centos6.6安装hadoop-2.5.0(三、完全分布式安装)
操作系统:centos6.6(三台服务器)
环境:selinux disabled;iptables off;java 1.8.0_131
安装包:hadoop-2.5.0.tar.gz
hadoop完全分布式模式(生产环境使用)
1、节点规划

2、hosts配置
#vim /etc/hosts (三台机都做此配置)

3、解压安装包 (在bigdata-hadoop1上安装)
#tar zxvf hadoop-2.5.0.tar.gz -C /data/hadoop/hadoopfull/
4、设置JAVA_HOME路径

export JAVA_HOME="/data/jdk"
etc/共有三个配置文件需要添加java路径,hadoop-env.sh、mapred-env.sh、yarn-env.sh
5、修改配置文件(全部先在bigdata-hadoop1的机器上修改)
1)mapred-site.xml

mapreduce.frameword.name设置mapreduce任务运行在yarn上
mapreduce.jobhistory.address是设置mapreduce的历史服务器安装在bigdata-hadoop1机器上
mapreduce.jobhistory.webapp.address是设置历史服务器的web页面地址和端口
2)hdfs-site.xml

dfs.namenode.secondary.http-address设置secondarynamenode启动在bigdata-hadoop3上
3)core-site.xml

fs.defaultFS为NameNode的地址
hadoop.tmp.dir为hadoop的临时地址,NameNode和DataNode的数据文件都会存在这个目录对应的子目录下
4)slaves

5)yarn-site.xml
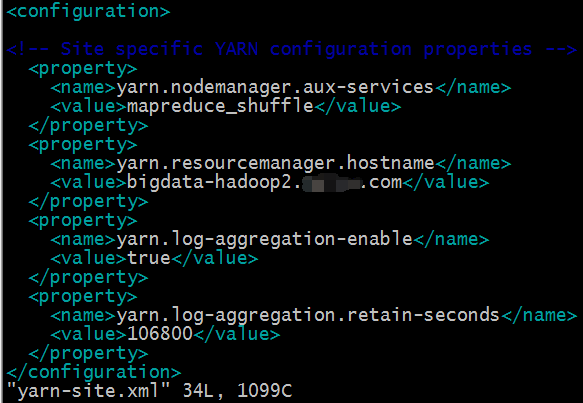
yarn.resourcemanager.hostname这个指定resourcemanager服务器指向bigdata-hadoop2
yarn.log-aggregation-enable是配置是否启用日志聚集功能
yarn.log-aggregation.retain-seconds是配置聚集的日志咋HDFS上最多保存多长时间
6、SSH无密码登录
hadoop服务器相互之间会通过SSH访问,以下步骤在hadoop服务器上都要执行
#ssh-keygen -t rsa
#ssh-copy-id bigdata-hadoop1.example.com
#ssh-copy-id bigdata-hadoop2.example.com
#ssh-copy-id bigdata-hadoop3.example.com
#ssh bigdata-hadoop1.example.com (测试登录一下)

7、分发hadoop文件(将bigdata-hadoop1上配置好的文件copy到bigdata-hadoop2和bigdata-hadoop3)
#scp -r hadoop-2.5.0/ bigdata-hadoop2.example.com:/data/hadoop/hadoopfull
#scp -r hadoop-2.5.0/ bigdata-hadoop3.example.com:/data/hadoop/hadoopfull

hadoop-2.5.0/share/doc目录的hadoop的文档,copy的时候可以把这些文档删除或者移到其他地方,提高copy的速度,doc/下的这些文档大约有1.6G
8、格式化NameNode
#bin/hdfs namenode -format
格式化完成之后会在tmp临时目录下生成dfs文件,如果需要重新格式化,要删除此dfs文件,否则NameNode的ID和DataNode的ID不一样,服务启动时会报错

9、启动集群
1)启动HDFS
#sbin/start-dfs.sh
这个脚本启动时namenode和datanode的分配
在bigdata-hadoop1上会看到namode和datanode

