机器学习之决策树(ID3)算法
最近刚把《机器学习实战》中的决策树过了一遍,接下来通过书中的实例,来温习决策树构造算法中的ID3算法。
海洋生物数据:
| 不浮出水面是否可以生存 | 是否有脚蹼 | 属于鱼类 | |
| 1 | 是 | 是 | 是 |
| 2 | 是 | 是 | 是 |
| 3 | 是 | 否 | 否 |
| 4 | 否 | 是 | 否 |
| 5 | 否 | 是 | 否 |
转换成数据集:
def createDataSet():
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
labels = ['no surfacing','flippers']
return dataSet, labels
一、基础知识
1、熵
我把它简单的理解为用来度量数据的无序程度。数据越有序,熵值越低;数据越混乱或者分散,熵值越高。所以数据集分类后标签越统一,熵越低;标签越分散,熵越高。
更理论一点的解释:
熵被定义为信息的期望值,而如何理解信息?如果待分类的事物可能划分在多个分类中,则符号的信息定义为:
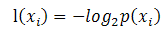
其中xi是选择该分类的概率,即 该类别个数 / 总个数。
为了计算熵,我们需要计算所有类别所有可能值包含的信息期望值,公式如下:
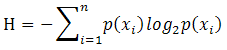 其中n是分类的数目。
其中n是分类的数目。
计算给定数据集的香农熵:
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
#创建字典,计算每种标签对应的样本数
labelCounts = {} for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
#根据上面的公式计算香农熵
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * log(prob,2)
return shannonEnt
运行代码,数据集myDat1只有两个类别,myDat2有三个类别:
>>> myDat1
[[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
>>> trees.calcShannonEnt(myDat1)
0.9709505944546686
>>> myDat2
[[1, 1, 'maybe'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
>>> trees.calcShannonEnt(myDat2)
1.3709505944546687
2、信息增益
信息增益可以衡量划分数据集前后数据(标签)向有序性发展的程度。
信息增益=原数据香农熵-划分数据集之后的新数据香农熵
二、按给定特征划分数据集
三个输入参数:待划分的数据集、划分数据集的特征位置、需要满足的当前特征的值
def splitDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
#获得除当前位置以外的特征元素
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
#把每个样本特征堆叠在一起,变成一个子集合
retDataSet.append(reducedFeatVec)
return retDataSet
运行结果:
>>> myDat
[[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
>>> trees.splitDataSet(myDat,0,1)
[[1, 'yes'], [1, 'yes'], [0, 'no']]
>>> trees.splitDataSet(myDat,0,0)
[[1, 'no'], [1, 'no']]
三、选择最好的数据集划分方式,即选择出最合适的特征用于划分数据集
def chooseBestFeatureToSplit(dataSet):
# 计算出数据集的特征个数
numFeatures = len(dataSet[0]) – 1
# 算出原始数据集的香农熵
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures):
# 抽取出数据集中所有第i个特征
featList = [example[i] for example in dataSet]
# 当前特征集合
uniqueVals = set(featList)
newEntropy = 0.0
# 根据特征划分数据集,并计算出香农熵和信息增益
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy # 返回最大信息增益的特征
if(infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
四、如果数据集已经处理了所有特征属性,但是类标依然不是唯一的,此时采用多数表决的方式决定该叶子节点的分类。
def majorityCnt(classList):
classCount={}
for vote in classList:
if vote not in classCount.keys(): classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
五、创建决策树
接下来我们将利用上面学习的单元模块创建决策树。
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
# 如果划分的数据集只有一个类别,则返回此类别
if classList.count(classList[0]) == len(classList):
return classList[0]
# 如果使用完所有特征属性之后,类别标签仍不唯一,则使用majorityCnt函数,多数表决法,哪种类别标签多,则分为此类别
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
