RF/GBDT/XGBoost/LightGBM简单总结(完结)
这四种都是非常流行的集成学习(Ensemble Learning)方式,在本文简单总结一下它们的原理和使用方法.
Random Forest(随机森林):
- 随机森林属于Bagging,也就是有放回抽样,多数表决或简单平均.Bagging之间的基学习器是并列生成的.RF就是以决策树为基学习器的Bagging,进一步在决策树的训练过程中引入了随机特征选择,这会使单棵树的偏差增加,但总体而言有利于集成.RF的每个基学习器只使用了训练集中约63.2%的样本,剩下的样本可以用作袋外估计.
- 一般使用的是sklearn.ensemble中的RandomForestClassifier和RandomForestRegressor.
- 框架参数(相比GBDT较少,因为基学习器之间没有依赖关系):
- n_estimators=100:最大的基学习器的个数
- oob_score=False:是否采用袋外样本
- bootstrap=True:是否有放回采样
- n_jobs=1:并行job个数
- 决策树参数:
- max_features=None:划分时考虑的最大特征数,可选log2,sqrt,auto或浮点数按比例选择,也可以选整数按个数选择.
- max_depth:最大深度
- min_samples_split:内部节点划分所需最小样本数,如果样本小于这个值就不会再继续划分.
- min_saples_laef:叶子节点最少的样本数,小于这个值就会被剪枝.
- min_weight_fraction_leaf:叶子节点所有样本权重和的最小值
- max_leaf_nodes=None:最大叶子节点数,可以防止过拟合
- min_impurity_split:节点增长的最小不纯度
- criterion:CART树划分时对特征的评价标准,分类树默认gini,可选entropy,回归树默认mse,可选mae.
GBDT(梯度提升树)
- GBDT属于Boosting.它和Bagging都使用同样类型的分类器,区别是不同分类器通过串行训练获得,通过关注被已有分类器错分的数据来获得新的分类器.Boosting分类器的权重并不相等,每个权重对应分类器在上一轮迭代中的成功度.GBDT的关键是利用损失函数的负梯度方向作为残差的近似值,进而拟合出新的CART回归树.
- 一般使用的是sklearn.ensemble中的GradientBoostingClassifier和GradientBoostingRegressor.
- 框架参数:
- n_estimators=100:最大基学习器个数
- learning_rate=1:每个基学习器的权重缩减系数(步长)
- subsample=1.0:子采样,是不放回抽样,推荐值0.5~0.8
- loss:损失函数,分类模型默认deviance,可选exponential.回归模型默认ls,可选lad,huber和quantile.
- 决策树参数(与RF基本相同):
- max_features=None:划分时考虑的最大特征数,可选log2,sqrt,auto或浮点数按比例选择,也可以选整数按个数选择.
- max_depth:最大深度
- min_samples_split:内部节点划分所需最小样本数,如果样本小于这个值就不会再继续划分.
- min_saples_laef:叶子节点最少的样本数,小于这个值就会被剪枝.
- min_weight_fraction_leaf:叶子节点所有样本权重和的最小值
- max_leaf_nodes=None:最大叶子节点数,可以防止过拟合
- min_impurity_split:节点增长的最小不纯度
XGBoost
- 相比传统GBDT,XGBoost能自动利用CPU的多线程,支持线性分类器,使用二阶导数进行优化,在代价函数中加入了正则项,可以自动处理缺失值,支持并行(在特征粒度上的).
- 参考XGBoost python API和xgboost调参经验.
- 在训练过程一般用xgboost.train(),参数有:
- params:一个字典,训练参数的列表,形式是 {‘booster’:’gbtree’,’eta’:0.1}
- dtrain:训练数据
- num_boost_round:提升迭代的次数
- evals:用于对训练过程中进行评估列表中的元素
- obj:自定义目的函数
- feval:自定义评估函数
- maxmize:是否对评估函数最大化
- early_stopping_rounds:早停次数
- learning_rates:每一次提升的学习率的列表
- params参数:
- booster=gbtree:使用哪种基学习器,可选gbtree,gblinear或dart
- objective:目标函数,回归一般是reglinear,reg:logistic,count:poisson,分类一般是binary:logistic,rank:pairwise
- eta:更新中减少的步长
- max_depth:最大深度
- subsample:随即采样的比例
- min_child_weight:最小叶子节点样本权重和
- colsample_bytree:随即采样的列数的占比
- gamma:分裂最小loss,只有损失函数下降超过这个值节点才会分裂
- lambda:L2正则化的权重
LightGBM
- LightGBM是基于决策树的分布式梯度提升框架.它与XGBoost的区别是:
- 切分算法,XGBoost使用pre_sorted,LightGBM采用histogram.
- 决策树生长策略:XGBoost使用带深度限制的level-wise,一次分裂同一层的叶子.LightGBM采用leaf-wise,每次从当前所有叶子找到一个分裂增益最大的叶子.
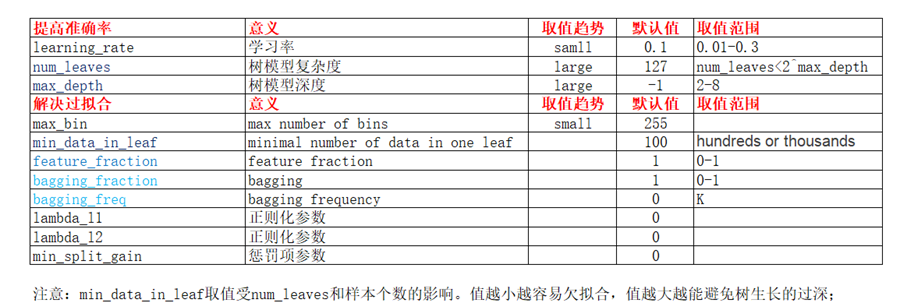
此外还有objective,metric等参数.