在bigdata-hadoop2上会看到datanode

在bigdata-hadoop3上会看到datanode和secondarynamenode

2)启动YARN
#/sbin/start-yarn.sh
在bigdata-hadoop1、bigdata-hadoop2和bigdata-hadoop3节点上会看到NodeManager

因为我们规划的ResourceManager是在bigdata-hadoop2上,所以需要在bigdata-hadoop2上启动ResourceManager
#sbin/yarn-daemon.sh start resourcemanager

3)启动日志服务
根据我们的规划,MapReduce日志服务在bigdata-hadoop1上启动
#sbin/mr-jobhistory-daemon.sh start JobHistoryServer

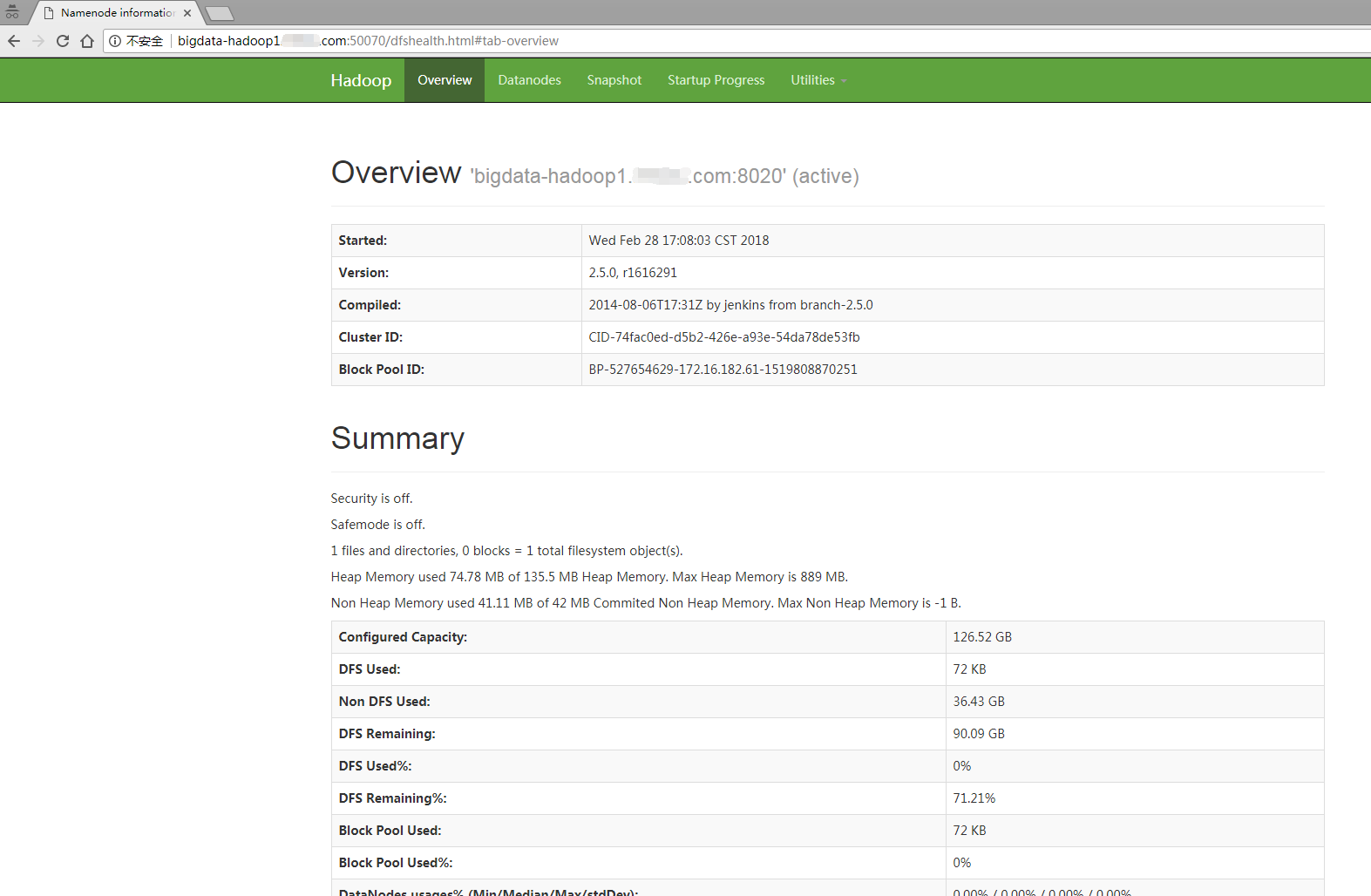
10、页面呈现
1)windows服务器上做hosts解析

2)访问地址bigdata-hadoop1.example.com:50070
3、访问地址bigdata-hadoop2.example.com:8088

11、JOB测试
1、准备mapredue的输入文件
#cat wc.input

2、创建输入目录input
#hadoop fs -mkdir /input(或者#bin/hdfs dfs -mkdir /input)

3、上传wc.input文件(或者#bin/hdfs dfs -put wc.input /input)
#hadoop fs -put wc.input /input

