mapreduce项目中加入combiner
combiner相当于是一个本地的reduce,它的存在是为了减少网络的负担,在本地先进行一次计算再叫计算结果提交给reduce进行二次处理。
现在的流程为:
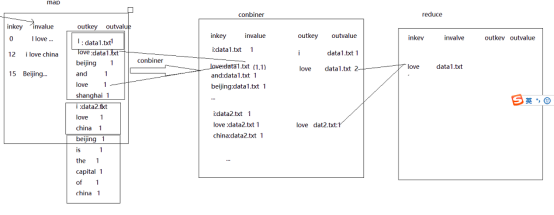
对于combiner我们有这些理解:


Mapper代码展示:
package com.nenu.mprd.test; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit; public class MyMap extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
//获取到单词
String line=value.toString();
String[] words=line.split(" ");
//获取到文件名
FileSplit filesplit = (FileSplit)context.getInputSplit();
String fileName = filesplit.getPath().getName().trim();//.substring(0,5). String outkey=null;
for (String word : words) {
//字母+:+文件名
outkey=word.trim()+":"+fileName;
System.out.println("map:"+outkey); context.write(new Text(outkey), new Text("1"));
}
}
}
Combiner代码展示:
package com.nenu.mprd.test; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class MyCombiner extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values,Context context) throws IOException, InterruptedException {
Text n = null;//输出key
int count=0;
Text m=null;//输出value
for(Text v :values){ //对同一个map输出的k,v对进行按k进行一次汇总。不同map的k,v汇总必须要用reduce方法
String[] words=key.toString().split(":");
n=new Text(words[0].trim());//字母--key
System.out.println("MyCombiner KEY:"+n); count+=Integer.parseInt(v.toString());
m=new Text("("+words[1].trim()+" "+count+")"); }
System.out.println("MyCombiner value:"+m);
context.write(n, m);
} }
Reduce代码展示:
package com.nenu.mprd.test; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class MyReduce extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values,
Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
// TODO Auto-generated method stub
System.out.println("reduce: key"+key);
String out="";
for (Text Text : values) {
//sum+=intWritable.get();
out+=Text.toString()+" ";
}
System.out.println("reduce value:"+out);
context.write(key, new Text(out));
}
}
Job代码展示:
package com.nenu.mprd.test; import java.net.URI; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class MyJob extends Configured implements Tool{ public static void main(String[] args) throws Exception {
MyJob myJob=new MyJob();
ToolRunner.run(myJob, null);
}
@Override
public int run(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf=new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.64.141:9000"); //添加自动删除hadoop下的文件
//如果导成架包则需要改变一些参数作为手动输入
FileSystem filesystem =FileSystem.get(new URI("hdfs://192.168.64.141:9000"), conf, "root");
Path deletePath=new Path("/hadoop/wordcount/city/out");
if(filesystem.exists(deletePath)){
filesystem.delete(deletePath,true);//str: b:
} Job job=Job.getInstance(conf);
job.setJarByClass(MyJob.class);
job.setMapperClass(MyMap.class); //设置combiner 如果combiner和reduce一样则可以不用设置
job.setCombinerClass(MyCombiner.class); job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path("/hadoop/wordcount/city"));
FileOutputFormat.setOutputPath(job, new Path("/hadoop/wordcount/city/out"));
job.waitForCompletion(true);
return 0;
} }
mapreduce项目中加入combiner的更多相关文章
- MapReduce项目中的一个JVM错误问题分析和解决
最近一周都在查项目的各种问题,由于对原有的一个MapReduce分析数据的项目进行重构,减少了运行时的使用资源,但是重构完成后,在Reduce端总是不定时地抛出JVM的相关错误,非常随机,没有发现有什 ...
- 项目中Map端内存占用的分析
最近在项目中开展重构活动,对Map端内存尽量要省一些,当前的系统中Map端内存最高占用大概3G左右(设置成2G时会导致Java Heap OOM).虽然个人觉得占用不算多,但是显然这样的结果想要试 ...
- 在eclipse中用gradle搭建MapReduce项目
我用的系统是ubuntu14.04新建一个Java Project. 这里用的是gradle打包,gradle默认找src/main/java下的类编译.src目录已经有了,手动在src下创建main ...
