mysql group replication观点及实践
一:个人看法
Mysql Group Replication 随着5.7发布3年了。作为技术爱好者。mgr 是继 oracle database rac 之后。
又一个“真正” 的群集,怎么做到“真正” ? 怎么做到解决复制的延迟,怎么做到强数据一致性?基于全局的GTID就能解决? 围绕这些问题进行了一些mgr 的实践,
为未来的数据库高可用设计多条选择。
mysql5.7手册17章可以看到其原理,网络上也很多同志写了关于其技术原理,这里自己对比rac理解下:
作为shared nothing (mgr)架构,其数据一致性实现较 shared everything(RAC) 架构要难,
MGR通过一致性(Paxos)协议,保证数据在复制组内的存活节点里是一致的,复制组内的各成员都可以进行读写,
其实现机制是,当某个实例发起事务提交时,会向组内发出广播,由组内成员决议事务是否可以正常提交,
MGR在遇到事务冲突时(多节点同时修改同一行数据),会自动识别冲突,并根据提交时间让先提交的事务成功执行,后提交的事务回滚,其原理示意图如下:
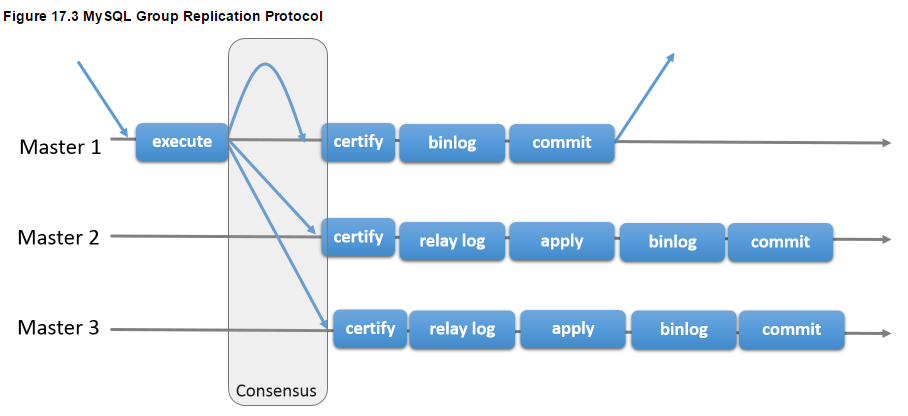
对于 sharad nothing 架构,必须要了解分布式协议PAXOS,分布式状态机 理论,而在这块我翻阅了很多资料,发现其实并不是很成熟的。从上图可以看出来MGR 的冲突检测机制
类似于 rac 的gird 群集组件 也具备通告广播的群集服务。但本质架构上有所不同。一切依赖于 复制组的软件实现。如果这里出了问题,那么整个群集一致性难以得到保证。
二:搭建过程
这个过程比较粗糙,网络上有不少写的比较细的可以参考
port=3306
basedir=/home/mysql
datadir=/home/mysql/data3
socket = /home/mysql/data3/mysql3.sock
log_error=/home/mysql/data3/mysql3.error
slow_query_log=on
slow_query_log_file=/home/mysql/data3/slow3.log
long_query_time=3
character_set_server=utf8
lower_case_table_names=1
max_connections=1000
max_connect_errors=1000
explicit_defaults_for_timestamp=1
explicit_defaults_for_timestamp
log-slow-admin-statements=1
log-queries-not-using-indexes=1
expire-logs-days = 15
open_files_limit=65535
innodb_log_file_size = 100m
innodb_log_files_in_group = 3
innodb_file_per_table = 1
innodb_buffer_pool_size=10240M
#mgr
server-id=333
gtid_mode = on
enforce_gtid_consistency = 1
log_slave_updates = 1
master_info_repository=table
relay_log_info_repository=table
binlog_checksum=none
log-bin=/home/mysql/data3/mysql-bin
binlog_format=row
###指示服务器对于每个事务,它必须收集写集并使用XXHASH64散列算法将其编码为散列。
transaction_write_set_extraction=XXHASH64
###创建的组名称
loose-group_replication_group_name="335e89d8-2f49-4425-9add-1eeb8134f8fc"
###指示插件在服务器启动时不自动启动操作,add my 美团点评,是开启的
###配置成员后,您可以设置 group_replication_start_on_boot 为on,以便在服务器引导时自动启动Group Replication。
loose-group_replication_start_on_boot=on
#loose-group_replication_member_weight = 40
loose-group_replication_local_address="172.31.50.160:20003"
#设置组成员的主机名和端口,新成员使用它们建立与组的连接。这些成员称为种子成员。建立连接后,将列出组成员身份信息
#可以查询 performance_schema.replication_group_members
loose-group_replication_group_seeds="172.31.50.160:20001,172.31.50.160:20002,172.31.50.160:20003,172.31.50.160:20004"
# singe or multi mode 这里2个参数不开启则为单主模式
#loose-group_replication_single_primary_mode = off
