一文读懂spark yarn集群搭建
文是超简单的spark yarn配置教程:
yarn是hadoop的一个子项目,目的是用于管理分布式计算资源,在yarn上面搭建spark集群需要配置好hadoop和spark。我在搭建集群的时候有3台虚拟机,都是centos系统的。下面就开始一步一步地进行集群搭建。
一、配置hosts文件
hosts文件是主机名到ip的映射,目的是为了方便地查找主机,而不用去记各个主机的IP地址,比如配置master 10.218.20.210 就是为10.218.20.210地址取名为master,在以后的url中就可以用master代替10.218.20.210。
这里我们为了在配置文件中更方便地写url,所以需要在这里配置各个节点的host-ip映射。
10.217.2.240 master
10.217.2.241 slave1
10.217.2.242 slave2
这里我的三个节点分别对应master slave1 slave2.
二、配置ssh
启动hdfs和spark的时候各个节点需要相互访问,所以要配置好ssh秘钥。可以为每个主机生成各自的rsa秘钥也可以只生成一个rsa秘钥,并发送到所有主机。
三、安装JAVA
spark是基于java写的,这里把java解压到某目录然后配置环境变量,修改/etc/profile
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_77
export JRE_HOME=$JAVA_HOME/jre
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
export CLASSPATH=$CLASSPATH:.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
四、安装scala
使用spark最好还是用scala语言,解压后配置环境变量,修改/etc/profile
export SCALA_HOME=/home/hadoop/scala-2.10.6
export PATH=$PATH:$SCALA_HOME/bin
五、安装配置HADOOP和YARN
yarn的包是包含在hadoop里面的,解压hadoop压缩包,tar -zcvf hadoop-2.7.5.tar.gz,配置环境变量,
export HADOOP_HOME=/home/hadoop/hadoop-2.7.5
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export YARN_HOME=/home/hadoop/hadoop-2.7.5
export YARN_CONF_DIR=${YARN_HOME}/etc/hadoop
环境变量配置完了,现在要配置hadoop自身的配置文件,目录在hadoop目录下的etc/hadoop文件夹,里面有很多配置文件.我们需要配置七个:hadoop-env.sh,yarn-env.sh,slaves,core-site.xml,hdfs-site.xml,maprd-site.xml,yarn-site.xml。
hadoop-env.sh:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_77
yarn-env.sh:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_77
slaves:
slave1
slave2
core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hadoop-2.7.2/tmp</value>
</property>
</configuration>
hdfs-site.xml:
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop-2.7.5/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop-2.7.5/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>fang-ubuntu:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
配置好了以后,需要调用hadoop namenode 格式化,配置改变以后就需要格式化namenode,其实就是创建一些目录,增添一些文件,以后配置不变的话就不需要再格式化。如果配置变了就需要删除tmp,dfs,logs文件夹,再进行格式化。
bin/hadoop namenode -format #格式化namenode
现在就可以启动hdfs系统和yarn系统了:
sbin/start-dfs.sh #启动dfs
sbin/start-yarn.sh #启动yarn
启动成功后可以使用jps命令查看各个节点上是否启动了对应进程。
master节点上:
[root@CTUGT240X sbin]# jps
23809 SecondaryNameNode
23971 ResourceManager
24071 NodeManager
23512 NameNode
23644 DataNode
24173 Jps
slave节点上:
[root@CTUGT241X hadoop]# jps
31536 Jps
31351 DataNode
31454 NodeManager
六、安装配置spark:
解压spark压缩包
tar -zcvf spark-2.2.0-bin-hadoop2.7.tar
配置spark配置文件:
cd ~spark-2.2.0-bin-hadoop2.7/conf #进入spark配置目录
cp spark-env.sh.template spark-env.sh #从配置模板复制
vim spark-env.sh #添加配置内容
在spark-env.sh末尾添加以下内容(这是我的配置,你可以自行修改):
export SPARK_HOME=/home/hadoop/spark-2.2.0-bin-hadoop2.7
export SCALA_HOME=/home/hadoop/scala-2.11.12
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_77
export HADOOP_HOME=/home/hadoop/hadoop-2.7.5
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$YARN_HOME/etc/hadoop
export SPARK_MASTER_IP=20.2.217.123
SPARK_LOCAL_DIRS=/home/haodop/spark-2.2.0-bin-hadoop2.7
SPARK_DRIVER_MEMORY=1G
export SPARK_LIBARY_PATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$HADOOP_HOME/lib/native
上述的版本那些根据个人的进行修改,还有运行内存那些要根据硬件配置来,太大了启动spark会失败。
slaves文件:
slave1
slave2
配置好后再各个节点上同步,scp ...
