CDH5.16.1集群新增节点
如果是全新安装集群的话,可以参考《Ubuntu 16.04上搭建CDH5.16.1集群》
下面是集群新增节点步骤:
1.已经存在一个集群,有两个节点
192.168.100.19 hadoop-master
192.168.100.20 hadoop-slave1
新增节点ip为192.168.100.21
2.新增节点所有的操作都在root下进行,所以首先需要设置ssh可以使用root登录(如果已经是root登录则跳过)
①设置root的登录密码
sudo passwd root
②切换到root用户
sudo su root
③设置登录账户可以使用root
vi /etc/ssh/sshd_config
#PermitRootLogin prohibit-password #屏蔽这一行
PermitRootLogin yes #增加这一行
④更新软件列表并检查是否联网状态
apt-get update
3.新增节点关闭防火墙
ufw disable
4.设置新增节点hostname和hosts
①设置hostname:
vi /etc/hostname
设置为hadoop-slave2
②修改hosts
vi /etc/hosts
127.0.0.1 localhost
#127.0.1.1 test1 #屏蔽这一行 #新增下面三行
192.168.100.19 hadoop-master
192.168.100.20 hadoop-slave1
192.168.100.21 hadoop-slave2
③使用ping命令,查看以上设置是否正确
ping hadoop-master
ping hadoop-slave1
ping hadoop-slave2
④重启后用root登录
5.让三台服务器之间互相可以使用root无需输入密码进行ssh登录。
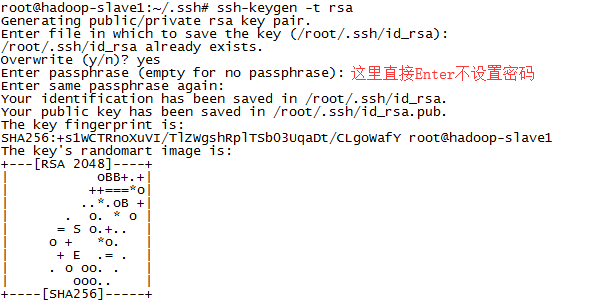
①新增节点生成公钥(不要设置密码)
ssh-keygen -t rsa
截图如下:
②将本机的公钥复制到另外两台服务器上。(过程需要输入目标服务器的root登录密码)
ssh-copy-id -i /root/.ssh/id_rsa.pub hadoop-master #在新增节点上执行
ssh-copy-id -i /root/.ssh/id_rsa.pub hadoop-slave1 #在新增节点上执行
ssh-copy-id -i /root/.ssh/id_rsa.pub hadoop-slave2 #在master和slave1上执行
③测试是否成功
ssh hadoop-master #无密码远程登录hadoop-master,使用exit退出
ssh hadoop-slave1 #无密码远程登录hadoop-slave1,使用exit退出