return myTree
每次遇到递归问题总会头脑发昏,为了便于理解,我把一个创建决策树的处理过程重头到尾梳理了一遍。
原始数据集:
dataset: [[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
labels: [no surfacing, flippers]
在调用createTree(dataSet,labels)函数之后,数据操作如下(每一个色块代表一次完整的createTree调用过程):
|
1、 dataset: [[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']] labels: [no surfacing, flippers] classList=['yes', 'yes', 'no', 'no', 'no'] 选择最好的特征来分类:bestFeat= 0 bestFeatLabel =no surfacing 构造树:myTree {'no surfacing': {}} 去除这个特征后,label=['flippers'] 这个特征(no surfacing)的值:featValues= [1, 1, 1, 0, 0] 特征类别 uniqueVals=[0, 1] (1)类别值为0的时候: 子标签=['flippers'] 分出的子集 splitDataSet(dataSet, bestFeat, value) = [[1, 'no'], [1, 'no']] myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
myTree[bestFeatLabel][0] =’no’ myTree[bestFeatLabel] {0: 'no'} 也就是myTree {'no surfacing': {0: 'no'}} (2)类别值为1的时候: 子标签=['flippers'] 分出的子集 splitDataSet(dataSet, bestFeat, value) = [[1, 'yes'], [1, 'yes'], [0, 'no']] myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
myTree[bestFeatLabel][1] ={'flippers': {0: 'no', 1: 'yes'}} myTree[bestFeatLabel] {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}} 也就是myTree: {'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}} |
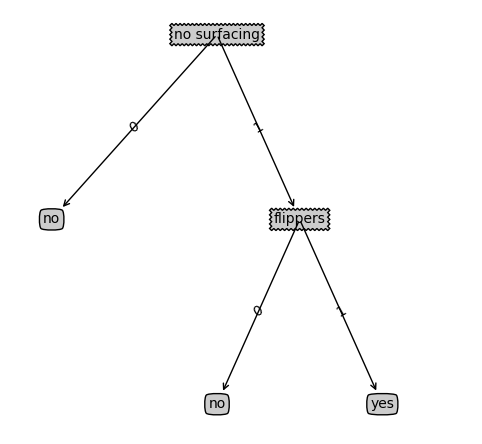
例子中的决策树可视化图:
六、使用决策树做分类
def classify(inputTree, featLabels, testVec):
firstStr = inputTree.keys()[0]
secondDict = inputTree[firstStr]
featIndex = featLabels.index(firstStr)
for key in secondDict.keys():
if testVec[featIndex] == key:
if type(secondDict[key]).__name__=='dict':
classLabel = classify(secondDict[key], featLabels, testVec)
else: classLabel = secondDict[key]
return classLabel
输出结果:
>>> myTree
{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}
>>> labels
['no surfacing', 'flippers']
>>> trees.classify(myTree,labels,[1,0])
'no'
>>> trees.classify(myTree,labels,[1,1])
'yes'
七、 决策树的存储
构造决策树是很耗时的任务,然而用创建好的决策树解决分类问题,则可以很快的完成,可以通过使用pickle模块存储决策树。
def storeTree(inputTree, filename):
import pickle
fw = open(filename,'w')
pickle.dump(inputTree,fw)
fw.close() def grabTree(filename):
import pickle
fr = open(filename)
return pickle.load(fr)
参考资料:
[1] 《机器学习实战》
[2] 《机器学习实战》笔记——决策树(ID3)https://www.cnblogs.com/DianeSoHungry/p/7059104.html
机器学习之决策树(ID3)算法的更多相关文章
- 机器学习之决策树(ID3)算法与Python实现
机器学习之决策树(ID3)算法与Python实现 机器学习中,决策树是一个预测模型:他代表的是对象属性与对象值之间的一种映射关系.树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每 ...
- [机器学习实战] 决策树ID3算法
1. 决策树特点: 1)优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据. 2)缺点:可能会产生过度匹配问题. 3)适用数据类型:数值型和标称型. 2. 一般流程: ...
- 机器学习实战 -- 决策树(ID3)
机器学习实战 -- 决策树(ID3) ID3是什么我也不知道,不急,知道他是干什么的就行 ID3是最经典最基础的一种决策树算法,他会将每一个特征都设为决策节点,有时候,一个数据集中,某些特征属 ...
