机器学习之正则化【L1 & L2】
前言
L1、L2在机器学习方向有两种含义:一是L1范数、L2范数的损失函数,二是L1、L2正则化
L1范数、L2范数损失函数
L1范数损失函数:
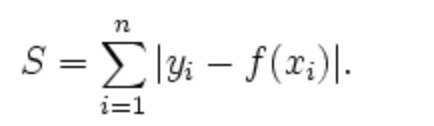
L2范数损失函数:
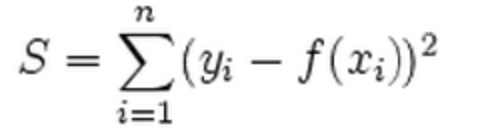
L1、L2分别对应损失函数中的绝对值损失函数和平方损失函数
区别:
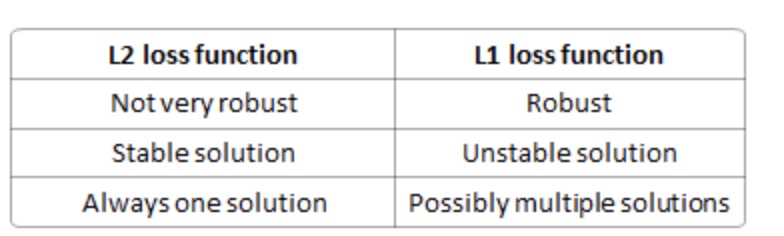
分析:
robust: 与L2相比,L1受异常点影响比较小,因此稳健
stable: 如果仅一个点,L1就是一个直线,L2是二次,对于直线来说是多解,因此不稳定,而二次函数只有一个极小值点
L1、L2正则化
为什么出现正则化?
正则化的根本原因是 输入样本的丰度不够,不能涵盖所有的情况。
解决策略 :
- 对数据源扩充的方法:
输⼊数据源加上满⾜⼀定分布律的噪声,然后把加上噪声后的输⼊源当作“伪”新训练样本。
针对图⽚,还可以采取部分截取、⾓度旋转等数据增强⼿段,增加“新”样本。对于词表,可以增加单词的近义词,也能达到类似的效果。
- ⽹络权值的修正
神经⽹络的训练,对某些权值较为敏感。对权值稍微进⾏⼀些修改,训练的结果可能就迥然不同,所以为了保证⽹络的泛化能⼒,有必要对权值进⾏修正。具体的做法是,在⽹络的权值上加上符合⼀定分布规律的噪声,然后再重新训练⽹络,这样就增加了整个⽹络的“抗打击”能⼒,⽹络的输出结果就不会随数据源的变化⽽有很⼤变动
- 采取“早停”策略
提前停⽌训练。虽然接着训练可能会让训练误差变⼩,但让泛化误差更⼩,才是我们更⾼的⽬标
- 也可以采用集成方法,训练多个模型
- dropout
其本质就是通过改变神经⽹络的结构,⼈为添加⽹络的不确定性,从⽽锻炼神经⽹络的泛化能⼒。换句话说,通过丢弃部分节点,让各个⼦⽹络变得不同
一、L1的出现是为了解决什么问题?怎么解决的
L1就是参数的绝对值之和,它的目的就是为了产生一个关于参数w的稀疏矩阵
1、为什么会产生稀疏矩阵?
参考:https://www.zhihu.com/question/37096933
首先,我们要优化的是这个问题 。
其次, 和
这个优化问题是等价的,即对一个特定的 总存在一个
使得这两个问题是等价的(这个是优化里的知识)。
最后,下面这个图表达的其实
这个优化问题,把 的解限制在黄色区域内,同时使得经验损失尽可能小
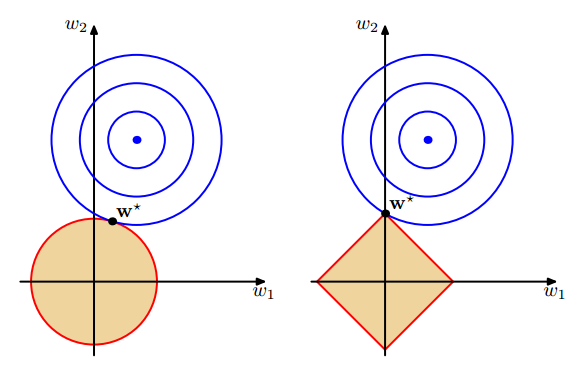
【高频面试题】为什么l1比l2更容易得到稀疏解?https://www.zhihu.com/question/37096933
从两方面解释,一是直观解释,另一种是梯度推导
【直观解释】
如上所述,无论是L1,还是L2都可以看成一种条件优化问题,L1所对应的优化区间是个菱形(右图),L2对应的是个圆形,而最优解就是 等高线与限定区间的交点,对于L1,交点是在坐标轴上,对于L2,交点是不在坐标轴上,所以L1更容易得到稀疏解。
【梯度解释】

2、产生稀疏矩阵的目的?
