YFCC 100M数据集分析笔记
——从YFCC 100M数据集中筛选出Geo信息位于中国的数据集
1.YFCC 100M简介
YFCC 100M数据库是2014年来基于雅虎Flickr的影像数据库。该库由1亿条产生于2004年至2014年间的多条媒体数据组成,其中包含了9920万的照片数据以及80万条视频数据。
YFCC 100M数据集并不包含照片或视频数据,而是一个文本数据文档,文档中每一行都是一条照片或视频的元数据。每一行包含23个项目,他们分别代表:
[0] Photo/video identifier 照片/视频标识符
[1] User NSID 用户NSID
[2] User nickname 用户昵称
[3] Date taken 拍摄日期
[4] Date uploaded 上传日期
[5] Capture device 使用设备
[6] Title 标题
[7] Description 描述
[8] User tags (comma-separated) 用户标签(逗号分隔)
[9] Machine tags (comma-separated) 机器标签(逗号分隔)
[10] Longitude 经度
[11] Latitude 纬度
[12] Accuracy 准确性
[13] Photo/video page URL 照片/视频页面URL
[14] Photo/video download URL 照片/视频下载网址
[15] License name 许可证名称
[16] License URL 许可网址
[17] Photo/video server identifier 照片/视频服务器标识符
[18] Photo/video farm identifier 照片/视频农场标识符
[19] Photo/video secret 照片/视频秘密
[20] Photo/video secret original 照片/视频秘密原件
[21] Extension of the original photo 扩展原始照片
[22] Photos/video marker (0 = photo, 1 = video) 照片/视频标记(0 =照片,1 =视频)
其中,我使用到的有
[0] Photo/video identifier 照片/视频标识符
[10] Longitude 经度
[11] Latitude 纬度
代码见 https://github.com/libaoquan95/flickrAnalyse
2.从数据集中挑选出具有Geo信息的数据集
Geo信息,就是地理位置信息,现在很多摄影设备都带有GPS模块,可以记录照片拍摄时的地理位置信息,即经度和纬度。但需要注意的是,并不是所有的元数据都带有Geo信息,所以要筛出不含Geo信息的元数据。
''' readDataset.py '''
# 从原始数据集中提取带有geo标签的数据
# @param fliename原始文件名
# @return none
def getGeoDataFromDataset(fliename):
# 打开数据集
inFile = open(fliename)
outFile = open(fliename + '-geo', 'w')
i = 0
count = 0
# 读取原数据集 infile
for line in inFile:
# 分割元数据
meteData = line.strip().split('\t')
# 此照片或视频带有geo信息
if(meteData[10] != '' and meteData[11] != ''):
outFile.write(line)
count = count + 1
if(i % 1000000 == 0):
print ('处理了 %d 行, geo有 %d 行' % (i, count))
i = i + 1
print ('共 %d 行, geo共 %d 行' % (i, count))
inFile.close()
outFile.close()
3.筛选出Geo信息位于中国的数据集
可以根据经纬度获取坐标点的实际地址,再通过分析实际地址后判断此坐标点是否位于中国。