- 02-21 决策树ID3算法
目录 决策树ID3算法 一.决策树ID3算法学习目标 二.决策树引入 三.决策树ID3算法详解 3.1 if-else和决策树 3.2 信息增益 四.决策树ID3算法流程 4.1 输入 4.2 输出 ...
- 数据挖掘之决策树ID3算法(C#实现)
决策树是一种非常经典的分类器,它的作用原理有点类似于我们玩的猜谜游戏.比如猜一个动物: 问:这个动物是陆生动物吗? 答:是的. 问:这个动物有鳃吗? 答:没有. 这样的两个问题顺序就有些颠倒,因为一般 ...
- 决策树ID3算法[分类算法]
ID3分类算法的编码实现 <?php /* *决策树ID3算法(分类算法的实现) */ /* *求信息增益Grain(S1,S2) */ //-------------------------- ...
- 决策树---ID3算法(介绍及Python实现)
决策树---ID3算法 决策树: 以天气数据库的训练数据为例. Outlook Temperature Humidity Windy PlayGolf? sunny 85 85 FALSE no ...
- 机器学习决策树ID3算法,手把手教你用Python实现
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第21篇文章,我们一起来看一个新的模型--决策树. 决策树的定义 决策树是我本人非常喜欢的机器学习模型,非常直观容易理解 ...
- Python四步实现决策树ID3算法,参考机器学习实战
一.编写计算历史数据的经验熵函数 from math import log def calcShannonEnt(dataSet): numEntries = len(dataSet) labelCo ...
- 决策树ID3算法
决策树 (Decision Tree)是在已知各种情况发生概率的基础上,通过构成 决策树 来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法 ...
随机推荐
- java ssm 后台框架平台 项目源码 websocket 即时通讯 IM quartz springmvc
官网 http://www.fhadmin.org/D 集成安全权限框架shiro Shiro 是一个用 Java 语言实现的框架,通过一个简单易用的 API 提供身份验证和授权,更安全,更可靠E ...
- sort_area_retained_size之tom解释
sort_area_retained_size 摘录一段asktom中tom的解释,对sort内存分配的方式进行了描述: it will allocate up to sort_area_retain ...
- ios开发UI篇—UISlider
概述 UISlider用于从连续范围的值中选择单个值的控件. 当您移动滑块的大拇指时,会将其更新后的值传递给附加的任何动作.滑块的外观是可配置的; 您可以对曲目和大拇指进行着色,并提供出现在滑块末端的 ...
- 仿手机QQ消息小红点动画2
前言 上一篇把动画的实现步骤大致理清,需要确认小尾巴的绘制区域,关键就是确定4个顶点的位置.大家可以根据需要,选择不同的计算方式. 今天,要实现: 文字的添加 尾巴拉长用弧形代替直线 下面是现在的效果 ...
- ubuntu服务器安装jupyter notebook, 并能够实现本地远程连接
1.terminal 敲击 pip3 install jupyter 2.terminal 敲击 jupyter notebook --generate-config 3.terminal 敲击 py ...
- Innodb和Mysiam引擎的区别
一:区别 Mysiam: 1.是非事务安全型. 2.是表级锁. 3.如果执行大量的select,Mysiam是更好的选择. 4.select count(*)from table.Mysiam只简单的 ...
- 偏前端--之小白学习本地存储与cookie
百度了很多都是讲的理论,什么小于4kb啊之类的,小白看了一脸懵逼复制到html中为什么没效果!!哈哈.我来写一个方便小白学习. 贴图带文字描述,让小白也运行起来,然后自己再去理解... 1. cook ...
- Js错误: obj.parents is not a function
代码: (1) <div class="ViewMore" id="viewmore${i}" onclick="CLICK(thi ...
- pomelo vscode 调试配置
步骤 config/server.js 配置 .vscode/launch.json 配置 详细 1. 在server的配置中添加 args 参数,此参数为node开启此服务器时命令参数 " ...
- python 3下对stm32串口数据做解析
1.最近有个想做一个传感器数据实时显示的上位机,常规的数据打印太频繁了,无法直观的看出数据的变化. python下的上位机实现起来简单一点,网上找了一些python界面Tkinter相关资料和pyth ...