L1、L2损失函数、Huber损失函数
L1范数损失函数,也被称为最小绝对值偏差(LAD),最小绝对值误差(LAE)
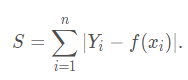
L2范数损失函数,也被称为最小平方误差(LSE)

| L2损失函数 | L1损失函数 |
|---|---|
| 不是非常的鲁棒(robust) | 鲁棒 |
| 稳定解 | 不稳定解 |
| 总是一个解 | 可能多个解 |
鲁棒性
最小绝对值偏差之所以是鲁棒的,是因为它能处理数据中的异常值。如果需要考虑任一或全部的异常值,那么最小绝对值偏差是更好的选择。
L2范数将误差平方化(如果误差大于1,则误差会放大很多),模型的误差会比L1范数来得大,因此模型会对这个样本更加敏感,这就需要调整模型来最小化误差。如果这个样本是一个异常值,模型就需要调整以适应单个的异常值,这会牺牲许多其它正常的样本,因为这些正常样本的误差比这单个的异常值的误差小。
稳定性
最小绝对值偏差方法的不稳定性意味着,对于数据集的一个小的水平方向的波动,回归线也许会跳跃很大。
相反地,最小平方法的解是稳定的,因为对于一个数据点的任何微小波动,回归线总是只会发生轻微移动
总结
MSE对误差取了平方,如果存在异常值,那么这个MSE就很大。
MAE更新的梯度始终相同,即使对于很小的值,梯度也很大,可以使用变化的学习率。MSE就好很多,使用固定的学习率也能有效收敛。
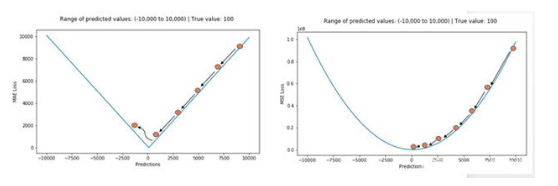
总而言之,处理异常点时,L1损失函数更稳定,但它的导数不连续,因此求解效率较低。L2损失函数对异常点更敏感,但通过令其导数为0,可以得到更稳定的封闭解。
Huber
l1和l2都存在的问题:
若数据中90%的样本对应的目标值为150,剩下10%在0到30之间。
那么使用MAE作为损失函数的模型可能会忽视10%的异常点,而对所有样本的预测值都为150,因为模型会按中位数来预测;
MSE的模型则会给出很多介于0到30的预测值,因为模型会向异常点偏移。
这些情况下最简单的办法是对目标变量进行变换。而另一种办法则是换一个损失函数,这就引出了下面要讲的第三种损失函数,即Huber损失函数。
Huber损失,平滑的平均绝对误差
Huber损失对数据中的异常点没有平方误差损失那么敏感。
本质上,Huber损失是绝对误差,只是在误差很小时,就变为平方误差。误差降到多小时变为二次误差由超参数δ(delta)来控制。当Huber损失在[0-δ,0+δ]之间时,等价为MSE,而在[-∞,δ]和[δ,+∞]时为MAE。
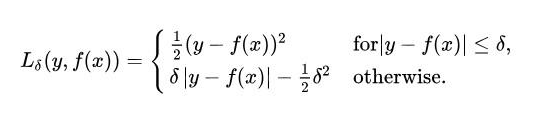
Huber损失结合了MSE和MAE的优点,对异常点更加鲁棒。
L1、L2损失函数、Huber损失函数的更多相关文章
- 回归损失函数:L1,L2,Huber,Log-Cosh,Quantile Loss
回归损失函数:L1,L2,Huber,Log-Cosh,Quantile Loss 2019-06-04 20:09:34 clover_my 阅读数 430更多 分类专栏: 阅读笔记 版权声明: ...
- 机器学习之正则化【L1 & L2】
前言 L1.L2在机器学习方向有两种含义:一是L1范数.L2范数的损失函数,二是L1.L2正则化 L1范数.L2范数损失函数 L1范数损失函数: L2范数损失函数: L1.L2分别对应损失函数中的绝对 ...