可以使用geopy包来进行经纬度到实际地址的转换。但geopy需联网使用,在处理大量数据时非常耗时。所以可以先根据中国的经纬度范围大致筛选,然后使用geopy进行精确筛选。
中国的经纬度范围是:
最东端 东经135度2分30秒 黑龙江和乌苏里江交汇处
最西端 东经73度40分 帕米尔高原乌兹别里山口(乌恰县)
最南端 北纬3度52分 南沙群岛曾母暗沙
最北端 北纬53度33分 漠河以北黑龙江主航道(漠河县)
''' readDataset.py '''
# 从带有geo标签的数据集中提取出geo大概在中国范围内的数据
# 最东端 东经135度2分30秒 黑龙江和乌苏里江交汇处
# 最西端 东经73度40分 帕米尔高原乌兹别里山口(乌恰县)
# 最南端 北纬3度52分 南沙群岛曾母暗沙
# 最北端 北纬53度33分 漠河以北黑龙江主航道(漠河)
# 转换后
# 经: 73.66667 - 135.04167
# 纬: 3.86667 - 53.55
# @param fliename原始文件名
# @return none
def getAbortChinaFromGeoData(fliename):
# 打开数据集
inFile = open(fliename)
outFile = open(fliename + '-abortchina', 'w')
i = 0
count = 0
# 读取原数据集 infile
for line in inFile:
# 分割元数据
meteData = line.strip().split('\t')
# 此geo信息位于中国
if(float(meteData[10]) >= 73.66667 and float(meteData[10]) <= 135.04167 and \
float(meteData[11]) >= 3.86667 and float(meteData[11]) <= 53.55):
newLine = '\t'.join(meteData)
outFile.write(newLine + '\n')
count = count + 1
if(i % 1000000 == 0):
print ('处理了 %d 行, 中国geo有 %d 行' % (i, count))
i = i + 1
print ('共 %d 行, 中国geo共 %d 行' % (i, count))
inFile.close()
outFile.close()
之后使用geopy来获取精确地址。
geopy使用可以参考http://www.cnblogs.com/giserliu/p/4982187.html
基于python的地理编码库geopy 是用于地理编码的常用工具,使用它可获取多种地图服务的坐标。目前Python2和Python3下都支持。Python开发者可以使用geopy很容易的获取全球的某个街道地址,城市,国家和地块的地理坐标,它是通过第三方的地理编码器和数据源来解析的。
''' readDataset.py '''
# 从带有geo标签的数据集中提取出geo实际在中国范围内的数据
# 通过Geopy,有经纬度获取实际地址
# geopy的函数参数是纬度在前,经度在后
# @param fliename原始文件名,lonIndex经度下标,latIndex维度下标,操作次数n
# @return none
def getChinaFromDatasetByGeopy(filename, lonIndex, latIndex, n=10):
# 打开数据集
inFile = open(filename)
datas = []
isFinsih = []
# 读取原数据集 infile
for line in inFile:
# 分割元数据
meteData = line.strip().split('\t')
datas.append(meteData)
isFinsih.append(0)
inFile.close()
inFile = open(filename, 'w', encoding='utf-8')