ssh hadoop-slave2 #无密码远程登录hadoop-slave2,使用exit退出
④如果出现下面的报错
ssh:connect to host hadoop-slave1 port 22: Connection refused
ssh: connect to host hadoop-slave1 port 22: Connection timed out
检查root的密码是否正确,可以使用ssh localhost检查一下是否可以登录到本机,如果不行则证明root密码有问题,转到上面第2个步骤重新设置root密码。
检查/etc/hosts文件中ip和hostname是否正确
检查防火墙是否关闭
6.安装JAVA运行环境
①正常显示版本号则跳过下面步骤
java -version
②如果显示如下,则表示还没有安装JAVA

③具体JDK的安装可以参考
7.安装JAVA的MySQL软件包
apt-get install libmysql-java
8.新增节点中下载CDH相关文件(由于版本的更新,版本号会不断递增),并进行设置
①在浏览器中输入 http://archive.cloudera.com/cm5/cm/5/ 查看到ubuntu对应最新版本

②在浏览器中输入 http://archive.cloudera.com/cdh5/parcels/latest 查看到ubuntu对应最新版本

③将上面的四个文件都下载下来
wget -c http://archive.cloudera.com/cm5/cm/5/cloudera-manager-xenial-cm5.16.1_amd64.tar.gz
wget -c http://archive.cloudera.com/cdh5/parcels/latest/CDH-5.16.1-1.cdh5.16.1.p0.3-xenial.parcel
wget -c http://archive.cloudera.com/cdh5/parcels/latest/CDH-5.16.1-1.cdh5.16.1.p0.3-xenial.parcel.sha1
wget -c http://archive.cloudera.com/cdh5/parcels/latest/manifest.json
④将CDH-5.16.1-1.cdh5.16.1.p0.3-xenial.parcel.sha1文件重命名为CDH-5.16.1-1.cdh5.16.1.p0.3-xenial.parcel.sha
mv CDH-5.16.1-1.cdh5.16.1.p0.3-xenial.parcel.sha1 CDH-5.16.1-1.cdh5.16.1.p0.3-xenial.parcel.sha
⑤在/opt中建立对应的文件夹结构(cm-5.16.1为当前版本号)
| --/opt
