spark读取mongodb数据写入hive表中
一 环境:
spark-2.2.; hive-1.1.; scala-2.11.; hadoop-2.6.-cdh-5.15.; jdk-1.8; mongodb-2.4.10;
二.数据情况:
MongoDB数据格式
{
"_id" : ObjectId("5ba0569cafc9ec432bd310a3"),
"id" : 7,
"name" : "7mongoDBi am using mongodb now",
"location" : "shanghai",
"sex" : "male",
"position" : "big data platform engineer"
}
Hive普通表 create table mgtohive_2(
id string,
name string,
age string,
deptno string
)row format delimited fields terminated by '\t'; create table mgtohive_2(
id int,
name string,
location string,
sex string,
position string
)
row format delimited fields terminated by '\t';
Hive分区表 create table mg_hive_external(
id int,
name string,
location string,
position string
)
PARTITIONED BY(sex string)
row format delimited fields terminated by '\t';
三.Eclipse+Maven+Java
3.1 依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.</artifactId>
<version>2.2.</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.</artifactId>
<version>2.2.</version>
</dependency>
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongo-java-driver</artifactId>
<version>3.6.</version>
</dependency>
<dependency>
<groupId>org.mongodb.spark</groupId>
<artifactId>mongo-spark-connector_2.</artifactId>
<version>2.2.</version>
</dependency>
3.2 代码:
package com.mobanker.mongo2hive.Mongo2Hive; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.hive.HiveContext;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import org.bson.Document; import com.mongodb.spark.MongoSpark; import java.io.File;
import java.util.ArrayList;
import java.util.List; public class Mongo2Hive {
public static void main(String[] args) {
//spark 2.x
String warehouseLocation = new File("spark-warehouse").getAbsolutePath();
SparkSession spark = SparkSession.builder()
.master("local[2]")
.appName("SparkReadMgToHive")
.config("spark.sql.warehouse.dir", warehouseLocation)
.config("spark.mongodb.input.uri", "mongodb://10.40.20.47:27017/test_db.test_table")
.enableHiveSupport()
.getOrCreate();
JavaSparkContext sc = new JavaSparkContext(spark.sparkContext()); // spark 1.x
// JavaSparkContext sc = new JavaSparkContext(conf);
// sc.addJar("/Users/mac/zhangchun/jar/mongo-spark-connector_2.11-2.2.2.jar");
// sc.addJar("/Users/mac/zhangchun/jar/mongo-java-driver-3.6.3.jar");
// SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("SparkReadMgToHive");
// conf.set("spark.mongodb.input.uri", "mongodb://127.0.0.1:27017/test.mgtest");
// conf.set("spark. serializer","org.apache.spark.serializer.KryoSerialzier");
// HiveContext sqlContext = new HiveContext(sc);
// //create df from mongo
// Dataset<Row> df = MongoSpark.read(sqlContext).load().toDF();
// df.select("id","name","name").show(); String querysql= "select id,name,location,sex,position from mgtohive_2 b";
String opType ="P"; SQLUtils sqlUtils = new SQLUtils();
List<String> column = sqlUtils.getColumns(querysql); //create rdd from mongo
JavaRDD<Document> rdd = MongoSpark.load(sc);
//将Document转成Object
JavaRDD<Object> Ordd = rdd.map(new Function<Document, Object>() {
public Object call(Document document){
List list = new ArrayList();