outFile = open(filename + '-china-address', 'a', encoding='utf-8')
outFile2 = open(filename + '-china', 'a', encoding='utf-8')
# 逐条获取数据的实际地址
# 若地址位于中国,将信息写入新文件
# 将未处理的数据重新写入到原文件
geolocator = Nominatim()
i = 0
count = 0
error_count = 0
none_count = 0
while i<n and i<len(datas):
try:
# 根据经纬坐标获取实际地址
location = geolocator.reverse("" + datas[i][latIndex] +"," + datas[i][lonIndex])
if (location.address != None):
addressArr = location.address.split(',')
country = addressArr[len(addressArr)-1].strip()
# 标记已处理
isFinsih[i] = 1
# 地址位于中国
if(country in ["中国","臺灣"]):
outFile.write(datas[i][0] + '\t' + country + '\t' + location.address + '\n')
outFile2.write('\t'.join(datas[i]) + '\n')
count += 1
else:
none_count += 1
isFinsih[i] = 2
except GeocoderTimedOut as e:
#print('tiom out: ' + datas[i][0])
error_count += 1
i += 1
sys.stdout.write('处理 %d 行, 中国 %d 行,请求超时 %d 行,none %d 行\r' % (i, count, error_count, none_count))
sys.stdout.flush()
#if(i % 10 == 0):
# print ('处理 %d 行, 中国 %d 行,请求超时 %d 行,none %d 行' % (i, count, error_count, none_count))
print('')
# 重新写入未处理数据
length = len(isFinsih)
for i in range(length):
if(isFinsih[i] == 0):
inFile.write('\t'.join(datas[i]) + '\n')
for i in range(length):
if(isFinsih[i] == 2):
inFile.write('\t'.join(datas[i]) + '\n')
inFile.close()
outFile.close()
outFile2.close()
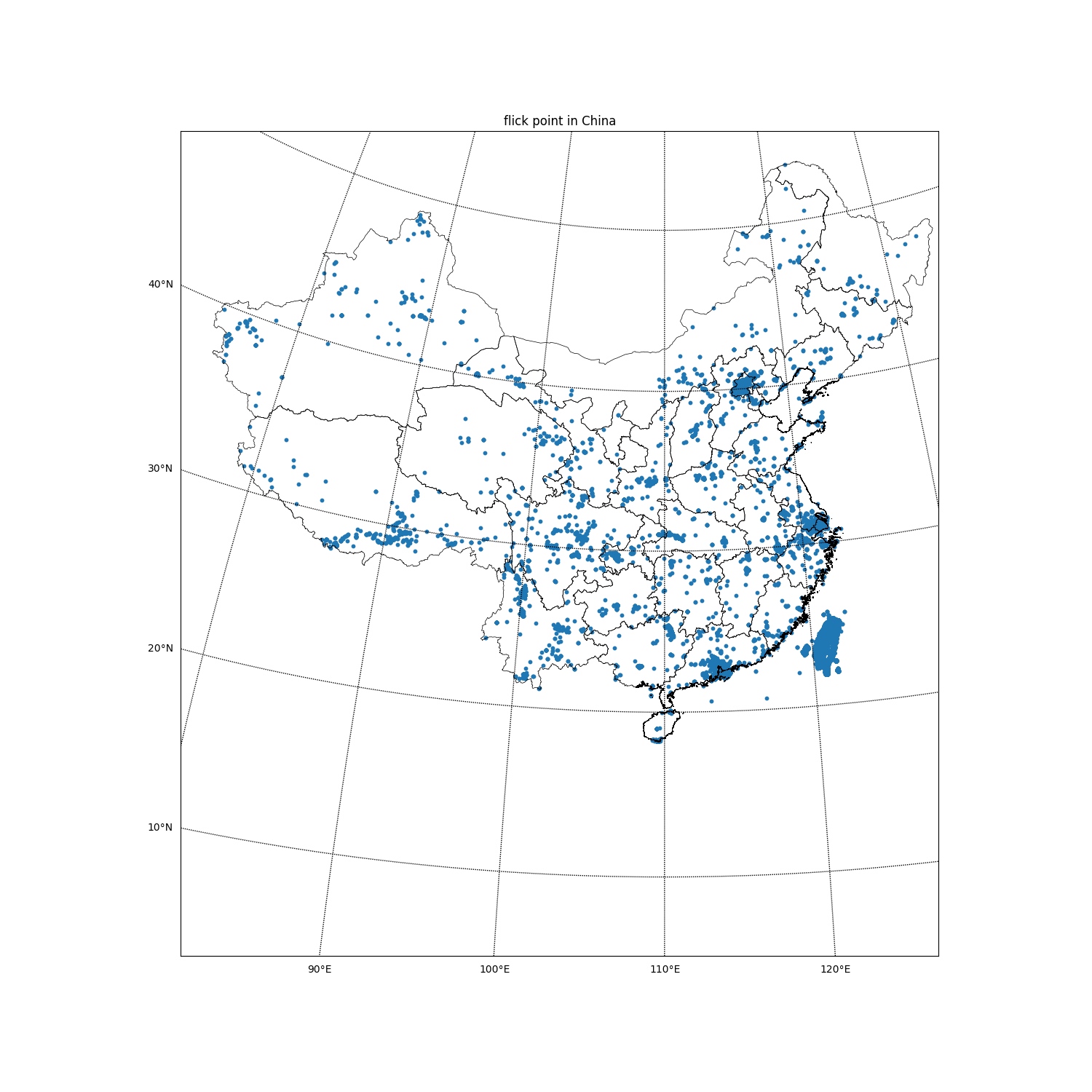
4.数据可视化
使用geopy真的非常耗时,我大概使用了5天的空余时间才提取了一个压缩文件的数据(yfcc100m_dataset-0),共60015条。使用散点图将数据可视化:
''' drawMap.py '''
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from mpl_toolkits.basemap import Basemap
from matplotlib.animation import FuncAnimation
from matplotlib.patches import Polygon
# 画出中国地图,并将数据集中的经纬点在图中标记
# @param filename:数据集,lonIndex:经度下标,latIndex:维度下标
def drawMap(filename, lonIndex, latIndex):
inFile = open(filename)
datas = []
