Hadoop(1): HDFS基础架构
1. What's HDFS?
Hadoop Distributed File System is a block-structured file system where each file is divided into blocks of a pre-determined size. These blocks are stored across a cluster of one or several machines. Apache Hadoop HDFS Architecture follows a Master/Slave Architecture, where a cluster comprises of a single NameNode (Master node) and all the other nodes are DataNodes (Slave nodes). In the practical world, these DataNodes are spread across various machines.
2. Basic ideas of HDFS
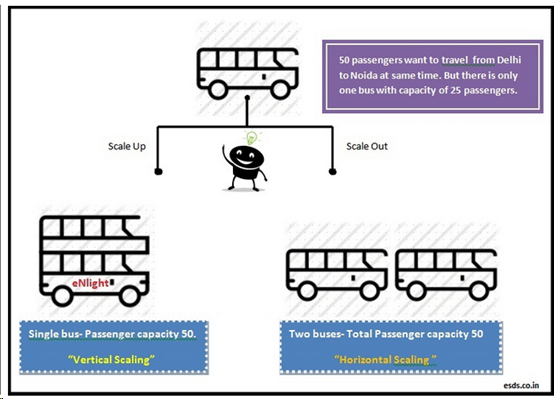
a.面向大数据:当需要存储巨大的数据集时,有两个选择:其一是所谓的Scale Up or Vertical Scaling,也就是升级你的单机存储空间,并且将该数据集放置在这个单独的存储空间中;其二是Scale Out or Horizontal Scaling,使用多个存储空间,将数据集分割成子集,存放在不同的地方。例如下图:当一辆荷载25人的Bus,坐不下50人时的解决方案:
b.数据存储于Commodity Hardware:使用普通商业硬件存储数据,意味着硬件Failure是正常状态之一,而不是异常,文件系统需要有容错能力(fault tolerance)。所以HDFS中的文件会被复制多份,备份存储于不同的硬件中。
c.数据块(Blocks):HDFS将大数据集,分割成默认为128m的Block进行存储,除最后一个Block之外,其余的Block大小相同。
d.流数据(Streaming Data Access):HDFS采用的并非是面向日常运营活动的OLTP(OnLine Transaction Processing)模式,而是面向分析的OLAP (OnLine Analytical Processing),其基本思想是一次写入,多次读取(Write-Once-Read-Only)
3. Master/Slave Architecture:
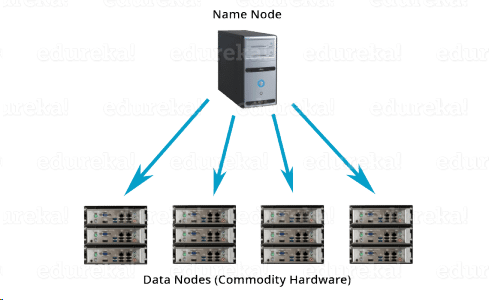
a. Name Node (Master)
每个集群(Cluster)有1至2个Name Node,对集群内数据块存储和分布进行管理。Name Node只存储Metadata,而不存储任何用户数据(User data never resides on the NameNode. The data resides on DataNodes only.)。Master Deamon会在Name Node上面运行,用于管理Data Node。在Metadata中存储着Cluster中所有block的存储位置、大小以及filesystem的变更记录(FsImage,EditLogs)。
b.Data Node (Slave)
每个Cluster中,有众多Data Node,用来存储数据。每个Data Node是一个Commodity Hardware,即性能无法保证,访问失败属于正常状态。Slave Deamon会在Data Node上面运行,并且周期性地向Name Node上报Heartbeat(3s).
4. Blocks:Hadoop将超大文件分割为一个个的Blocks,然后将各个Blocks分散到Cluster的各个Data Nodes中。除最后一个Block外,各个Blocks都有相同的大小(128m)。见下图的例子。

Hadoop(1): HDFS基础架构的更多相关文章
- Hadoop系列-HDFS基础
基本原理 HDFS(Hadoop Distributed File System)是Hadoop的一个基础的分布式文件系统,这个分布式的概念主要体现在两个地方: 数据分块存储在多台主机 数据块采取冗余 ...
- 每天收获一点点------Hadoop之HDFS基础入门
一.HDFS出现的背景 随着社会的进步,需要处理数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是却不方便管理和维护—>因此,迫切需要一种系统来管理多 ...