#loose-group_replication_enforce_update_everywhere_checks = on
#当成员在发生故障转移时被选为主要成员的可能性的权重百分比,和server_uuid 配合进行选举
#如果主要成员离开单主要组,则执行选举,并从组中的其余服务器中选择新的主要成员。
#这次选举是通过查看新视图,并根据值来订购潜在的新原选 group_replication_member_weight。
#假设该组正在运行所有运行相同MySQL版本的成员,则具有最高值的成员将 group_replication_member_weight 被选为新的主要成员。
#如果多个服务器具有相同 group_replication_member_weight的服务器,
#则根据服务器的优先级对服务器进行优先级排序 server_uuid按字典顺序和选择第一个。
#选择新主节点后,它将自动设置为读写,其他副节点仍为辅助节点,因此为只读节点。
group_replication_member_weight=80
#少数组成员由于网络中断且无法连接到多数成员的成员在离开组之前等待多长时间参数
#少数组将永远等待网络重新连接。在使用停止组复制之前,将阻止少数组处理的任何事务
loose-group_replication_unreachable_majority_timeout=5
#压缩发生在组通信引擎级别,之前数据被交给组通信线程,所以它发生在mysql用户会话线程的上下文中。事务有效网络负载可以在被发送到组之前被压缩,
#并且在被接收时被解压缩。压缩是有条件的,并且取决于配置的阈值。默认情况下启用压缩,此外,它并不要求组中的所有服务器节点都启用压缩机制,
#在接收到消息时,成员检查消息信封以验证它是否被压缩,如果需要,则成员解压缩该事务,然后将其传递到上层
#默认情况下启用压缩,阈值为1000000字节(1MB)。压缩阈值以字节为单位。
#美团这里设置为128k。
group_replication_compression_theeshold=131072
#配置组接受的最大事务大小(以字节为单位)。
#回滚大于此大小的事务。使用此选项可避免导致组失败的大型事务。
#大型事务可能导致组的问题,无论是在内存分配还是网络带宽消耗方面,
#这可能导致故障检测器触发,因为给定成员在忙于处理大事务时无法访问。
#设置为0时,组接受的事务大小没有限制,并且可能存在导致组失败的大型事务的风险。根据组中所需的工作负载大小调整此变量的值。
group_replication_transaction_size_limit=20971520
create user repl@'%' identified by 'repl123';
grant replication slave on *.* to repl@'%';
change master to
master_user='repl',
master_password='repl123'
for channel 'group_replication_recovery'; select * from mysql.slave_relay_log_info\G
install plugin group_replication soname 'group_replication.so';
set @@global.group_replication_bootstrap_group=on; ---->是否是Group Replication的引导节点,初次搭建集群的时候需要有一个节点设置为ON来启动Group Replication
start group_replication;
set @@global.group_replication_bootstrap_group=off;
select * from performance_schema.replication_group_members;
create database test;
use test;
create table t1(id int);
create table t2(id int)engine=myisam;
create table t3(id int primary key)engine=myisam; --->不支持
create table t4(id int primary key);
3:其它节点加入组复制
change master to
master_user='repl',
master_password='repl123'
for channel 'group_replication_recovery'; install plugin group_replication soname 'group_replication.so';
set global group_replication_allow_local_disjoint_gtids_join=1;
start group_replication;
注意:
一个节点加入组复制会有本地的事物产生,比如更改密码,加入测试数据等。上述红字可以可以规避上述事务,强制加入,也可以在本地事务开始之前进行
sql_log_bin=0;
start transaction..........