lon = []
lat = []
# 读取原数据集 infile
for line in inFile:
# 分割元数据
meteData = line.strip().split('\t')
datas.append(meteData)
lon.append(float(meteData[lonIndex]))
lat.append(float(meteData[latIndex]))
fig = plt.gcf()
map = Basemap(projection='stere',
lat_0=35,
lon_0=110,
llcrnrlon=82.33,
llcrnrlat=3.01,
urcrnrlon=138.16,
urcrnrlat=53.123,
resolution='l',
area_thresh=10000,
rsphere=6371200.)
# CHN_adm1的数据是中国各省区域
shp_info = map.readshapefile("CHN_adm_shp/CHN_adm1", 'states', drawbounds=True)
#map.drawmapboundary() # 绘制边界
#map.fillcontinents() # 填充大陆,发现填充之后无法显示散点图,应该是被覆盖了
#map.drawstates() # 绘制州
#map.drawcoastlines() # 绘制海岸线
#map.drawcountries() # 绘制国家
#map.drawcounties() # 绘制县
fig.set_size_inches(30, 30)
parallels = np.arange(0., 90, 10.)
map.drawparallels(parallels, labels=[1, 0, 0, 0], fontsize=10) # 绘制纬线
meridians = np.arange(80., 140., 10.)
map.drawmeridians(meridians, labels=[0, 0, 0, 1], fontsize=10) # 绘制经线
x, y = map(lon, lat)
# map.scatter(x, y, edgecolors='r', facecolors='r', marker='*', s=320)
map.scatter(x, y, s=10)
plt.title("flick point in China")
fig.savefig('yfcc100m_dataset-0/China.png', dpi=100)
#plt.show()
inFile.close()
drawMap('yfcc100m_dataset-0/flick-0-geo-abortchina-china', 10, 11)
YFCC 100M数据集分析笔记的更多相关文章
- Spark 实践——基于 Spark MLlib 和 YFCC 100M 数据集的景点推荐系统
1.前言 上接 YFCC 100M数据集分析笔记 和 使用百度地图api可视化聚类结果, 在对 YFCC 100M 聚类出的景点信息的基础上,使用 Spark MLlib 提供的 ALS 算法构建推荐 ...
- Python数据挖掘之决策树DTC数据分析及鸢尾数据集分析
Python数据挖掘之决策树DTC数据分析及鸢尾数据集分析 今天主要讲述的内容是关于决策树的知识,主要包括以下内容:1.分类及决策树算法介绍2.鸢尾花卉数据集介绍3.决策树实现鸢尾数据集分析.希望这篇 ...
- 3.View绘制分析笔记之onLayout
上一篇文章我们了解了View的onMeasure,那么今天我们继续来学习Android View绘制三部曲的第二步,onLayout,布局. ViewRootImpl#performLayout pr ...
- 4.View绘制分析笔记之onDraw
上一篇文章我们了解了View的onLayout,那么今天我们来学习Android View绘制三部曲的最后一步,onDraw,绘制. ViewRootImpl#performDraw private ...