|--/cloudera
|--/parcels
|--/parcel-repo
|--/cm-5.16.1
cd /opt
mkdir cm-5.16.1
mkdir cloudera
cd cloudera
mkdir parcels
mkdir parcel-repo
⑥将CDH-5.16.1-1.cdh5.16.1.p0.3-xenial.parcel、CDH-5.16.1-1.cdh5.16.1.p0.3-xenial.parcel.sha和manifest.json三个文件拷贝到/opt/cloudera/parcel-repo中
cp CDH-5.16.1-1.cdh5.16.1.p0.3-xenial.parcel CDH-5.16.1-1.cdh5.16.1.p0.3-xenial.parcel.sha manifest.json /opt/cloudera/parcel-repo
⑦解压cloudera-manager-xenial-cm5.16.1_amd64.tar.gz到/opt中
tar -zxf cloudera-manager-xenial-cm5.16.1_amd64.tar.gz -C /opt
⑧修改配置文件
vi /opt/cm-5.16.1/etc/cloudera-scm-agent/config.ini
# Hostname of the CM server.
server_host=hadoop-master #修改为主机名
9.新增用户
useradd --system --home=/opt/cm-5.16./run/cloudera-scm-server --shell=/bin/false --comment "Cloudera SCM User" cloudera-scm
10.安装python
apt-get install python2.
11.设置vm.swappiness=10
vi /etc/sysctl.conf
vm.swappiness=10 #在文件最后增加一行
cat /proc/sys/vm/swappiness #查看当前值,设置后需要重启才生效
12.安装必要的库
apt-cache search libmysql
apt-get install libmysql++-dev
apt-get install python-libxslt1
13.java环境快捷方式
mkdir /usr/java
ln -s /usr/local/java /usr/java/default
14.reboot重启
15.启动进程(报错信息的处理可查看:《Ubuntu 16.04上搭建CDH5.16.1集群》)
cd /opt/cm-5.16.1/etc/init.d
./cloudera-scm-server start
./cloudera-scm-agent start