sql_log_bin=1;
4:维护
任意一节点启动,停止组复制。
start group_replication;
stop group_replication;
查看所有在线的组复制节点
select * from performance_schema.replication_group_members;
查看谁是主节点,单主模式下,能查出值,多主模式下无法查出。
select b.member_host the_master,a.variable_value master_uuid
from performance_schema.global_status a
join performance_schema.replication_group_members b
on a.variable_value = b.member_id
where variable_name='group_replication_primary_member';
+------------+--------------------------------------+
| the_master | master_uuid |
+------------+--------------------------------------+
| calldb3 | cc4958ae-a1cc-11e8-9334-00155d322c00 |
+------------+--------------------------------------+
三:vip的实施
mgr 并不提供vip 的概念。在单主模式下,必须启用vip实现才能做到 HA 的作用,这里的策略网络上也很多,我们基于keepalived 进行思考
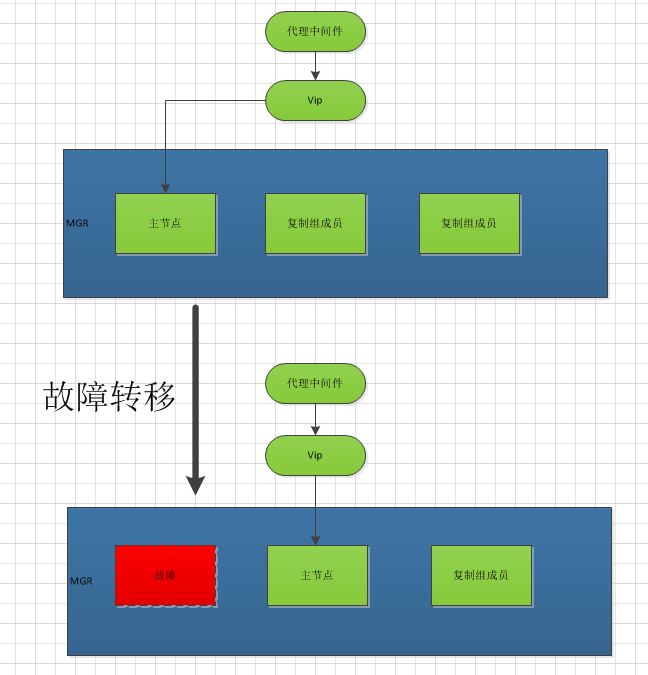
要实现上述策略,考虑故障节点的情况
1:故障节点 mysql 实例崩溃,守护进程也不能拉起改实例,需要VIP 漂移。
2:故障节点系统崩溃,段时间无法进行恢复。需要VIP 漂移。
3:判定谁是主节点,vip就漂移到主节点
基于以上3点。keepalived 除了系统故障vip漂移的功能,还需要mysql 实例崩溃的判定主节点漂移功能
具体实现:
[root@calldb1 ~]# cat /etc/keepalived/keepalived.conf
vrrp_script chk_mysql_port {
script "/etc/keepalived/chk_mysql.sh" ---判断实例存活
interval 2
weight -5
fall 2
rise 1
}
vrrp_script chk_mysql_master {
script "/etc/keepalived/chk_mysql2.sh" ---判断主节点
interval 2
weight 10
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 88
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.0.100
} track_script {
chk_mysql_port
chk_mysql_master
} }
判定脚本如下:
[root@calldb1 ~]# cat /etc/keepalived/chk_mysql.sh
#!/bin/bash
netstat -tunlp |grep mysql
a=`echo $?`
if [ $a -eq 1 ] ;then
service keepalived stop
fi
[root@calldb1 ~]# cat /etc/keepalived/chk_mysql2.sh
#!/bin/bash
host=`/data/mysql/bin/mysql -h127.0.0.1 -uroot -pxxx -e "SELECT * FROM performance_schema.replication_group_members WHERE MEMBER_ID = (SELECT VARIABLE_VALUE FROM performance_schema.global_status WHERE VARIABLE_NAME= 'group_replication_primary_member')" |awk 'NR==2{print}'|awk -F" " '{print $3}'`
host2=`hostname`
if [ $host == $host2 ] ;then
exit 0
else
exit 1
fi
四:采坑的地方:
1:一个节点加入组的时候,因没有种子的概念,那么它就是中心,所以要申明他是中心:
set @@global.group_replication_bootstrap_group=on;
2:如果没有在etc/hosts 文件配置ip地址到主机的解析,那么组复制一直会出现:
--30T21::24.604720+: [Note] Plugin group_replication reported: 'Retrying group recovery connection with another donor. Attempt 6/10'
--30T21::24.605458+: [Note] 'CHANGE MASTER TO FOR CHANNEL 'group_replication_recovery' executed'. Previous state master_host='sanborn1', master_port= , master_log_file='', master_log_pos= , master_bind=''. New state master_host='sanborn1', master_port= , master_log_file='', master_log_pos= , master_bind=''.
