CUDA[2] Hello,World
Section 0:Hello,World
这次我们亲自尝试一下如何用粗(CU)大(DA)写程序
CUDA最新版本是7.5,然而即使是最新版本也不兼容VS2015 。。。推荐使用VS2012
进入VS2012,新建工程,选择NVIDIA--CUDA Runtime
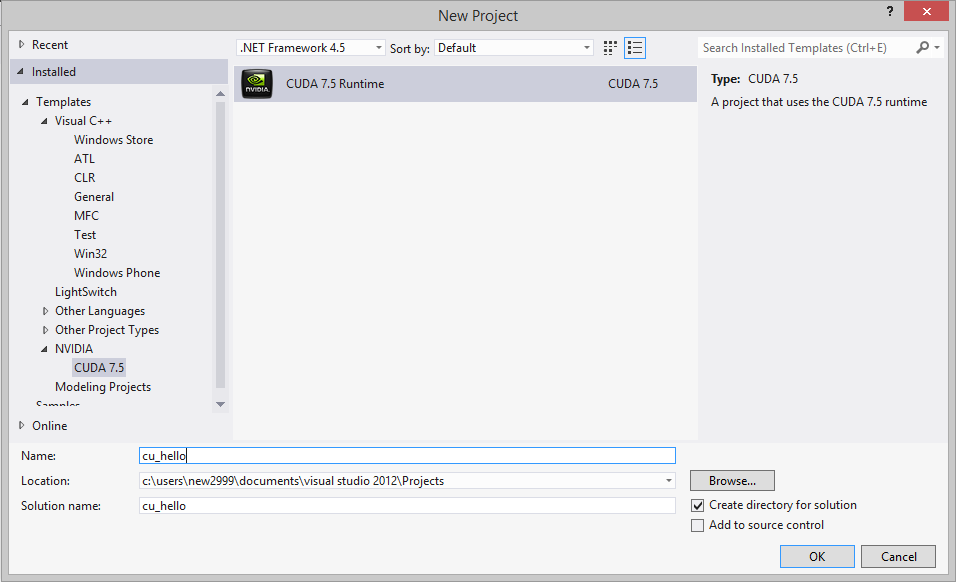
我们来写一个简单的向量加法程序:[Reference]
#include <stdio.h> __global__ void saxpy(int n, float a, float *x, float *y)
//__global__关键字,表示是将要在GPU里并行运行的核函数
{
int i = blockIdx.x*blockDim.x + threadIdx.x;
if (i < n)
y[i] = a*x[i] + y[i];
} int main()
{
int N = ;
float *x, *y, *d_x, *d_y; //都是指针,指向数组所在的内存/显存空间
x = (float*)malloc(N*sizeof(float)); //在内存中为x,y分配空间
y = (float*)malloc(N*sizeof(float)); cudaMalloc(&d_x, N*sizeof(float)); //在显存中为d_x,d_y分配空间
cudaMalloc(&d_y, N*sizeof(float)); for (int i = ; i < N; i++)
{
x[i] = (float)i;
y[i] = 2.0f;
} cudaMemcpy(d_x, x, N*sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_y, y, N*sizeof(float), cudaMemcpyHostToDevice);
//将内存中x,y指向的数组空间拷贝到显存中d_x,d_y指向的数组空间 saxpy<<<,N>>>(N, 10.0f, d_x, d_y);
//1个block,每个block里N个thread cudaMemcpy(y, d_y, N*sizeof(float), cudaMemcpyDeviceToHost);
//将显存中计算好的d_y指向的数组空间拷贝到内存中y指向的数组空间 for (int i = ; i < N; i++)
printf("%d %.3f\n",i,y[i]); getchar();
}
运行后就会出结果啦~
Section 1:一个好一点的代码风格
虽然刚才的程序已经能运行了,但是讲道理的话把所有的代码都写到cu文件里是很屎的风格。。。
下面再来写一个向量加法的程序:[Ref]
/* kernel.cu */
//cuda系函数必须放在cu文件里
#include "cuda_runtime.h"
#include "device_launch_parameters.h" #include <stdio.h> __global__ void addKernel(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
} //cpp中不能直接调用核函数,所以在cu文件中还得写一个接口,负责分配内存等
void addWithCuda(int *c, const int *a, const int *b, unsigned int size)
{
int *dev_a = ;
int *dev_b = ;
int *dev_c = ; // Choose which GPU to run on, change this on a multi-GPU system.
cudaSetDevice(); // Allocate GPU buffers for three vectors (two input, one output) .
cudaMalloc((void**)&dev_c, size * sizeof(int));
cudaMalloc((void**)&dev_a, size * sizeof(int));
cudaMalloc((void**)&dev_b, size * sizeof(int)); // Copy input vectors from host memory to GPU buffers.
cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice); // Launch a kernel on the GPU with one thread for each element.
addKernel<<<, size>>>(dev_c, dev_a, dev_b); // Copy output vector from GPU buffer to host memory.
cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost); cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
cudaDeviceReset();
} //-------------------------------------------------------------------------------
/* Source.cpp */
#include"cstdio"
#include"cstring" extern void addWithCuda(int *c, const int *a, const int *b, unsigned int size);
//.cpp是由C编译器来编译的。C编译器里不允许#include一个cu文件(不资词)
//若要引用cu里的函数,在main.cpp里外部extern声明一下,让VS转为NVCC编译器处理。 int main()
{
const int arraySize = ;
const int a[arraySize] = { , , , , };
const int b[arraySize] = { , , , , };
int c[arraySize] = { }; addWithCuda(c, a, b, arraySize); printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n",
c[], c[], c[], c[], c[]); getchar(); return ;
}
补充:对于一些计算量较大(GPU计算时间较长)的程序,有可能运行很短时间之后就崩溃掉,并出现“显卡驱动已停止”的提示。
这是因为驱动程序默认认为GPU只负责图形计算任务,如果有任务长时间占用GPU就会自动terminate掉。
解决方法如下:[Ref]
进入注册表->HKEY_LOCAL_MACHINE->System->CurrentControlSet->Control->GraphicsDrivers
新建DWORD键TdrLevel,键值为0。保存重启即可。
Section 2:还是要学习一个
下面系统介绍一下粗大里的关键字和规则:
[Ref]
__global__:kernel函数。在device(GPU)里运行。可以在host(CPU处的主程序)调用
__device__:只允许在device运行,在device调用
__constant__:constant memory,表示常量
__shared__:shared memory,block内共享的变量
CUDA[2] Hello,World的更多相关文章
- CUDA[1] Introductory
Section 0 :Induction of CUDA CUDA是啥?CUDA®: A General-Purpose Parallel Computing Platform and Program ...
- Couldn't open CUDA library cublas64_80.dll etc. tensorflow-gpu on windows
I c:\tf_jenkins\home\workspace\release-win\device\gpu\os\windows\tensorflow\stream_executor\dso_load ...
- ubuntu 16.04 + N驱动安装 +CUDA+Qt5 + opencv
Nvidia driver installation(after download XX.run installation file) 1. ctrl+Alt+F1 //go to virtual ...
- 手把手教你搭建深度学习平台——避坑安装theano+CUDA
python有多混乱我就不多说了.这个混论不仅是指整个python市场混乱,更混乱的还有python的各种附加依赖包.为了一劳永逸解决python的各种依赖包对深度学习造成的影响,本文中采用pytho ...
- [CUDA] CUDA to DL
又是一枚祖国的骚年,阅览做做笔记:http://www.cnblogs.com/neopenx/p/4643705.html 这里只是一些基础知识.帮助理解DL tool的实现. “这也是深度学习带来 ...
- 基于Ubuntu14.04系统的nvidia tesla K40驱动和cuda 7.5安装笔记
基于Ubuntu14.04系统的nvidia tesla K40驱动和cuda 7.5安装笔记 飞翔的蜘蛛人 注1:本人新手,文章中不准确的地方,欢迎批评指正 注2:知识储备应达到Linux入门级水平 ...
- CUDA程序设计(一)
为什么需要GPU 几年前我启动并主导了一个项目,当时还在谷歌,这个项目叫谷歌大脑.该项目利用谷歌的计算基础设施来构建神经网络. 规模大概比之前的神经网络扩大了一百倍,我们的方法是用约一千台电脑.这确实 ...
- 使用 CUDA范例精解通用GPU编程 配套程序的方法
用vs新建一个cuda的项目,然后将系统自动生成的那个.cu里头的内容,除了头文件引用外,全部替代成先有代码的内容. 然后程序就能跑了. 因为新建的是cuda的项目,所以所有的头文件和库的引用系统都会 ...
- CUDA代码移植
如果CUDA的代码移植,一个是要 include文件夹对不对,这个是.h文件能否找到的关键,另一个就是lib,这个是.lib文件能否找到的关键.具体检查地方,见下头. include: lib:
随机推荐
- eclipse启动tomcat无法访问
eclipse启动tomcat无法访问 症状: tomcat在eclipse里面能正常启动,而在浏览器中访问http://localhost:8080/不能访问,且报404错误.同时其他项目页面也不能 ...
- ES6之数组扩展方法【一】(相当好用)
form 转化为真正的数组 先说一下使用场景,在Js中,我们要经常操作DOM,比如获取全部页面的input标签,并且找到类型为button的元素,然后给这个按钮注册一个点击事件,我们可能会这样操作: ...
- 在View and Data API中更改指定元素的颜色
大家在使用View and Data API开发过程中,经常会用到的就是改变某些元素的颜色已区别显示.比如根据某些属性做不同颜色的专题显示,或者用不同颜色表示施工进度,或者只是简单的以颜色变化来提醒用 ...
- (十四)Maven聚合与继承
1.Maven聚合 我们在平时的开发中,项目往往会被划分为好几个模块,比如common公共模块.system系统模块.log日志模块.reports统计模块.monitor监控模块等等.这时我们肯定会 ...
- javascript 设置input框只读属性 获取disabled后的值并传给后台
input只读属性 有两种方式可以实现input的只读效果:disabled 和 readonly. 自然两种出来的效果都是只能读取不能编辑,可是两者有很大不同. Disabled说明该input ...
- vim使用笔记
vim的配置文件.vimrc 一般有2个位置 1是在/目录下 2是在-目录下 如果在-目录下有了配置文件 那么将不去读取/目录下面的配置文件 如果你不知道现在使用的vim 使用的是哪个目录下面的配置 ...
- 11g新特性:Health Monitor Checks
一.什么是Health Monitor ChecksHealth Monitor Checks能够发现文件损坏,物理.逻辑块损坏,undo.redo损坏,数据字典损坏等等.Health Monitor ...
- mysql
这是 <MySQL 必知必会> 的读书总结.也是自己整理的常用操作的参考手册. 使用 MySQL 连接到 MySQL shell>mysql -u root -p Enter pas ...
- freeswitch 使用mysql替换默认的sqlite
转自 80000hz.com freeswitch 使用mysql替换默认的sqlite No Reply , Posted in 默认分类 on January 14, 2014 目标使用mysql ...
- 学习《Hardware-Efficient Bilateral Filtering for Stereo Matching》一文笔记。
个人收藏了很多香港大学.香港科技大学以及香港中文大学里专门搞图像研究一些博士的个人网站,一般会不定期的浏览他们的作品,最近在看杨庆雄的网点时,发现他又写了一篇双边滤波的文章,并且配有源代码,于是下载下 ...