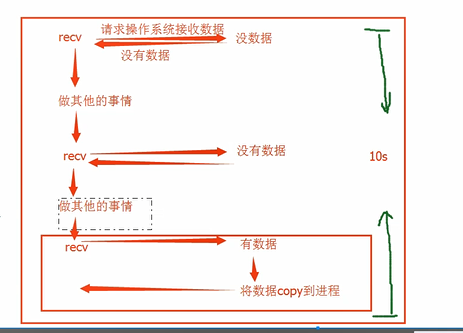
IO多路复用: 在有多个对象需要IO阻塞的时候,能够有效的减少阻塞带来的时间消耗,且能够在一定程度上减少CPU的负担(比较好的)
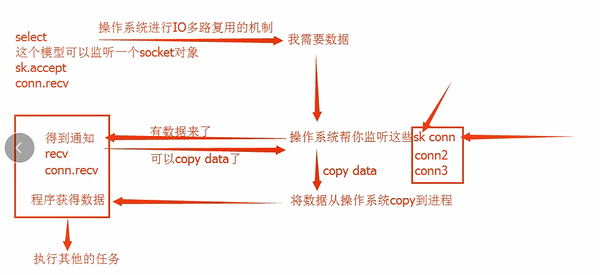
异步IO: asyncio 异步IO 工作效率高 CPU的负担少
MySQL
mysql: 是用于管理文件的一个软件
- 服务器软件
- socket服务器
- 本地文件操作
- 客户端软件
- socket客户端
- 发送指令
初始化:
- 服务端
mysqld -- initialize-inzecure - 用户名root 密码:空
启动服务端
- mysqld
客户端连接
- mysql -u root -p
发送命令:
show databases;
create database db1;
配置环境变量: 安装包的 bin配置
安装window服务
H:\mysql-5.7.24-winx64\bin\mysqld --install
H:\mysql-5.7.24-winx64\bin\mysqld --remove
启动服务
net start mysql
net stop mysql
操作文件夹
create database db2;
create database db2 default charset utf8;
show databases;
drop database db2;
操作文件
show tables;
create table t1(
列名 类型 null,
列名 类型 not null,
列名 类型 not null default 1,
列名 类型 not null auto_increment primary key,
id int,
name char(10)
) default charset=utf8;
create table t1(id int,name char(10)) engine=innodb default charset=utf8;
#innodb 支持事物
auto_increment 表示:自增
primary key: 表示 约束(不能为空) 加速查找
数字:
tinyint
int
bigint
FLOAT(float)
DOUBLE(double)
decimal(底层原理 按字符串存的数字 标准)
字符串:
char(长度) 速度快
varchar(长度) 节省空间
ps: 创建定长char的列往前方,
text
清空表
delete from t1;
truncate table t1;
删除表:
delete from t1 where id<6;
drop table t1;
修改:
update t1 set age=18;
操作文件中内容
插入数据
insert into t1(id,name) values(1,'alex')
查看数据库
select * from t1;
时间类型:
DATETIME(datetime)
enum(多选一)
set(多选多)
外键:
create table userinfo(
uid bigint auto_increment prinmary key,
name varchar(32),
department_id int,
constranint fk_user_depar foreign key ("department_id",) references department('id')
)
create table department(
id bigint auto_increment primary key,
title char(15)
)engine=innodb default charset=utf8;
bootCDN
where
关键字
like模糊查询%_in(100,200,300) not and or
between 9000 and 100
group by 分组查询
聚合函数
max()最大值
min() 最小值
avg() 平均值
sum() 求和
count() 求总个数
必须使用group by 才能使用group_concat()函数,将所有的name值连接
having 过滤
优先级 where>group by> having
order by 查询排序
select * from employee order by age ASC 升序
select * from employee order by age DESC 降序
limit 限定查询记录数(分页查询)
SELECT * FROM employee ORDER BY salary DESC
LIMIT 0,5; #从第0开始,即先查询出第一条,然后包含这一条在内往后查5条
查看表结构和数据
desc 表名;
select * from 表名;
多表查询
表名1 join 表名2 on 条件
select employee.id,employee.name,employee.age,employee.sex,department.name from employee inner join department on employee.dep_id=department.id;
exists 关键字查询表示存在,
- 当返回True时,外层查询语句进行查询,当返回值为false时,外层查询语句不进行查询
python新手总结(二)的更多相关文章
- python新手必躺的5大坑
python新手必躺的5大坑 对于Python新手来说,写代码很少考虑代码的效率和简洁性,因此容易造成代码冗长.执行慢,这些都是需要改进的地方.本文是想通过几个案列给新手一点启发,怎样写python代 ...