--30T21::24.610029+: [Note] Plugin group_replication reported: 'Establishing connection to a group replication recovery donor 75af6fe1-6a92-11e9-8bf8-005056a1d54e at sanborn1 port: 3306.'
--30T21::24.611927+: [Warning] Storing MySQL user name or password information in the master info repository is not secure and is therefore not recommended. Please consider using the USER and PASSWORD connection options for START SLAVE; see the 'START SLAVE Syntax' in the MySQL Manual for more information.
--30T21::24.645794+: [ERROR] Slave I/O for channel 'group_replication_recovery': error connecting to master 'repl@sanborn1:3306' - retry-time: retries: , Error_code:
--30T21::24.645847+: [Note] Slave I/O thread for channel 'group_replication_recovery' killed while connecting to master
--30T21::24.645861+: [Note] Slave I/O thread exiting for channel 'group_replication_recovery', read up to log 'FIRST', position
--30T21::24.646002+: [ERROR] Plugin group_replication reported: 'There was an error when connecting to the donor server. Please check that group_replication_recovery channel credentials and all MEMBER_HOST column values of performance_schema.replication_group_members table are correct and DNS resolvable.'
--30T21::24.646064+: [ERROR] Plugin group_replication reported: 'For details please check performance_schema.replication_connection_status table and error log messages of Slave I/O for channel group_replication_recovery.'
--30T21::24.646271+: [Note] Plugin group_replication reported: 'Retrying group recovery connection with another donor. Attempt 7/10'
直到脱离群集,状态一直是recovering
mysql> select * from performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| group_replication_applier | 75af6fe1-6a92-11e9-8bf8-005056a1d54e | sanborn1 | | ONLINE |
| group_replication_applier | 8e091df0-6b4c-11e9-896b-005056a175f4 | sanborn2 | | RECOVERING |
| group_replication_applier | ae657017-6b4c-11e9--005056a1c149 | sanborn3 | | RECOVERING |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
rows in set (0.01 sec)
mysql group replication观点及实践的更多相关文章
- MySQL group replication介绍
“MySQL group replication” group replication是MySQL官方开发的一个开源插件,是实现MySQL高可用集群的一个工具.第一个GA版本正式发布于MySQL5.7 ...
- Galera将死——MySQL Group Replication正式发布
2016-12-14 来源:InsideMySQL 作者:姜承尧 MySQL Group Replication GA 很多同学表示昨天的从你的全世界路过画风不对,好在今天MySQL界终于有大事情发生 ...