参考:https://blog.csdn.net/zouxy09/article/details/24971995
产生稀疏矩阵的好处可以从特征选择来解释
1)实现特征的自动选择
用于训练的数据的特征维度非常多,并且这么多的特征对于最后的结果来说并不是所有的都有用,而且特征之间还有线性关系,当考虑这些无用的特征xi时,可以获得较小的训练误差(不太理解),但在预测新的样本时,这些没用的信息反而会被考虑,从而干扰了对正确yi的预测。所以L1会学习地去掉这些没有信息的特征,也就是把这些特征对应的权重置为0。
二、为什么会出现L2
L2范数是指向量各元素的平方和然后求平方根。我们让L2范数的规则项||W||2最小,可以使得W的每个元素都很小,都接近于0,但与L1范数不同,它不会让它等于0,而是接近于0,这里是有很大的区别的。而越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象 。
L2的好处:
1)、防止过拟合,提高泛化能力
2)、从优化或者数值计算的角度来说,L2范数有助于处理 condition number不好的情况下矩阵求逆很困难的问题(不理解)
L1会趋向于产生少量的特征,而其他的特征都是0,从而产生稀疏矩阵,自动选择特征,而L2会考虑更多的特征,这些特征都会接近于0,因此不是稀疏矩阵。
疑问:
1)产生稀疏矩阵好还是不产生稀疏矩阵好,产生稀疏矩阵感觉有点降维的感觉,会选择有用的特征?
感觉L2比L1好,因为L2产生的接近于稀疏的矩阵,不是0但接近0,这样能考虑更多的特征,而对没用的特征不会一棍子打死,只是给一个很小的权重
三、Tensorflow中L1、L2的实现
tf.nn.l2_loss(t, name=None)对t采用l2范式进行计算:output = sum(t ** 2) / 2, t是一维或者多维数组。
tf.add_n([p1, p2, p3....]) 实现列表元素相加,p1, p2, p3分别表示列表
一种显示的计算:
loss = (tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(
logits=out_layer, labels=tf_train_labels)) +
0.01*tf.nn.l2_loss(hidden_weights) +
0.01*tf.nn.l2_loss(hidden_biases) +
0.01*tf.nn.l2_loss(out_weights) +
0.01*tf.nn.l2_loss(out_biases))#考虑了weight和bias
一种隐式的计算:
vars = tf.trainable_variables() //获取所以的变量
lossL2 = tf.add_n([ tf.nn.l2_loss(v) for v in vars ]) * 0.001 //所有的变量使用l2计算方式累加
//不考虑bias的情况
lossL2 = tf.add_n([ tf.nn.l2_loss(v) for v in vars
if 'bias' not in v.name ])
//把l2损失加入到loss项里
loss = (tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(
logits=out_layer, labels=tf_train_labels)) +
0.001*lossL2)
L1不可导点如何优化:
1、坐标轴下降法
2、近似算法
https://www.cnblogs.com/ZeroTensor/p/11099332.html
参考:
[1] http://www.chioka.in/differences-between-l1-and-l2-as-loss-function-and-regularization/
[2] https://blog.csdn.net/chaowang1994/article/details/80388990
机器学习之正则化【L1 & L2】的更多相关文章
- 机器学习 - 正则化L1 L2
L1 L2 Regularization 表示方式: $L_2\text{ regularization term} = ||\boldsymbol w||_2^2 = {w_1^2 + w_2^2 ...
- 正则化 L1 L2
机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作ℓ1ℓ1-norm和ℓ2ℓ2-norm,中文称作L1正则化和L2正则化,或者L1范数和L2范数. L1正则化和 ...
- 机器学习中正则化项L1和L2的直观理解
正则化(Regularization) 概念 L0正则化的值是模型参数中非零参数的个数. L1正则化表示各个参数绝对值之和. L2正则化标识各个参数的平方的和的开方值. L0正则化 稀疏的参数可以防止 ...