- ubuntu14.04 Hadoop单机开发环境搭建MapReduce项目
Hadoop官网:http://hadoop.apache.org/ 目前最新的版本是Hadoop 3.0.0-alpha1前提:java 1.6 版本以上 首先从官网下载压缩包(hadoop-3.0 ...
- MongoDB在实际项目中的使用
MongoDB简介 MongoDB是近些年来流行起来的NoSql的代表,和传统数据库最大的区别是支持文档型数据库. 当然,现在的一些数据库通过自定义复合类型,可变长数组等手段也可以模拟文档型数据库. ...
- SparkSQL项目中的应用
Spark是一个通用的大规模数据快速处理引擎.可以简单理解为Spark就是一个大数据分布式处理框架.基于内存计算的Spark的计算速度要比Hadoop的MapReduce快上100倍以上,基于磁盘的计 ...
- mapreduce任务中Shuffle和排序的过程
mapreduce任务中Shuffle和排序的过程 流程分析: Map端: 1.每个输入分片会让一个map任务来处理,默认情况下,以HDFS的一个块的大小(默认为64M)为一个分片,当然我们也可以设置 ...
- hadoop-初学者写map-reduce程序中容易出现的问题 3
1.写hadoop的map-reduce程序之前所必须知道的基础知识: 1)hadoop map-reduce的自带的数据类型: Hadoop提供了如下内容的数据类型,这些数据类型都实现了Writab ...
- 通过Maven管理多个MapReduce项目
1. 配置Maven环境 首先检查Windows是否配置了maven,进入cmd命令行,输入mvn -version命令,如果出现下图所示的 情形则表示满意配置maven. 从浏览器进入maven官网 ...
随机推荐
- 基于 Markdown 编写接口文档
最近公司开发项目需要前后端分离,这样话就设计到后端接口设计.复杂功能需要提供各种各样的接口供前端调用,因此编写API文档非常有必要了 网上查了很多资料,发现基于Markdown编写文档是一种比较流行而 ...
- codeforces-1131 (div2)
A.把右上角的凹缺口补上变成凸的就成了规则矩形 #include <map> #include <set> #include <ctime> #include &l ...
- font-family
Font-family: Helvetica, Tahoma, Arial, “Microsoft YaHei”, “微软雅黑”, SimSun, “宋体”, STXihei, “华文细黑”, Hei ...
- RPC-dubbo基本使用
22.本地存根 消费者通过创建实现一个服务接口的实例,可以在执行远程调用前拿到远程调用的代理实例,进而可以在远程调用前.后添加一些操作,在出现异常后进行一些容错处理. 这个使用场景,可以调用前作数 ...
- 多项式求导系列——OO Unit1分析和总结
一.摘要 本文是BUAA OO课程Unit1在课程讲授.三次作业完成.自测和互测时发现的问题,以及倾听别人的思路分享所引起个人的一些思考的总结性博客.本文第二部分介绍三次作业的设计思路,主要以类图的形 ...
- 迅为IMX6Q PLUS开发板烧写Android6.0系统方法
平台:迅为IMX6Q PLUS开发板工具:MfgTool2 工具 镜像文件在光盘目录“03 镜像_android 6.0.1 文件系统”下.其中商业级核心板为 2G内存镜像,工业级核心板为 1G 内存 ...
- Q查询条件
e. Q查询 ``` def search(self, query_list): query = self.request.GET.get('query', '') # 获取query的值 # Q(Q ...
- 解决:在微信中访问app下载链接提示“已停止访问该网页”
前言 现如今微信对第三方推广链接的审核是越来越严格了,域名在微信中分享转发经常会被拦截,一旦被拦截用户就只能复制链接手动打开浏览器粘贴才能访问,要不然就是换个域名再推,周而复始.无论是哪一种情况都会面 ...
- httpClient closeableHttpClient
https://www.cnblogs.com/lyy-2016/p/6388663.html
- maven配置及IDEA配置maven环境
一. maven的下载及配置 1. maven下载地址 可以在网址:https://maven.apache.org/download.cgi下载最新版本的maven 2. maven文件解压缩 解压 ...