for (int i = ; i < column.size(); i++) {
list.add(String.valueOf(document.get(column.get(i))));
}
return list; // return list.toString().replace("[","").replace("]","");
}
});
System.out.println(Ordd.first());
//通过编程方式将RDD转成DF
List ls= new ArrayList();
for (int i = ; i < column.size(); i++) {
ls.add(column.get(i));
}
String schemaString = ls.toString().replace("[","").replace("]","").replace(" ","");
System.out.println(schemaString); List<StructField> fields = new ArrayList<StructField>();
for (String fieldName : schemaString.split(",")) {
StructField field = DataTypes.createStructField(fieldName, DataTypes.StringType, true);
fields.add(field);
}
StructType schema = DataTypes.createStructType(fields); JavaRDD<Row> rowRDD = Ordd.map((Function<Object, Row>) record -> {
List fileds = (List) record;
// String[] attributes = record.toString().split(",");
return RowFactory.create(fileds.toArray());
}); Dataset<Row> df = spark.createDataFrame(rowRDD,schema); //将DF写入到Hive中
//选择Hive数据库
spark.sql("use datalake");
//注册临时表
df.registerTempTable("mgtable"); if ("O".equals(opType.trim())) {
System.out.println("数据插入到Hive ordinary table");
Long t1 = System.currentTimeMillis();
spark.sql("insert into mgtohive_2 " + querysql + " " + "where b.id not in (select id from mgtohive_2)"); System.out.println("insert into mgtohive_2 " + querysql + " "); Long t2 = System.currentTimeMillis();
System.out.println("共耗时:" + (t2 - t1) / + "分钟");
}else if ("P".equals(opType.trim())) { System.out.println("数据插入到Hive dynamic partition table");
Long t3 = System.currentTimeMillis();
//必须设置以下参数 否则报错
spark.sql("set hive.exec.dynamic.partition.mode=nonstrict");
//sex为分区字段 select语句最后一个字段必须是sex
spark.sql("insert into mg_hive_external partition(sex) select id,name,location,position,sex from mgtable b where b.id not in (select id from mg_hive_external)");
Long t4 = System.currentTimeMillis();
System.out.println("共耗时:"+(t4 -t3)/+ "分钟");
}
spark.stop();
}
}
工具类:
package com.mobanker.mongo2hive.Mongo2Hive; import java.util.ArrayList;
import java.util.List; public class SQLUtils {
public List<String> getColumns(String querysql){
List<String> column = new ArrayList<String>();
String tmp = querysql.substring(querysql.indexOf("select") + ,
querysql.indexOf("from")).trim();
if (tmp.indexOf("*") == -){
String cols[] = tmp.split(",");
for (String c:cols){
column.add(c);
}
}
return column;
} public String getTBname(String querysql){
String tmp = querysql.substring(querysql.indexOf("from")+).trim();
int sx = tmp.indexOf(" ");
if(sx == -){
return tmp;
}else {
return tmp.substring(,sx);
}
}
}
四 错误解决办法:
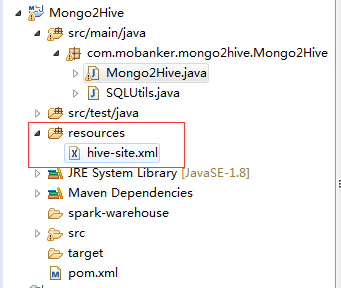
下载cdh集群Hive的hive-site.xml文件,在项目中新建resources文件夹,讲hive-site.xml配置文件放入其中:
五 执行情况:
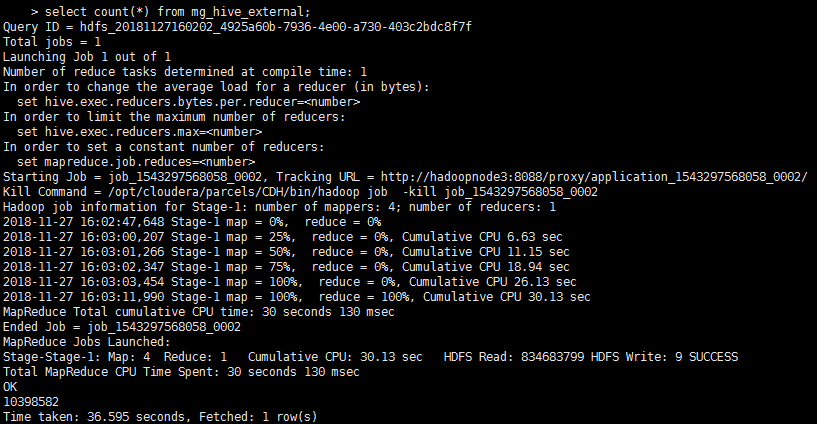
耗时14mins,写入hive表10398582条数据:
spark读取mongodb数据写入hive表中的更多相关文章
- spark 将dataframe数据写入Hive分区表
从spark1.2 到spark1.3,spark SQL中的SchemaRDD变为了DataFrame,DataFrame相对于SchemaRDD有了较大改变,同时提供了更多好用且方便的API.Da ...
- 通过js获取前台数据向一般处理程序传递Json数据,并解析Json数据,将前台传来的Json数据写入数据库表中
摘自:http://blog.csdn.net/mazhaojuan/article/details/8592015 通过js获取前台数据向一般处理程序传递Json数据,并解析Json数据,将前台传来 ...