RF/GBDT/XGBoost/LightGBM简单总结(完结)的更多相关文章
- RF,GBDT,XGBoost,lightGBM的对比
转载地址:https://blog.csdn.net/u014248127/article/details/79015803 RF,GBDT,XGBoost,lightGBM都属于集成学习(Ensem ...
- 随机森林RF、XGBoost、GBDT和LightGBM的原理和区别
目录 1.基本知识点介绍 2.各个算法原理 2.1 随机森林 -- RandomForest 2.2 XGBoost算法 2.3 GBDT算法(Gradient Boosting Decision T ...
- R︱Yandex的梯度提升CatBoost 算法(官方述:超越XGBoost/lightGBM/h2o)
俄罗斯搜索巨头 Yandex 昨日宣布开源 CatBoost ,这是一种支持类别特征,基于梯度提升决策树的机器学习方法. CatBoost 是由 Yandex 的研究人员和工程师开发的,是 Matri ...
- GBDT && XGBOOST
GBDT && XGBOOST Outline Introduction GBDT Model XGBOOST Model ...
- 从信用卡欺诈模型看不平衡数据分类(1)数据层面:使用过采样是主流,过采样通常使用smote,或者少数使用数据复制。过采样后模型选择RF、xgboost、神经网络能够取得非常不错的效果。(2)模型层面:使用模型集成,样本不做处理,将各个模型进行特征选择、参数调优后进行集成,通常也能够取得不错的结果。(3)其他方法:偶尔可以使用异常检测技术,IF为主
总结:不平衡数据的分类,(1)数据层面:使用过采样是主流,过采样通常使用smote,或者少数使用数据复制.过采样后模型选择RF.xgboost.神经网络能够取得非常不错的效果.(2)模型层面:使用模型 ...
- 机器学习 GBDT+xgboost 决策树提升
目录 xgboost CART(Classify and Regression Tree) GBDT(Gradient Boosting Desicion Tree) GB思想(Gradient Bo ...
- RF, GBDT, XGB区别
GBDT与XGB区别 1. 传统GBDT以CART作为基分类器,xgboost还支持线性分类器(gblinear),这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回 ...
- xgboost&lightgbm调参指南
本文重点阐述了xgboost和lightgbm的主要参数和调参技巧,其理论部分可见集成学习,以下内容主要来自xgboost和LightGBM的官方文档. xgboost Xgboost参数主要分为三大 ...
- 机器学习之——集成算法,随机森林,Bootsing,Adaboost,Staking,GBDT,XGboost
集成学习 集成算法 随机森林(前身是bagging或者随机抽样)(并行算法) 提升算法(Boosting算法) GBDT(迭代决策树) (串行算法) Adaboost (串行算法) Stacking ...
随机推荐
- 站点默认访问https
需求简介 现在网站都是https访问了,再用http会显得很low,所以我要把网站设置为默认的https访问. 1nginx的rewrite方法 这应该是大家最容易想到的方法,将所有的http请求通过 ...
- 解决升级到Xcode10,react native项目运行报错问题
今天刚升级到Xcode10,就遇到两个报错问题 错误一:Xcode 10: Build input file double-conversion cannot be found error: Buil ...
- Java小项目迷你图书管理系统
package 迷你图书管理系统; import java.util.Scanner; public class BookMgr { public static void main(String[] ...
- uva1292 树形dp
这题说的是给了一个n个节点的一棵树,然后 你 从 这 棵 树 的 n 个 节点中 选择 尽量少的 点使得 每条边都至少有一个 士兵看守 dp[0][i]+=dp[1][j] dp[1][i]+=min ...
- centos配置用户级别的jdk的环境变量
前面讲解了centos配置jdk的环境变量 的root级别的jdk配置 ,这里讲解用户级别的jdk配置. 在用户的当前目录下,如下,有四个隐藏的文件,文件打头是.bash******: 1.编辑.ba ...
- asp.net 获取mp3 播放时长
1 Shell32 //添加引用:COM组件的Microsoft Shell Controls And Automation //然后引用 using Shell32; //如果出现“无法嵌入互操作类 ...
- Android查缺补漏(IPC篇)-- 进程间通讯之AIDL详解
本文作者:CodingBlock 文章链接:http://www.cnblogs.com/codingblock/p/8436529.html 进程间通讯篇系列文章目录: Android查缺补漏(IP ...
- php 二维数组
<?php // 一个二维数组 $cars=array ( array(,), array(,), array(,) ); ?>
- JavaScript权威指南--Javascript子集和扩展
知识要点 本章讨论javascript的子集和超集,其中子集的定义大部分处于安全考虑.只有使用这门语言的一个安全的子集编写脚本,才能让代码执行的更安全.更稳定.比如如何更安全地执行一段由不可信第三方提 ...
- Java Spring-事务管理
2017-11-12 16:31:59 Spring的事务管理分为两种: 编程式的事务管理:手动编写代码 声明式的事务管理:只需要配置就可以 一.最初的环境搭建 public interface Ac ...