启动spark,
sbin/start-dfs.sh
sbin/start-yarn.sh
看终端报错没有,没报错基本就成功了,再去UI看看,访问:http://master:8088
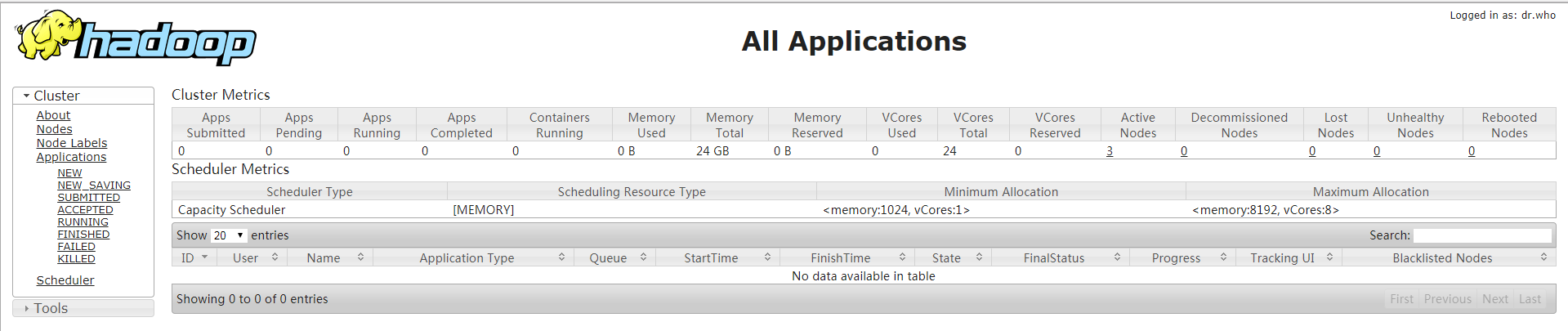
一文读懂spark yarn集群搭建的更多相关文章
- 04、Spark Standalone集群搭建
04.Spark Standalone集群搭建 4.1 集群概述 独立模式是Spark集群模式之一,需要在多台节点上安装spark软件包,并分别启动master节点和worker节点.master节点 ...
- spark yarn 集群提交kafka代码
配置好hadoop的环境,具体根据http://blog.csdn.net/u010638969/article/details/51283216博客所写的进行配置. 运行start-dfs.sh启动 ...
- Spark on Yarn集群搭建
软件环境: linux系统: CentOS6.7 Hadoop版本: 2.6.5 zookeeper版本: 3.4.8 主机配置: 一共m1, m2, m3这五部机, 每部主机的用户名都为centos ...
- Spark之集群搭建
注意,这种安装方式是集群方式:然后有常用两种运行模式: standalone , on yarn 区别就是在编写 standalone 与 onyarn 的程序时的配置不一样,具体请参照spar2中的 ...
- hadoop - spark on yarn 集群搭建
一.环境准备 1. 机器: 3 台虚拟机 机器 角色 l-qta3.sp.beta.cn0 NameNode,ResourceManager,spark的master l-querydiff1.sp ...
- 大数据-spark HA集群搭建
一.安装scala 我们安装的是scala-2.11.8 5台机器全部安装 下载需要的安装包,放到特定的目录下/opt/workspace/并进行解压 1.解压缩 [root@master1 ~]# ...
- Spark简单集群搭建
1. 上传spark-2.2.0-bin-hadoop2.7.tgz安装包到/home/dtouding目录下 2. 解压安装包到/bigdata/目录下,tar –zxvf spark-2.2.0- ...
- 一文读懂跨平台框架 Flutter 的搭建与运行
作者:个推iOS开发工程师 伊泽瑞尔 Flutter是Google推出的跨平台的解决方案,用以帮助开发者在 Android 和 iOS 两个平台开发高质量原生应用的全新移动 UI 框架. 之前我们为大 ...
- Spark程序提交到Yarn集群时所遇异常
Exception 1:当我们将任务提交给Spark Yarn集群时,大多会出现以下异常,如下: 14/08/09 11:45:32 WARN component.AbstractLifeCycle: ...
随机推荐
- 每日一条 git 命令行:git clone https://xxxxx.git -b 12.0 --depth 1
每日一条 git 命令行:git clone https://xxxxx.git -b 12.0 --depth 1 -b 12.0:分支 12.0 --depth 1:depth 克隆深度,1 为最 ...
- CentOS下用yum配置php+mysql+apache
环境: CentOS5.4 yum 想在一台CentOS的机器上安装配置支持dedeCMS的php+mysql+apache环境,把摸索的过程记录如下: 1. 安装Apahce, PHP, Mysq ...
- Python 定期检查Build_setting的编译情况
#!/usr/bin/python #_*_ coding:utf-8 _*_ import time from email.MIMEText import MIMEText from email.M ...
- emacs之自动完成括号
网上抄来的问题不少,看emacswiki,用autopairs即可 emacsConfig/autopair-setting.el (require 'autopair) (autopair-glob ...
- SlickEdit V21 2016 破解教程,win linux mac
最近主要工作系统转到LInux上面来了,Slickedit的安装破解也费了些事,今天将过程整理一下做个记录. 说明:SlickEdit pro V21.03 Linux 64位实测可用,MAC实测可用 ...
- [Android] 开发第七天
在另一台机器上安装 Android-Studio ,结果卡在了 Gradle 的下载界面上,网上各种方案都试了一遍,最终解决办法是: 然后新建了一个 App ,创建了新的签名并上传到手机上,安装时直接 ...
- 1027代码审计平台 1-sonar scanner
1.代码审计 1.1综合性的代码分析平台 sonar支持自定义规则,较多的公司使用 360火线 1.2IDE辅助功能 Xcode.Android studio 阿里巴巴Java开发手机ide插件支持 ...
- windows8.1中组件服务DCOM配置里属性灰色不可修改的解决办法
由于电脑升级,更换成了windows8.1的64位操作系统,今天遇到组件服务中DCOM配置里IIS Admin Service属性呈现灰色,不能修改. 查找官方文档,原来这是win8.1 x64的安全 ...
- pythonNetday06
进程 Process(target,name,args,kwargs) p.pid : 创建的新的进程的PID号 p.is_alive() 判断进程是否处于alive状态 p.daemon = Tru ...
- linux-ububtu64位安装docker,及基本命令
安装:貌似只支持64位 sudo apt-get install docker sudo apt-get install docker.io sudo apt-get install docker-r ...