- 机器学习中的L1、L2正则化
目录 1. 什么是正则化?正则化有什么作用? 1.1 什么是正则化? 1.2 正则化有什么作用? 2. L1,L2正则化? 2.1 L1.L2范数 2.2 监督学习中的L1.L2正则化 3. L1.L ...
- 机器学习中L1,L2正则化项
搞过机器学习的同学都知道,L1正则就是绝对值的方式,而L2正则是平方和的形式.L1能产生稀疏的特征,这对大规模的机器学习灰常灰常重要.但是L1的求解过程,实在是太过蛋疼.所以即使L1能产生稀疏特征,不 ...
- 【深度学习】L1正则化和L2正则化
在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况.正则化是机器学习中通过显式的控制模 ...
- L1正则化比L2正则化更易获得稀疏解的原因
我们知道L1正则化和L2正则化都可以用于降低过拟合的风险,但是L1正则化还会带来一个额外的好处:它比L2正则化更容易获得稀疏解,也就是说它求得的w权重向量具有更少的非零分量. 为了理解这一点我们看一个 ...
- L1正则化和L2正则化
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择 L2正则化可以防止模型过拟合(overfitting):一定程度上,L1也可以防止过拟合 一.L1正则化 1.L1正则化 需注意, ...
- L1,L2范数和正则化 到lasso ridge regression
一.范数 L1.L2这种在机器学习方面叫做正则化,统计学领域的人喊她惩罚项,数学界会喊她范数. L0范数 表示向量xx中非零元素的个数. L1范数 表示向量中非零元素的绝对值之和. L2范数 表 ...
随机推荐
- 4.14Python数据处理篇之Matplotlib系列(十四)---动态图的绘制
目录 目录 前言 (一)需求分析 (二)随机数的动态图 1.思路分析: 2.源代码: 2.输出效果: 目录 前言 学习matplotlib已经到了尾声,没有必要再继续深究下去了,现今只是学了一些基础的 ...
- admin组件
Django 提供了基于 web 的管理工具. Django 自动管理工具是 django.contrib 的一部分.你可以在项目的 settings.py 中的 INSTALLED_APPS 看到它 ...
- git、github、gitlab之间的关系
GIt-版本控制工具:GitHub-一个网站平台,提供给用户空间存储git仓储,保存用户的一些数据文档或者代码等:GitLab - 基于Git的项目管理软件. Git分布式版本控制系统 Git是一款自 ...
- Maven pom.xml中的元素modules、parent、properties以及import
前言 项目中用到了maven,而且用到的内容不像利用maven/eclipse搭建ssm(spring+spring mvc+mybatis)用的那么简单:maven的核心是pom.xml,那么我就它 ...
- $.extend()浅拷贝深拷贝
参考网址:http://bijian1013.iteye.com/blog/2255037 jQuery.extend() 函数用于将一个或多个对象的内容合并到目标对象. 注意:1. 如果只为$.ex ...
- Luogu P5296 [北京省选集训2019]生成树计数
Luogu P5296 [北京省选集训2019]生成树计数 题目链接 题目大意:给定每条边的边权.一颗生成树的权值为边权和的\(k\)次方.求出所有生成树的权值和. 我们列出答案的式子: 设\(E\) ...
- day12-内置模块学习(三)
我的博客呀,从以前的预习变成了复习了,复习的东西还没有写完,哎 今日目录 1.序列化模块 2.加密模块 3.包的使用 4.random模块 5.shutil模块 开始今日份总结 1.序列化模块 在学习 ...
- Analyzing 'enq: HW - contention' Wait Event (Doc ID 740075.1)
Analyzing 'enq: HW - contention' Wait Event (Doc ID 740075.1) In this Document Symptoms Cause ...
- Shiro学习(一)——Shiro简介
Apache Shiro是Java的一个安全框架.目前,使用Apache Shiro的人越来越多,因为它相当简单,对比Spring Security,可能没有Spring Security做的功能强大 ...
- LOJ2396 JOISC2017 长途巴士 斜率优化
传送门 将乘客按照\(D_i\)从小到大排序并重新标号.对于服务站\(j\),如果\(S_j \mod T \in (D_i , D_{i+1})\),那么可以少接一些水,在保证司机有水喝的情况下让编 ...