Hadoop: 在Azure Cluster上使用MapReduce
Azure对于学生账户有260刀的免费试用,火急火燎地创建Hadoop Cluster!本例子是使用Hadoop MapReduce来统计一本电子书中各个单词的出现个数.
Let's get hands dirty!
首先,我们在Azure中创建了一个Cluster,并且使用putty Ssh访问了该集群,ls一下:
在cluster上创建一个/home/hduser/文件夹

OK,接下来在本地创建一个mapper.py文件和reducer.py文件,注意权限:chmod +x reducer.py(mapper.py)
mapper.py代码
#!/usr/bin/env python
"""mapper.py""" import sys # input comes from STDIN (standard input)
for line in sys.stdin:
# remove leading and trailing whitespace
line = line.strip()
# split the line into words
words = line.split()
# increase counters
for word in words:
# write the results to STDOUT (standard output);
# what we output here will be the input for the
# Reduce step, i.e. the input for reducer.py
#
# tab-delimited; the trivial word count is 1
print '%s\t%s' % (word, 1)
reducer.py代码
#!/usr/bin/env python
"""reducer.py""" from operator import itemgetter
import sys current_word = None
current_count = 0
word = None # input comes from STDIN
for line in sys.stdin:
# remove leading and trailing whitespace
line = line.strip() # parse the input we got from mapper.py
word, count = line.split('\t', 1) # convert count (currently a string) to int
try:
count = int(count)
except ValueError:
# count was not a number, so silently
# ignore/discard this line
continue # this IF-switch only works because Hadoop sorts map output
# by key (here: word) before it is passed to the reducer
if current_word == word:
current_count += count
else:
if current_word:
# write result to STDOUT
print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word # do not forget to output the last word if needed!
if current_word == word:
print '%s\t%s' % (current_word, current_count)
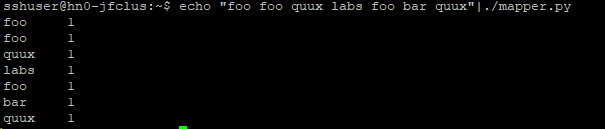
本地mapper.py测试: echo "foo foo quux labs foo bar quux" | ./mapper.py
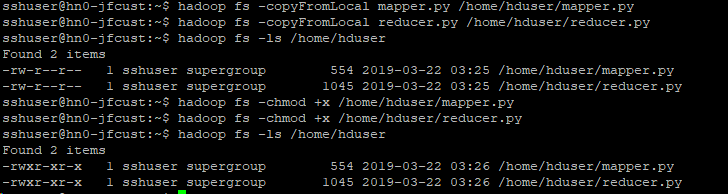
并复制到Cluster上:
本例中,我们使用一本电子书,地址是http://www.gutenberg.org/cache/epub/20417/pg20417.txt,直接在linux客户端下载后,上传到cluster中
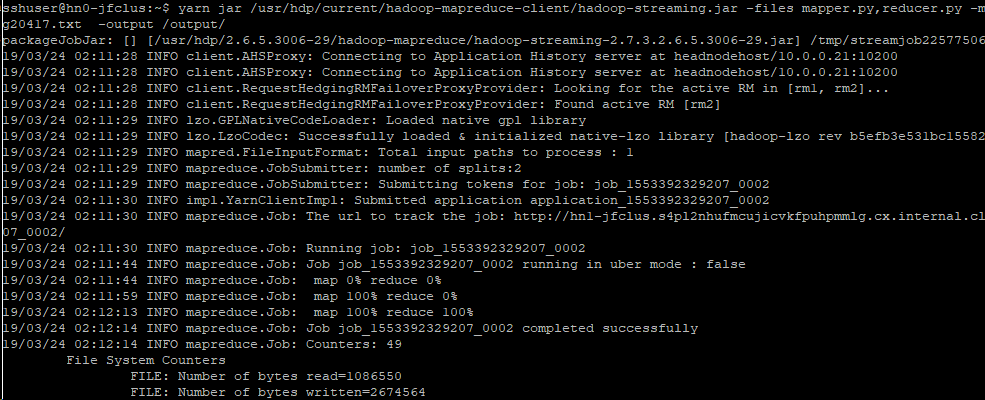
OK,万事俱备,运行MapReduce
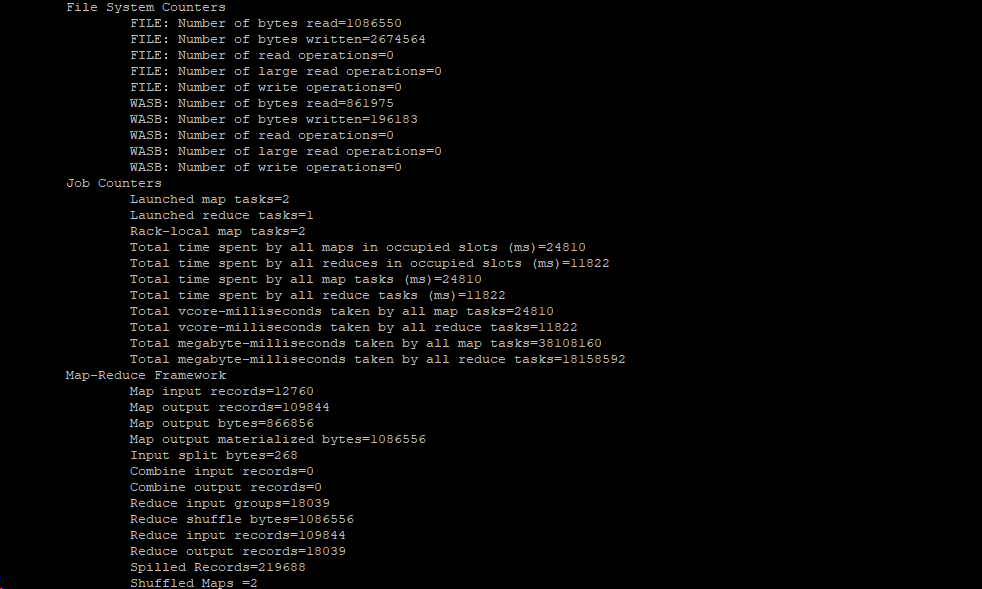