4、运行hadoop自带的mapreduce demo
#bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /input/wc.input /output1
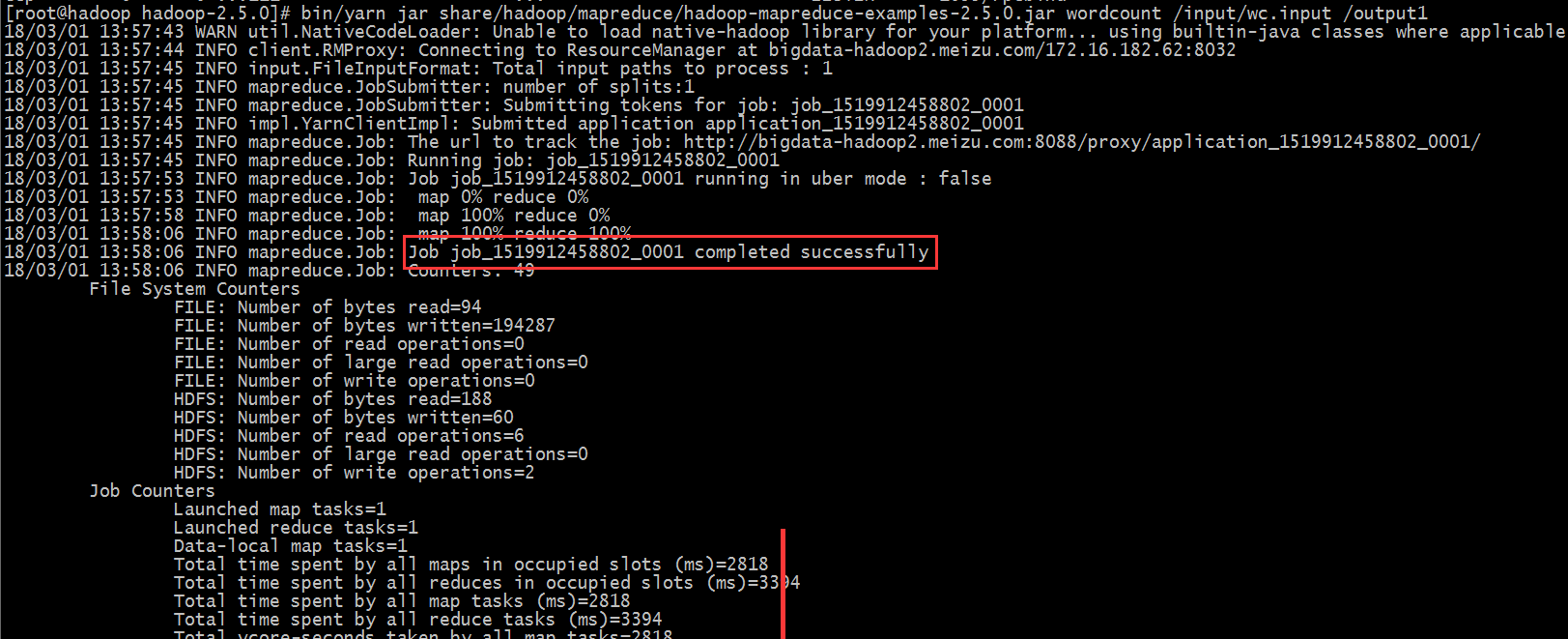
表示mapreduce计算成功的地方可以从三处查看:
第一个地方是执行过程中,从以上截图的Job job_1519912458802_0001 completed successfully表明执行成功
第二个地方是web界面
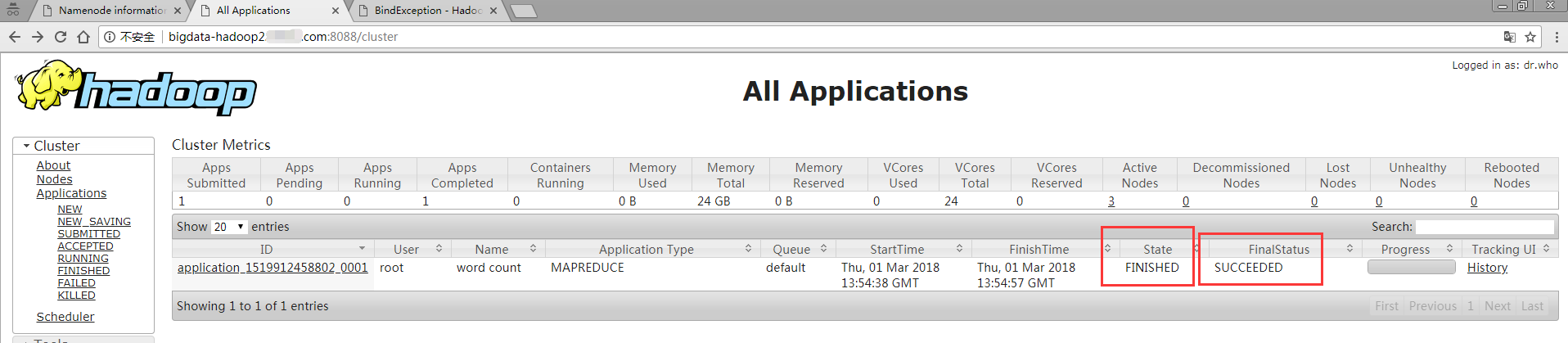
- 第三个地方是查看output1的目录#hadoop fs -ls /output1,看到_SUCCESS