- 2.View绘制分析笔记之onMeasure
今天主要学习记录一下Android View绘制三部曲的第一步,onMeasure,测量. 起源 在Activity中,所有的View都是DecorView的子View,然后DecorView又是被V ...
- 1.Android 视图及View绘制分析笔记之setContentView
自从1983年第一台图形用户界面的个人电脑问世以来,几乎所有的PC操作系统都支持可视化操作,Android也不例外.对于所有Android Developer来说,我们接触最多的控件就是View.通常 ...
- zeromq源码分析笔记之线程间收发命令(2)
在zeromq源码分析笔记之架构说到了zmq的整体架构,可以看到线程间通信包括两类,一类是用于收发命令,告知对象该调用什么方法去做什么事情,命令的结构由command_t结构体确定:另一类是socke ...
- R语言重要数据集分析研究——需要整理分析阐明理念
1.R语言重要数据集分析研究需要整理分析阐明理念? 上一节讲了R语言作图,本节来讲讲当你拿到一个数据集的时候如何下手分析,数据分析的第一步,探索性数据分析. 统计量,即统计学里面关注的数据集的几个指标 ...
- glusterfs 4.0.1 api 分析笔记1
一般来说,我们写个客户端程序大概的样子是这样的: /* glfs_example.c */ // gcc -o glfs_example glfs_example.c -L /usr/lib64/ - ...
随机推荐
- n进制转十进制
#include<cstdio> #include<iostream> using namespace std; ; int main(){ ,len=; char ch[ma ...
- 接口与协议学习笔记-USB协议_USB2.0_USB3.0不同版本(三)
USB(Universal Serial Bus)全称通用串口总线,USB为解决即插即用需求而诞生,支持热插拔.USB协议版本有USB1.0.USB1.1.USB2.0.USB3.1等,USB2.0目 ...
- Windows10放开Administrator权限
手机上大家都喜欢使ROOT权限,root是超线用户的意思,但是Win10最高权限是Administrator管理员权限,但是系统默认是没有开启这个权限的需要系统安装好以后再次去开启. 方法/步骤 在桌 ...
- 10.14 (上午)开课一个月零十天 (PHP环境搭建)
一.修改APACHE的监听端口 2 1.在界面中选apache,弹出隐藏菜单选项,打开配置文件httpd.conf; 2.找到Listen 80 和 ServerName localhost:80; ...
- 1444: [Jsoi2009]有趣的游戏
1444: [Jsoi2009]有趣的游戏 链接 分析: 如果一个点回到0号点,那么会使0号点的概率增加,而0号点的概率本来是1,不能增加,所以这题用期望做. 设$x_i$表示经过i的期望次数,然后初 ...
- 4516: [Sdoi2016]生成魔咒
4516: [Sdoi2016]生成魔咒 链接 题意: 求本质不同的子串. 分析: 后缀数组或者SAM都可以. 考虑SAM中每个点的可以表示的子串是一个区间min(S)~max(S),把每个点的这个区 ...
- JavaScript 数组——filter()、map()、some()、every()、forEach()、lastIndexOf()、indexOf()
filter(): 语法: var filteredArray = array.filter(callback[, thisObject]); 参数说明: callback: 要对每个数组元素执行 ...
- python数据分析处理库-Pandas
1.读取数据 import pandas food_info = pandas.read_csv("food_info.csv") print(type(food_info)) # ...
- JMeter转制LoadRunner HTTP协议脚本的小技巧
对于Http协议的请求,除了手工编写脚本外,JMeter还提供了录制浏览器操作的功能,甚是方便.那如果手头有一堆HTTP协议的LoadRunner脚本,能不能比较快速的转制成JMeter脚本呢?其实也 ...
- SSH结合EasyUI系统(一)———简单介绍
鉴于前文<不仅仅是吐槽>,决定将自己学过的和在学的东西整理一下放进园子:做一个好园友! 接下来将会持续更新的是近一段时间在学的java web中比较流行的框架SSH(Struts+Spri ...