豆瓣电影top250爬取并保存在MongoDB里
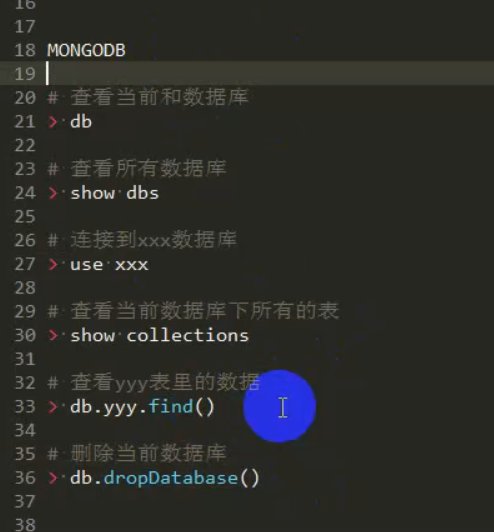
首先回顾一下MongoDB的基本操作:
数据库,集合,文档
db,show dbs,use 数据库名,drop 数据库
db.集合名.insert({})
db.集合名.update({条件},{$set:{}},{multi:true})
db.集合名.remove({条件})
db集合名.find({条件},{投影}).limit().skip().sort().count().distinct() 数据库 增加 修改 删除 查询
mysql insert update delete select
redis set set del get
mongodb insert update remove find,aggregate
string
hash
list
set
zset
增加
mysql:insert into 表名(列) values(值)
mongo:db.集合名.insert({})
修改:
mysql:update 表名 set 列=值 where 条件
mongo:db.集合名.update({条件},{值$set},{是否修改多条})
删除:
mysql:delete from 表名 where ....
mongo:db.集合名.remove({条件},{是否删除多条})
查询:
db.stu.find({},{})
比较运算符,逻辑运算符,$where
limit(),skip(),sort(),count(),distinct()
首先使用xpath提取出要爬取的信息:我们这个项目需要爬取的信息有:标题,信息,评分,简介
第一页链接:https://movie.douban.com/top250
第二页链接:https://movie.douban.com/top250?start=25&filter=
第三页链接:https://movie.douban.com/top250?start=50&filter=
规律:https://movie.douban.com/top250?start=\d+&filter=
标题://a/span[@class="title"][1]
信息://div[@class="bd"]/p[1]/text()
评分://div[@class="star"]/span[2]/text()
简介://span[@class="inq"]/text()
然后使用sscrapy startproject douban 创建项目
sscrapy genspider dopuban movie.douban.com
然后依次编写下面的文件:
items.py
doubanmovie.py
settings.py
pipelines.py
豆瓣电影top250爬取并保存在MongoDB里的更多相关文章
- 豆瓣电影信息爬取(json)
豆瓣电影信息爬取(json) # a = "hello world" # 字符串数据类型# b = {"name":"python"} # ...
- 5分钟掌握智联招聘网站爬取并保存到MongoDB数据库
前言 本次主题分两篇文章来介绍: 一.数据采集 二.数据分析 第一篇先来介绍数据采集,即用python爬取网站数据. 1 运行环境和python库 先说下运行环境: python3.5 windows ...
- Scrapy教程--豆瓣电影图片爬取
一.先上效果 二.安装Scrapy和使用 官方网址:https://scrapy.org/. 安装命令:pip install Scrapy 安装完成,使用默认模板新建一个项目,命令:scrapy s ...
- python2.7爬取豆瓣电影top250并写入到TXT,Excel,MySQL数据库
python2.7爬取豆瓣电影top250并分别写入到TXT,Excel,MySQL数据库 1.任务 爬取豆瓣电影top250 以txt文件保存 以Excel文档保存 将数据录入数据库 2.分析 电影 ...
- python2.7抓取豆瓣电影top250
利用python2.7抓取豆瓣电影top250 1.任务说明 抓取top100电影名称 依次打印输出 2.网页解析 要进行网络爬虫,利用工具(如浏览器)查看网页HTML文件的相关内容是很有必要,我使用 ...
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- 利用python2.7正则表达式进行豆瓣电影Top250的网络数据采集及MySQL数据库操作
转载请注明出处 利用python2.7正则表达式进行豆瓣电影Top250的网络数据采集 1.任务 采集豆瓣电影名称.链接.评分.导演.演员.年份.国家.评论人数.简评等信息 将以上数据存入MySQL数 ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- 【转】爬取豆瓣电影top250提取电影分类进行数据分析
一.爬取网页,获取需要内容 我们今天要爬取的是豆瓣电影top250页面如下所示: 我们需要的是里面的电影分类,通过查看源代码观察可以分析出我们需要的东西.直接进入主题吧! 知道我们需要的内容在哪里了, ...
随机推荐
- 算法 - Catalan数 (卡特兰)
http://blog.csdn.net/linhuanmars/article/details/24761459 https://zh.wikipedia.org/wiki/%E5%8D%A1%E5 ...
- 基于Vue实现图片在指定区域内移动
当图片比要显示的区域大时,需要将多余的部分隐藏掉,我们可以通过绝对定位来实现,并通过动态修改图片的left值和top值从而实现图片的移动.具体实现效果如下图,如果我们移动的是div 实现思路相仿. 此 ...
- 【代码笔记】iOS-DropDownDemo-下拉按钮效果
一,效果图. 二,工程图. 三,代码. RootViewController.h #import <UIKit/UIKit.h> @interface RootViewController ...
- javascript之for循环的几种写法
背景 javascript中的for循环选择多种多样,可你知道其中的差别在哪里吗?什么时候又该用哪种循环才是最佳策略?以上这些是本文想讨论的,欢迎交流. 说明 1.20年前的for循环 //20年前的 ...
- H5新增属性classList
H5新增属性classList h5中新增了一个classList,原生js可以通过它来判断获取dom节点有无某个class. classList是html元素对象的成员,它的使用非常简单,比如 co ...
- TensorFlow分布式部署【单机多卡】
让TensorFlow飞一会儿 面对大型的深度神经网络训练工程,训练的时间非常重要.训练的时间长短依赖于计算处理器也就是GPU,然而单个GPU的计算能力有限,利用多个GPU进行分布式部署,同时完成一个 ...
- 这几个Xocode插件用过一段时间还比较稳定好用,Xcode6兼容,推荐给大家:
这几个Xocode插件用过一段时间还比较稳定好用,Xcode6兼容,推荐给大家: AdjustFontSize: 快捷调整Xcode字体,https://github.com/zats/AdjustF ...
- CVE-2015-3864漏洞利用分析(exploit_from_google)
title: CVE-2015-3864漏洞利用分析(exploit_from_google) author: hac425 tags: CVE-2015-3864 文件格式漏洞 categories ...
- python读取shp
sf = shapefile.Reader("res2_4m.shp") records = sf.records() print sf.fields for record in ...
- selenium&phantomjs实战--漫话爬取
为什么直接保存当前网页,而不是找到所有漫话链接,再有针对性的保存图片? 因为防盗链的原因,当直接保存漫话链接图片时,只能保存到防盗链的图片. #!/usr/bin/env python # _*_ c ...