- MySQL Group Replication 技术点
mysql group replication,组复制,提供了多写(multi-master update)的特性,增强了原有的mysql的高可用架构.mysql group replication基 ...
- MySQL Group Replication 动态添加成员节点
前提: MySQL GR 3节点(node1.node2.node3)部署成功,模式定为多主模式,单主模式也是一样的处理. 在线修改已有GR节点配置 分别登陆node1.node2.node3,执行以 ...
- Docker Images for MySQL Group Replication 5.7.14
In this post, I will point you to Docker images for MySQL Group Replication testing. There is a new ...
- Percona XtraDB Cluster vs Galera Cluster vs MySQL Group Replication
Percona XtraDB Cluster vs Galera Cluster vs MySQL Group Replication Overview Galera Cluster 由 Coders ...
- Mysql 5.7 基于组复制(MySQL Group Replication) - 运维小结
之前介绍了Mysq主从同步的异步复制(默认模式).半同步复制.基于GTID复制.基于组提交和并行复制 (解决同步延迟),下面简单说下Mysql基于组复制(MySQL Group Replication ...
- mysql group replication 主节点宕机恢复
一.mysql group replication 生来就要面对两个问题: 一.主节点宕机如何恢复. 二.多数节点离线的情况下.余下节点如何继续承载业务. 在这里我们只讨论第一个问题.也就是说当主结点 ...
- MySQL Group Replication配置
MySQL Group Replication简述 MySQL 组复制实现了基于复制协议的多主更新(单主模式). 复制组由多个 server成员构成,并且组中的每个 server 成员可以独立地执行事 ...
随机推荐
- SPSS学习系列之SPSS Modeler的功能特性(图文详解)
不多说,直接上干货! Win7/8/10里如何下载并安装最新稳定版本官网IBM SPSS Modeler 18.0 X64(简体中文 / 英文版)(破解永久使用)(图文详解) 我这里,是以SPSS ...
- Go语言学习笔记十一: 切片(slice)
Go语言学习笔记十一: 切片(slice) 切片这个概念我是从python语言中学到的,当时感觉这个东西真的比较好用.不像java语言写起来就比较繁琐.不过我觉得未来java语法也会支持的. 定义切片 ...
- CART树
算法概述 CART(Classification And Regression Tree)算法是一种决策树分类方法. 它采用一种二分递归分割的技术,分割方法采用基于最小距离的基尼指数估计函数,将当前的 ...
- centos7-安装mysql5.6.36
本地安装了mysql5.7, 但和springboot整合jpa时会出现 hibernateException, 不知道为什么, 换个mysql5.6版本的mysql, 源码安装, cmake一直过 ...
- C++中模板与泛型编程
目录 定义一个通用模板 模板特化和偏特化 模板实例化与匹配 可变参数模板 泛型编程是指独立与任何类型的方式编写代码.泛型编程和面向对象编程,都依赖与某种形式的多态.面向对象编程的多态性在运行时应用于存 ...
- 关于 centos 7系统,iptables透明网桥实现
首先建立网桥:(使用bridge) 示例 桥接eth0 与 eth1 网口 /sbin/modprobe bridge /usr/sbin/brctl addbr br0 /sbin/ifup ...
- Beta阶段——Scrum 冲刺博客第二天
一.当天站立式会议照片一张 二.每个人的工作 (有work item 的ID),并将其记录在码云项目管理中 昨天已完成的工作 实现对index界面的重新制作,变成了原来的main界面,直接在该界面输入 ...
- asdfasdfasdfasdf
- 基于Ionic的移动框架搭建
- [转] Hadoop管理员的十个最佳实践
前言 接触Hadoop有两年的时间了,期间遇到很多的问题,既有经典的NameNode和JobTracker内存溢出故障,也有HDFS存储小文件问题,既有任务调度问题,也有MapReduce性能问题.遇 ...