- python排序之二冒泡排序法
python排序之二冒泡排序法 如果你理解之前的插入排序法那冒泡排序法就很容易理解,冒泡排序是两个两个以向后位移的方式比较大小在互换的过程好了不多了先上代码吧如下: 首先还是一个无序列表lis,老规矩 ...
- Python 基础语法(二)
Python 基础语法(二) --------------------------------------------接 Python 基础语法(一) ------------------------ ...
- Python 数据分析(二 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识
Python 数据分析(二) 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识 第1节 groupby 技术 第2节 数据聚合 第3节 分组级运算和转换 第4 ...
- 初学 Python(十二)——高阶函数
初学 Python(十二)--高阶函数 初学 Python,主要整理一些学习到的知识点,这次是高阶函数. #-*- coding:utf-8 -*- ''''' 话说高阶函数: 能用函数作为参数的函数 ...
- python/MySQL练习题(二)
python/MySQL练习题(二) 查询各科成绩前三名的记录:(不考虑成绩并列情况) select score.sid,score.course_id,score.num,T.first_num,T ...
- Python/MySQL(二、表操作以及连接)
Python/MySQL(二.表操作以及连接) mysql表操作: 主键:一个表只能有一个主键.主键可以由多列组成. 外键 :可以进行联合外键,操作. mysql> create table y ...
- python下实现二叉堆以及堆排序
python下实现二叉堆以及堆排序 堆是一种特殊的树形结构, 堆中的数据存储满足一定的堆序.堆排序是一种选择排序, 其算法复杂度, 时间复杂度相对于其他的排序算法都有很大的优势. 堆分为大头堆和小头堆 ...
- python函数(二)
python函数(二) 变量的作用域 1.局部变量与全局变量 在函数内创建的变量被称为局部变量,这类变量的生命周期与函数相同,当函数执行完毕时,变量也就随之消失. 此类变量只能在函数内部调用,函数外不 ...
随机推荐
- SAX解析XML文档——(二)
SAX从上向下解析,一行一行解析.节省内存,不适合CRUD. XML文档: <?xml version="1.0" encoding="UTF-8"?&g ...
- JDK8 Lambda表达式对代码的简化
只是举个例子: public class LambdaDemo { public static String findData( String name , LambdaInterface finde ...
- Linux 内核里的“智能指针”【转】
转自:http://blog.jobbole.com/88279/ 众所周知,C/C++语言本身并不支持垃圾回收机制,虽然语言本身具有极高的灵活性,但是当遇到大型的项目时,繁琐的内存管理往往让人痛苦异 ...
- 驱动开发--【字符设备、块设备简介】【sky原创】
驱动开发 字符设备,块设备,网络设备 字符设备 以字节流的方式访问, 不能随机访问 有例外,显卡.EEPROM可以随机访问 EEPROM可以擦写1亿次,是一种字符设备,可以随机访问 读写是 ...
- JS实现双击内容变为可编辑状态
在一些网站上我们经常看到交互性很强的功能.一些用户资料可以直接双击出现文本框,并在此输入新的资料即可修改,无需再按确定按钮等.. 我在网上查了很多资料,但都有一个小bug,就是当获取焦点后,光标的位置 ...
- jvm系列二、JVM内存结构
原文链接:http://www.cnblogs.com/ityouknow/p/5610232.html 所有的Java开发人员可能会遇到这样的困惑?我该为堆内存设置多大空间呢?OutOfMemory ...
- MonkeyRunner之MonkeyRecorder录制回放脚本(亲测可正常运行)
MonkeyRunner可以录制和回放脚本 前置条件: 电脑连接手机,输入adb devices 看看返回是否手机设备列表(我是真机,模拟器也可以) 配置好安卓sdk和Python环境 step: 1 ...
- opencv error: insufficient memory错误解决办法
用opencv合成图像时出现的错误,大概4000多张会报错,在网上查阅一些博客时才知道原因.之前编译的时候用的是x86,切换到x64下可解决问题,具体: 1.项目->属性->配置管理器-& ...
- Sudo的用法和Visudo设置
身为程序员,你可以活在一个没有Windows的世界,当你离不开Unix(Linux,Mac...).而在Unix下面,你离不开terminal,离不开sudo. 你知道sudo command,然后输 ...
- php中的接口interface
* 接口 * 1.使用关键字:interface * 2.类是对象的模板,接口是类的模板 * 3.接口看作是一个特殊的类 * 4.接口中的方法,只声明不实现,与抽象类一样 * 5.接口中的方法必须是p ...