16.耐心稍等一会,进入master的页面http://192.168.100.19:7180/cmf/login进行登录
17.找到所有主机列表(如果没看到新的节点,要么是等的时间不够久,要么是上面的步骤出错了)(可以看到192.168.100.21下的Roles为空)

18.点击Add New Host to Cluster,出现向导
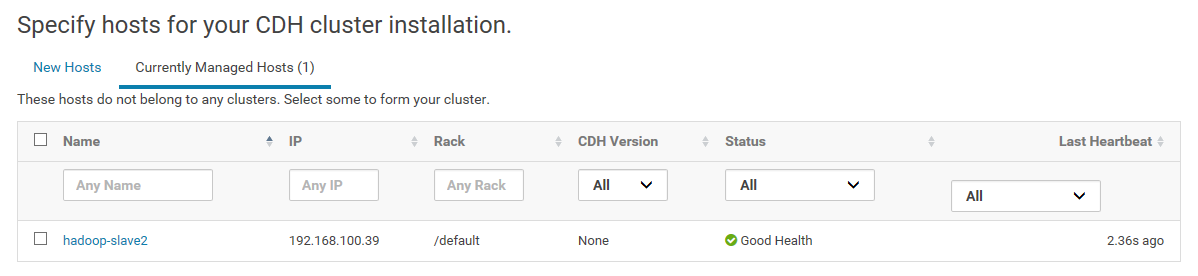
19.这里显示还没有加入到集群的新节点
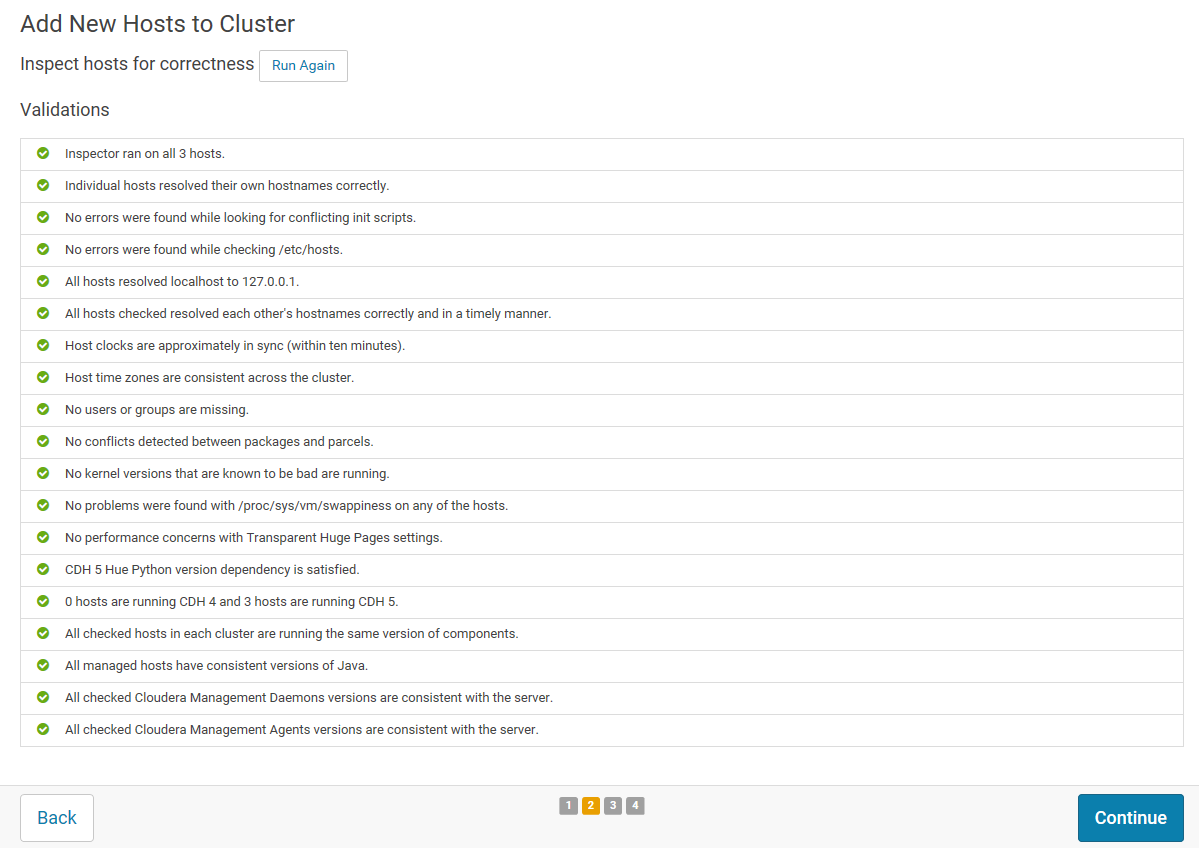
20.耐心等待安装

21.返回安装信息
22.这里可以为新增节点角色,这里我们不设置,在后面再新增DataNode的角色
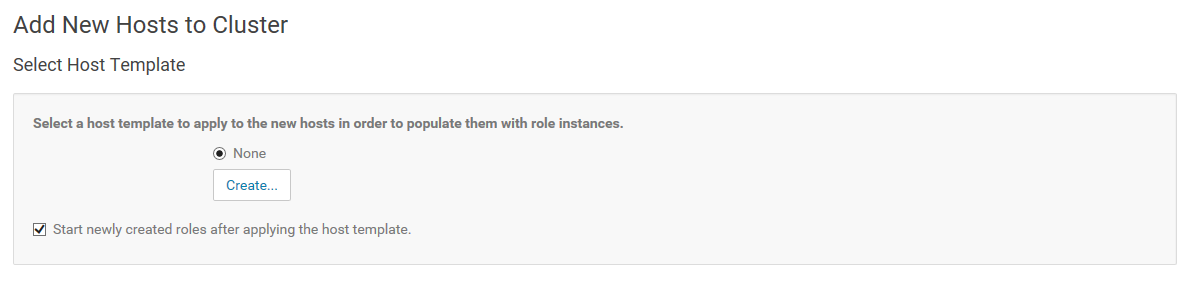
23.完成Finished

24.下面步骤为将新增节点加入到DataNode角色中。
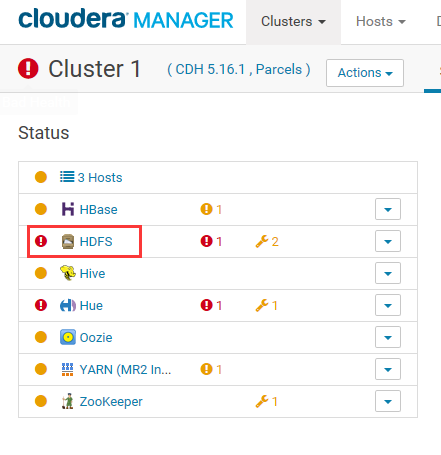
25.点击进入HDFS的DataNode中
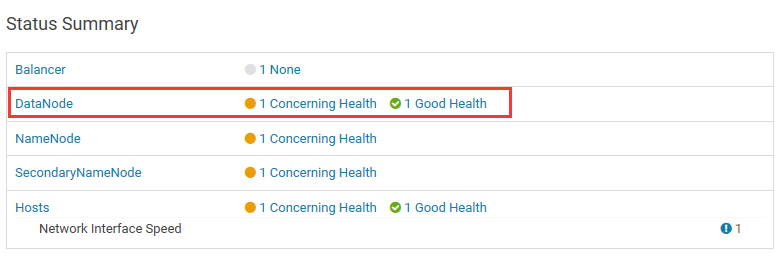
26.点击Add Role Instances

27.在所有主机上使用DataNode角色

28.全部步骤完成。
以上。
CDH5.16.1集群新增节点的更多相关文章
- redis 集群新增节点,slots槽分配,删除节点, [ERR] Calling MIGRATE ERR Syntax error, try CLIENT (LIST | KILL | GET...
redis reshard 重新分槽(slots) https://github.com/antirez/redis/issues/5029 redis 官方已确认该bug redis 集群重新(re ...
- Elastic search集群新增节点(同一个集群,同一台物理机,基于ES 7.4)
一开始,在电脑上同一个集群新增节点(node)怎么试也不成功,官网guide又语焉不详?集群健康值yellow(表示主分片全部可用,部分复制分片不可用) 最后,在stackoverflow上找到了答案 ...
- Ubuntu 16.04上搭建CDH5.16.1集群
本文参考自:<Ubuntu16.04上搭建CDH5.14集群> 1.准备三台(CDH默认配置为三台)安装Ubuntu 16.04.4 LTS系统的服务器,假设ip地址分布为 192.168 ...
- Spark集群新增节点方法
Spark集群处理能力不足需要扩容,如何在现有spark集群中新增新节点?本文以一个实例介绍如何给Spark集群新增一个节点. 1. 集群环境 现有Spark集群包括3台机器,用户名都是cdahdp, ...