查看输出文件前20行

相关参考文章:
http://www.michael-noll.com/tutorials/writing-an-hadoop-mapreduce-program-in-python/
https://docs.microsoft.com/en-us/azure/hdinsight/hadoop/apache-hadoop-streaming-python
http://hadooptutorial.info/hdfs-file-system-commands/
Hadoop: 在Azure Cluster上使用MapReduce的更多相关文章
- Hadoop 系列文章(三) 配置部署启动YARN及在YARN上运行MapReduce程序
这篇文章里我们将用配置 YARN,在 YARN 上运行 MapReduce. 1.修改 yarn-env.sh 环境变量里的 JAVA_HOME 路径 [bamboo@hadoop-senior ha ...
- 【Cloud Computing】Hadoop环境安装、基本命令及MapReduce字数统计程序
[Cloud Computing]Hadoop环境安装.基本命令及MapReduce字数统计程序 1.虚拟机准备 1.1 模板机器配置 1.1.1 主机配置 IP地址:在学校校园网Wifi下连接下 V ...
- 如何在cluster上跑R脚本
R 是一个比较不错但是有时候操蛋的语言,不错是因为用着爽的时候真的很爽,操蛋是因为这种爽不是什么时候都可以的,比如说在cluster上批处理跑R脚本. 当然说这话有些在上面跑过的各种不服气,你丫傻逼吧 ...
- Hadoop:使用Mrjob框架编写MapReduce
Mrjob简介 Mrjob是一个编写MapReduce任务的开源Python框架,它实际上对Hadoop Streaming的命令行进行了封装,因此接粗不到Hadoop的数据流命令行,使我们可以更轻松 ...
- Azure 网站上的 Java
编辑人员注释:本文章由Windows Azure 网站团队的项目经理Chris Compy 撰写. Microsoft 已推出针对 Azure 网站上基于 Java 的网站的支持.此功能旨在通过 ...
- 在 Azure 网站上使用 Memcached 改进 WordPress
编辑人员注释:本文章由 Windows Azure 网站团队的项目经理 Sunitha Muthukrishna 和 Windows Azure 网站开发人员体验合作伙伴共同撰写. 您是否希望改善在 ...
- Windows Azure 网站上的 WebSocket 简介
编辑人员注释:本文章由 Windows Azure 网站团队的首席项目经理 Stefan Schackow 撰写. Windows Azure 网站最近新增了对 WebSocket 协议的支持..NE ...
- 删除 Windows Azure 网站上的标准服务器头
编辑人员注释: 本文章由 Windows Azure 网站团队的项目经理 Erez Benari 撰写. 请求和响应中包含的 HTTP 头是Web 服务器和浏览器之间的 HTTP 通信过程的一部分.例 ...
- 在 Windows Azure 网站上使用 Django、Python 和 MySQL:创建博客应用程序
编辑人员注释:本文章由 Windows Azure 网站团队的项目经理 Sunitha Muthukrishna 撰写. 根据您编写的应用程序,Windows Azure 网站上的基本Python 堆 ...
随机推荐
- 利用js使图片外层盒子的高等于适应图片的高
JS代码如下:<script> $(window).load(function(){ var width=$(window).width(); var img_1=$(".hot ...
- SQL结构化查询语言
一.SQL 结构化查询语言 1.T-SQL 和 SQL的关系 T-SQL是SQL的增强版 2.SQL的组成 2.1 DML (数据操作语言) 增加,修改,删除等数据操作 2.2 DCL (数据控制语言 ...
- FFmpeg从入门到出家(HEVC在RTMP中的扩展)
由金山云视频云技术团队提供:FFmpeg从入门到出家第三季: 为推进HEVC视频编码格式在直播方案中的落地,经过CDN联盟讨论,并和主流云服务厂商达成一致,规范了HEVC在RTMP/FLV中的扩展,具 ...
- Linux安装Sqoop及基础使用
下载Sqoop 官网地址 http://sqoop.apache.org/ wget http://mirrors.hust.edu.cn/apache/sqoop/1.4.7/sqoop-1.4.7 ...
- Ubuntu16.04 重新安装误删的某个*.so文件
在使用Ubuntu系统时,如果不小心将某个*.so文件删除,该如何重新安装呢? 如果直接使用命令:sudo apt-get install *.so 可能会报错或者找不到这个*.so文件. 正确 ...
- bzoj4448 [Scoi2015]情报传递 主席树+树上差分
题目传送门 https://lydsy.com/JudgeOnline/problem.php?id=4448 题解 练习一下主席树的基础练习题找回感觉. 对于每一次询问,第一问显然随便做. 第二问的 ...
- js中(try catch) 对代码的性能影响
https://blog.csdn.net/shmnh/article/details/52445186 起因 要捕获 JavaScript 代码中的异常一般会采用 try catch,不过 try ...
- No module named flask 导包失败,Python3重新安装Flask模块
在部署环境过程中,通过pip install -r requirements.txt安装包,结果启动项目时总是报错,显示没有flask模块,通过pip install flask还是不行,于是下载fl ...
- 英语单词independent
来源——https://www.docker.com/products/docker-hub 回到顶部 Share and Collaborate with Docker Hub Docker Hub ...
- CSS基础知识总结二
<!DOCTYPE html> <html lang="en" xmlns="http://www.w3.org/1999/html"> ...