12、查看mapreduce的计算结果
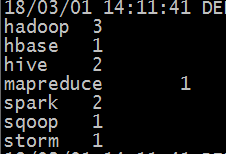
#hadoop fs -cat /output1/part-r-00000
centos6.6安装hadoop-2.5.0(三、完全分布式安装)的更多相关文章
- 菜鸟玩云计算之十九:Hadoop 2.5.0 HA 集群安装第2章
菜鸟玩云计算之十九:Hadoop 2.5.0 HA 集群安装第2章 cheungmine, 2014-10-26 在上一章中,我们准备好了计算机和软件.本章开始部署hadoop 高可用集群. 2 部署 ...
- 菜鸟玩云计算之十八:Hadoop 2.5.0 HA 集群安装第1章
菜鸟玩云计算之十八:Hadoop 2.5.0 HA 集群安装第1章 cheungmine, 2014-10-25 0 引言 在生产环境上安装Hadoop高可用集群一直是一个需要极度耐心和体力的细致工作 ...
- hadoop集群的搭建(分布式安装)
集群 计算机集群是一种计算机系统,他通过一组松散集成的计算机软件和硬件连接起来高度紧密地协同完成计算工作. 集群系统中的单个计算机通常称为节点,通常通过局域网连接. 集群技术的特点: 1.通过多台计算 ...
- Hadoop2.2.0多节点分布式安装及测试
众所周知,hadoop在10月底release了最新版2.2.很多国内的技术同仁都马上在网络上推出了自己对新版hadoop的配置心得.这其中主要分为两类: 1.单节点配置 这个太简单了,简单到只要懂点 ...
- Ubuntu 14.04 LTS 安装 spark 1.6.0 (伪分布式)-26号开始
需要下载的软件: 1.hadoop-2.6.4.tar.gz 下载网址:http://hadoop.apache.org/releases.html 2.scala-2.11.7.tgz 下载网址:h ...
- CentOS7-64bit 编译 Hadoop-2.5.0,并分布式安装
摘要 CentOS7-64bit 编译 Hadoop-2.5.0,并分布式安装 目录[-] 1.系统环境说明 2.安装前的准备工作 2.1 关闭防火墙 2.2 检查ssh安装情况,如果没有则安装ssh ...
- CentOS7.0分布式安装HADOOP 2.6.0笔记-转载的
三台虚拟机,IP地址通过路由器静态DHCP分配 (这样就无需设置host了). 三台机器信息如下 - 1. hadoop-a: 192.168.0.20 #master 2. ha ...
- CentOS 6.5 伪分布式 安装 hadoop 2.6.0
安装 jdk -openjdk* 检查安装:java -version 创建Hadoop用户,设置Hadoop用户使之可以免密码ssh到localhost su - hadoop ssh-keygen ...
- 安装hadoop 2.2.0
安装环境为 CentOS 64位系统, 大概分下面几个步奏, 0. 安装JDK1. 配置SSH2. 配置/etc/hosts3. 拷贝hadoop包到没台机器上4. 修改hadoop配置文件5. 关闭 ...
- Hadoop 2.2.0和HBase-0.98 安装snappy
1.安装须要的依赖包及软件 须要安装的依赖包有: gcc.c++. autoconf.automake.libtool 须要安装的配套软件有: Java6.Maven 关于上面的依赖包,假设在ubun ...
随机推荐
- react中的核心概念
DOM:浏览器中提供的概念: 虚拟DOM:框架中的概念:需要开发框架的程序员手动用JS对象来模拟DOM元素和嵌套关系: 本质:用JS对象,模拟DOM树: 目的:实现页面的按需更新: 要求:点击列头,实 ...
- DHCP机制
DHCP概念:局域网的网络协议,使用UDP协议工作,在工作过程中,它有两个对象,DHCP客户端和DHCP服务端,DHCP服务运行在67端口和68端口. 用途:1)个内部网络或网络服务供应商自动分配IP ...
- spring boot 2.0(一)权威发布spring boot2.0
Spring Boot2.0.0.RELEASE正式发布,在发布Spring Boot2.0的时候还出现一个小插曲,将Spring Boot2.0同步到Maven仓库的时候出现了错误,然后Spring ...
- spring boot(十四)shiro登录认证与权限管理
这篇文章我们来学习如何使用Spring Boot集成Apache Shiro.安全应该是互联网公司的一道生命线,几乎任何的公司都会涉及到这方面的需求.在Java领域一般有Spring Security ...
- element-ui radio 再次点击取消选中
<el-radio-group v-model="radio2"> <el-radio @click.native.prevent="clickitem ...
- 初次安装git配置用户名和邮箱
初次安装git配置用户名和邮箱 初次安装git需要配置用户名和邮箱,否则git会提示:please tell me who you are. 你需要运行命令来配置你的用户名和邮箱: $ git con ...
- Wannafly挑战赛27-A/B
链接:https://www.nowcoder.com/acm/contest/215/A来源:牛客网 题目描述 “White shores, and beyond. A far green coun ...
- Logstash 基础入门
原文地址:Logstash 基础入门博客地址:http://www.extlight.com 一.前言 Logstash 是一个开源的数据收集引擎,它具有备实时数据传输能力.它可以统一过滤来自不同源的 ...
- K-Means ++ 和 kmeans 区别
Kmeans算法的缺陷 聚类中心的个数K 需要事先给定,但在实际中这个 K 值的选定是非常难以估计的,很多时候,事先并不知道给定的数据集应该分成多少个类别才最合适Kmeans需要人为地确定初始聚类中心 ...
- npm run build 打包后,如何运行在本地查看效果(Apache服务)
目前,使用vue-cli脚手架写了一个前端项目,之前一直是使用npm run dev 在8080端口上进行本地调试.项目已经进行一半了,今天有时间突然想使用npm run build进行上线打包,试试 ...