- 《项目经验》--通过js获取前台数据向一般处理程序传递Json数据,并解析Json数据,将前台传来的Json数据写入数据库表中
先看一下我要实现的功能界面: 这个界面的功能在图中已有展现,课程分配(教师教授哪门课程)在之前的页面中已做好.这个页面主要实现的是授课,即给老师教授的课程分配学生.此页面实现功能的步骤已在页面 ...
- sqoop导入数据到hive表中的相关操作
1.使用sqoop创建表并且指定对应的hive表中的字段的数据类型,同时指定该表的分区字段名称 sqoop create-hive-table --connect "jdbc:oracle: ...
- 将python的字典格式数据写入excei表中
上面的为最终结果 import requests import re import xlwt import json # 导入必须的包: xlwt,json,requests,re. headers ...
- 读取Excel数据到Table表中
方法一: try { List<DBUtility.CommandInfo> list = new List<DBUtility.CommandInfo>(); string ...
- 批量导入数据到hive表中:假设我有60张主子表如何批量创建导入数据
背景:根据业务需要需要把60张主子表批量入库到hive表. 创建测试数据: def createBatchTestFile(): Unit = { to ) { val sWriter = new P ...
- Hive 将本地数据导入hive表中
# 导入 load data local inpath '/root/mr/The_Man_of_Property.txt' insert into table article; # 提示 FAILE ...
- 将DataFrame数据如何写入到Hive表中
1.将DataFrame数据如何写入到Hive表中?2.通过那个API实现创建spark临时表?3.如何将DataFrame数据写入hive指定数据表的分区中? 从spark1.2 到spark1.3 ...
随机推荐
- 对deferred(延迟对象)的理解
deferred对象从jQuery 1.5.0开始引入 什么是defrred对象 开发网站过程中,我们经常遇到某些耗时长的JS操作,其中,既有异步操作(如Ajax读取服务器数据),也有同步的操作(如遍 ...
- 【vue】饿了么项目-goods商品列表页开发
1.flex 属性是 flex-grow.flex-shrink 和 flex-basis 属性的简写属性. flex-grow 一个数字,规定项目将相对于其他灵活的项目进行扩展的量. flex-sh ...
- 2019.3.26 为什么说HTTP是无状态协议/无连接
无状态 1.协议对于事务处理没有记忆能力 2.对同一个url请求没有上下文关系 3.每次的请求都是独立的,它的执行情况和结果与前面的请求和之后的请求时无直接关系的,它不会受前面的请求应答情况直接影响, ...
- 《metasploit渗透测试魔鬼训练营》学习笔记第五章--网络服务渗透攻击
三.网络服务渗透攻击 3.1 内存攻防技术 3.1.1 缓冲区溢出漏洞机理 缓冲区溢出是程序由于缺乏对缓冲区的边界条件检查而引起的一种异常行为. ...
- 码农视角 - Angular 框架起步
开发环境 1.npm 安装最新的Nodejs,便包含此工具.类似Nuget一样的东西,不过与Nuget不同的是,这玩意完全是命令行的.然后用npm来安装开发环境,也就是下边的angular cli. ...
- 搭建springboot项目
1.搭建环境windows10+jdk1.8+eclipse4.8+maven 2.为了学习微服务架构学习搭建基础项目 3.分为两种搭建方式为maven项目和单独建立springboot项目(ecli ...
- ES6读书笔记(一)
前言 前段时间整理了ES5的读书笔记:<你可能遗漏的JS知识点(一)>.<你可能遗漏的JS知识点(二)>,现在轮到ES6了,总共分为四篇,以便于知识点的梳理和查看,本篇内容包括 ...
- 进程通信-Queue
进程通信-Queue Queue消息队列是python进程通信的其中一种方式.需要引入multiprocessing包中的Queue函数(这是函数,不是类). 有一个queue包,里面也有Queue, ...
- MySQL->复制表[20180509]
MySQL复制表 通常复制表所采用CREATE TABLE .... SELECT 方式将资料复制,但无法将旧表中的索引,约束(除非空以外的)也复制. 完整复制MySQL数据表所需步骤: ...
- Java面试题整理1
Java基础部分 JDK和JRE有什么区别? JDK:Java Development Kit 的简称,java 开发工具包,提供了 java 的开发环境和运行环境.JRE:Java Runtime ...