- 正则化 L1 L2
机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作ℓ1ℓ1-norm和ℓ2ℓ2-norm,中文称作L1正则化和L2正则化,或者L1范数和L2范数. L1正则化和 ...
- ML-线性模型 泛化优化 之 L1 L2 正则化
认识 L1, L2 从效果上来看, 正则化通过, 对ML的算法的任意修改, 达到减少泛化错误, 但不减少训练误差的方式的统称 训练误差 这个就损失函数什么的, 很好理解. 泛化错误 假设 我们知道 预 ...
- 机器学习中L1,L2正则化项
搞过机器学习的同学都知道,L1正则就是绝对值的方式,而L2正则是平方和的形式.L1能产生稀疏的特征,这对大规模的机器学习灰常灰常重要.但是L1的求解过程,实在是太过蛋疼.所以即使L1能产生稀疏特征,不 ...
- L0/L1/L2范数的联系与区别
L0/L1/L2范数的联系与区别 标签(空格分隔): 机器学习 最近快被各大公司的笔试题淹没了,其中有一道题是从贝叶斯先验,优化等各个方面比较L0.L1.L2范数的联系与区别. L0范数 L0范数表示 ...
- 机器学习 - 正则化L1 L2
L1 L2 Regularization 表示方式: $L_2\text{ regularization term} = ||\boldsymbol w||_2^2 = {w_1^2 + w_2^2 ...
- 阅读ARM Memory(L1/L2/MMU)笔记
<ARM Architecture Reference Manual ARMv8-A>里面有Memory层级框架图,从中可以看出L1.L2.DRAM.Disk.MMU之间的关系,以及他们在 ...
- L1&L2 Regularization的原理
L1&L2 Regularization 正则化方法:防止过拟合,提高泛化能力 在训练数据不够多时,或者overtraining时,常常会导致overfitting(过拟合).其直观的表现 ...
随机推荐
- Python3解leetcode Binary Tree PathsAdd DigitsMove Zeroes
问题描述: Given an array nums, write a function to move all 0's to the end of it while maintaining the r ...
- 容器————vector
目录 一.介绍 二.声明及初始化 三.方法 front find remove erase substr 一.介绍 向量 vector 是一种对象实体, 能够容纳许多其他类型相同的元素, 因此又被称为 ...
- 【2019 Multi-University Training Contest 4】
01:https://www.cnblogs.com/myx12345/p/11644076.html 02: 03:https://www.cnblogs.com/myx12345/p/116478 ...
- Radical and array
Radical and array 时间限制: 1 Sec 内存限制: 128 MB提交: 46 解决: 27[提交][状态] 题目描述 Radical has an array , he wan ...
- 部署Jenkins完整记录
Jenkins通过脚本任务触发,实现代码的自动化分发,是CI持续化集成环境中不可缺少的一个环节.下面对Jenkins环境的部署做一记录.-------------------------------- ...
- English-spoken
May i come in? 我可以进来么? May I introduce myself? 我能做个自我介绍么? I'm sorry I didn't hear that clearly. May ...
- 迪杰斯特拉算法(Dijkstra)
模板一: 时间复杂度O(n2) int dijkstra(int s,int m) //s为起点,m为终点 { memset(dist,,sizeof(dist)); //初始化,dist数组用来储存 ...
- C++学习书籍推荐
列出几本侯捷老师推荐的书1. C++程序员必备的书a) <C++ Programming Language> Bjarne Stroustrupb) <C++ Primer> ...
- luoguP3258 [JLOI2014]松鼠的新家 题解(树上差分)
P3258 [JLOI2014]松鼠的新家 题目 树上差分:树上差分总结 #include<iostream> #include<cstdlib> #include<c ...
- POJ 2112 /// 最大流+floyd+二分
题目大意: 有 k台挤奶机 和 c头奶牛 每台挤奶机最多为m头奶牛服务 给定所有挤奶机和奶牛两两之间的距离 求一种分配 使得 奶牛与挤奶机之间的最远距离 最小化 floyd求得所有挤奶机与奶牛两两之间 ...