- CDH5.16.1集群企业真正离线部署
一.准备工作 1.离线部署主要分为三块: MySQL离线部署 CM离线部署 Parcel文件离线源部署 2.规划 节点 MySQL部署组件 Parcel文件离线源 CM服务进程 大数据组件 hadoo ...
- k8s集群新增节点
节点为centos7.4 一.node节点基本环境配置 1.配置主机名 2.配置hosts文件(master和node相互解析) 3.时间同步 ntpdate pool.ntp.org date ec ...
- yum安装CDH5.5 Hadoop集群
1.环境说明 系统环境: 系统环境:centos6.7 Hadoop版本:CDH5.5 JDK运行版本:1.7.0_67 集群各节点组件分配: 2.准备工作 安装 Hadoop 集群前先做好下面的准备 ...
- Tomcat集群---Cluster节点配置(转)
<!-- Cluster(集群,族) 节点,如果你要配置tomcat集群,则需要使用此节点. className 表示tomcat集群时,之间相互传递信息使用那个类来实现信息之间的传递. cha ...
- Kafka 1.0.0集群增加节点
原有环境 主机名 IP 地址 安装路径 系统 sht-sgmhadoopdn-01 172.16.101.58 /opt/kafka_2.12-1.0.0 /opt/kafka(软连接) CentOS ...
随机推荐
- python发送邮件心得体会
利用本地smtp server发送 windows下尝试装了两个smtp server大概配置了下,发现没法生效,也没时间仔细研究了.装上foxmail发现以前可以本地发送的选项已经无法找到. 不带附 ...
- 深入理解Java虚拟机7-chap10-11-斗者4星
一.编译期优化 1.JIT编译器在运行期的优化过程对程序运行很重要,而编译期优化过程对于程序编码关系更密切 2.Javac编译器编译过程 解析与填充符号表过程:词法语法分析.填充符号表 插入式注解处理 ...
- CocosCreator的ToggleGroup组件使用
用了CocosCreator也有一段时间,对ToggleGroup始终没有仔细的学习过,只停留在用过的水平.所以因为认识有限,所以以为ToggleGroup对自定义支持得没那么好,这两天因为项目,再学 ...
- 关于微信跳转,这里有你想知道的一切weixin://dl/business/?ticket=td9cd0bf056c561fe9f56e33c61df61bf
纠结了了很久,还是放出来部分接口,相信能够看到这篇文章的人也基本都是需求比较强烈的. 京东: https://wq.jd.com/mjgj/link/GetOpenLink?rurl=http%3a% ...
- 解决页面使用ifrmae后,在session失效后登录页面在子页面中显示(子窗体出现父窗体)
在登录页面中添加js判断当前页面是否是父页面,诺不是则父页面跳转至登录页面. <script type="text/javascript"> //解决登录后多个父窗体问 ...
- react组件实现扩展知识
react-redux redux-thunk 实现异步action, ajax,定时器 redux-gen 利用生成器,实现middleware react-router-redux react-r ...
- python,day3,函数基础-3
本节内容 1. 函数基本语法及特性 2. 参数与局部变量 3. 返回值 嵌套函数 4.递归 5.匿名函数 6.函数式编程介绍 7.高阶函数 8.内置函数 1.函数基本语法及特性 函数是什么? 函数一词 ...
- 软件综合实践Axure介绍
首先就是下载安装Axure这款软件了,在百度上搜索“”Axure rp下载“”即可,下载完成后,打开exe安装,根据步骤一步步点击下一步即可完成安装. 运行该软件时会出现类似于填写激活码的东西,这时依 ...
- SQL大数据查询优化
常写的SQL可能主要以实现查询出结果为主,但如果数据量一大,就会突出SQL查询语句优化的性能独特之处.一般的数据库设计都会建索引查询,这样较全盘扫描查询的确快了不少.下面总结下SQL查询语句的几个优化 ...
- JS动态添加行列
<%@ Page Language="C#" AutoEventWireup="true" CodeFile="Add-Delete Row.a ...