- 深入理解Hadoop之HDFS架构
Hadoop分布式文件系统(HDFS)是一种分布式文件系统.它与现有的分布式文件系统有许多相似之处.但是,与其他分布式文件系统的差异是值得我们注意的: HDFS具有高度容错能力,旨在部署在低成本硬件上 ...
- Hadoop(分布式系统基础架构)---Hive与HBase区别
对于刚接触大数据的用户来说,要想区分Hive与HBase是有一定难度的.本文将尝试从其各自的定义.特点.限制.应用场景等角度来进行分析,以作抛砖引玉之用. Hive是什么? Apache Hive是 ...
- hadoop之yarn详解(基础架构篇)
本文主要从yarn的基础架构和yarn的作业执行流程进行阐述 一.yarn的概述 Apache Yarn(Yet Another Resource Negotiator的缩写)是hadoop集群资源管 ...
- hadoop - hdfs 基础操作
hdfs --help # 所有参数 hdfs dfs -help # 运行文件系统命令在Hadoop文件系统 hdfs dfs -ls /logs # 查看 hdfs dfs -ls /user/ ...
- Hadoop 分布式文件系统:架构和设计
引言 Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统.它和现有的分布式文件系统有很多共同点.但同时,它和其他的分布式文件系统 ...
- b2c项目基础架构分析(二)前端框架 以及补漏的第一篇名词解释
继续上篇,上篇里忘记了也很重要的前端部分,今天的网站基本上是以一个启示页,然后少量的整页切换,大量的浏览器后台调用web服务局部.动态更新页面显示状态这种方式在运作的,从若干年前简单的ajax流行起来 ...
- b2c项目基础架构分析(一)b2c 大型站点方案简述 已补充名词解释
我最近一直在找适合将来用于公司大型bs,b2b b2c的基础架构. 实际情况是要建立一个bs架构b2b.b2c的网站,当然还包括wap站点.手机app站点. 一.现有公司技术人员现状: 1.熟悉asp ...
随机推荐
- NancyFx 2.0的开源框架的使用-ConstraintRouting
新建一个空的Web项目 然后在Nuget库中安装下面两个包 Nancy Nancy.Hosting.Aspnet 然后在根目录添加三个文件夹,分别是models,Module,Views 然后往Mod ...
- 利用tesseract-ocr进行验证码识别
因为爬虫项目需要模拟登陆,可是有一个网站的登录需要输入验证码.其实这种登录有2种解决方案,一种是利用cookie,一种是识别图片.前者需要人工登录一次,而且有时效限制,故不太现实.后者可以,但是难点是 ...
- mysql语句之DDL
SQL分类: DDL(Data Definition Languages)语句:数据定义语言,这些语句定义了不同的数据段.数据库.表.列.索引等数据库对象的定义.常用的语句关键字主要包括create. ...
- 类目(category) - 类扩展(extension) 区别
说明: 方法,属性或变量: 类别只能添加方法,不能添加属性(理论上,但可以通过runtime的关联添加). 扩展可以添加方法和实例变量或属性,实例变量默认@private类型.扩展是类别的一个特例 ...
- vue报错TypeError: Cannot read property 'protocol' of undefined
错误信息如下所示: isURLSameOrigin.js?3934:57 Uncaught (in promise) TypeError: Cannot read property 'protocol ...
- ZYNQ系列
赛灵思公司(Xilinx)推出的行业第一个可扩展处理平台Zynq系列.旨在为视频监视.汽车驾驶员辅助以及工厂自动化等高端嵌入式应用提供所需的处理与计算性能水平. 中文名 ZYNQ系列 开发商 赛灵 ...
- bzoj4811 [Ynoi2017]由乃的OJ 树链剖分+贪心+二进制
题目传送门 https://lydsy.com/JudgeOnline/problem.php?id=4811 题解 我现在为什么都写一题,调一天啊,马上真的退役不花一分钱了. 考虑这道题的弱化版 N ...
- LeetCode--051--N皇后(java)-star
n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击. 上图为 8 皇后问题的一种解法. 给定一个整数 n,返回所有不同的 n 皇后问题的解决方案. 每一种解 ...
- LeetCode--039--组合总和(java)
给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合. candidates 中的数字可以无限制重复被选 ...
- Knative 实战:基于 Knative Serverless 技术实现天气服务
提到天气预报服务,我们第一反应是很简单的一个服务啊,目前网上有大把的天气预报 API 可以直接使用,有必要去使用 Knative 搞一套吗?杀鸡用牛刀?先不要着急,我们先看一下实际的几个场景需求: 场 ...