KNN算法和实现

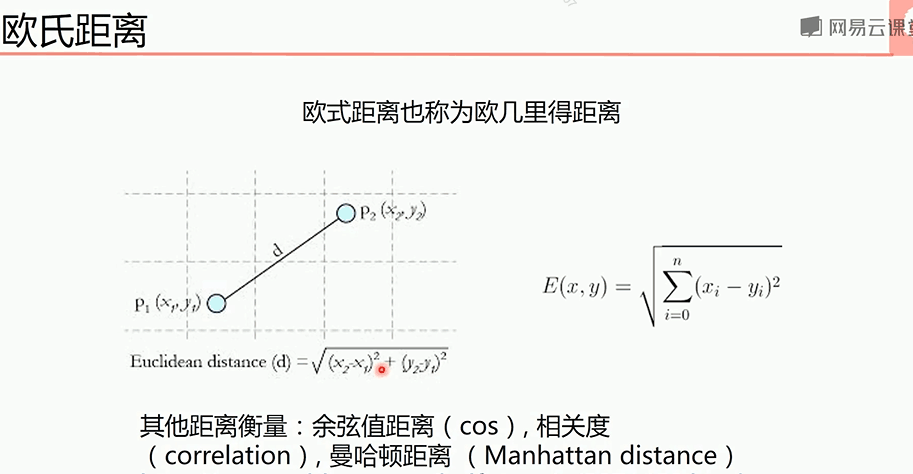
KNN要用到欧氏距离
KNN下面的缺点很容易使分类出错(比如下面黑色的点)

下面是KNN算法的三个例子demo,
第一个例子是根据算法原理实现
import matplotlib.pyplot as plt
import numpy as np
import operator
# 已知分类的数据
x1 = np.array([,,])
y1 = np.array([,,])
x2 = np.array([,,])
y2 = np.array([,,])
scatter1 = plt.scatter(x1,y1,c='r')
scatter2 = plt.scatter(x2,y2,c='b')
# 未知数据
x = np.array([])
y = np.array([])
scatter3 = plt.scatter(x,y,c='k')
#画图例
plt.legend(handles=[scatter1,scatter2,scatter3],labels=['labelA','labelB','X'],loc='best')
plt.show()
# 已知分类的数据
x_data = np.array([[,],
[,],
[,],
[,],
[,],
[,]])
y_data = np.array(['A','A','A','B','B','B'])
x_test = np.array([,])
# 计算样本数量
x_data_size = x_data.shape[]
print(x_data_size)
# 复制x_test
print(np.tile(x_test, (x_data_size,)))
# 计算x_test与每一个样本的差值
diffMat = np.tile(x_test, (x_data_size,)) - x_data
diffMat
# 计算差值的平方
sqDiffMat = diffMat**
sqDiffMat
# 求和
sqDistances = sqDiffMat.sum(axis=)
sqDistances
# 开方
distances = sqDistances**0.5
print(distances)
# 从小到大排序
sortedDistances = distances.argsort()#返回distances里的数据从小到大的下标数组
print(sortedDistances)
classCount = {}
# 设置k
k =
for i in range(k):
# 获取标签
votelabel = y_data[sortedDistances[i]]
# 统计标签数量
classCount[votelabel] = classCount.get(votelabel,) + #)0表示没有该字典里没有该值时默认为0
classCount
# 根据operator.itemgetter()-第1个值对classCount排序,然后再取倒序
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(), reverse=True)
print(sortedClassCount)
# 获取数量最多的标签
knnclass = sortedClassCount[][]#第一个0表示取第一个键值对('A', ),第二个0表示取('A', )的‘A’
print(knnclass)
1 import numpy as np#对iris数据集进行训练分类
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report,confusion_matrix#对模型分类结果进行评估的两个模型
import operator#https://blog.csdn.net/u010339879/article/details/98304292,关于operator的使用
import random
def knn(x_test, x_data, y_data, k):
x_data_size = x_data.shape[] # 计算样本数量
diffMat = np.tile(x_test,(x_data_size,)) - x_data# 复制x_test,计算x_test与每一个样本的差值
sqDiffMat = diffMat**# # 计算差值的平方
sqDistance = sqDiffMat.sum(axis= ) # 求和
distances = sqDistance**0.5 # 开方
sortedDistance = distances.argsort()# 从小到大排序
classCount = {}
for i in range(k):
vlabel = y_data[sortedDistance[i]] # 获取标签
classCount[vlabel] = classCount.get(vlabel,)+# 统计标签数量
sortedClassCount = sorted(classCount.items(),key = operator.itemgetter(), reverse = True) # 根据operator.itemgetter()-第1个值对classCount排序,然后再取倒序
return sortedClassCount[][]
iris = datasets.load_iris()# 载入数据
x_train,x_test,y_train,y_test = train_test_split(iris.data, iris.target, test_size=0.3)
#打乱数据
# data_size = iris.data.shape[]
# index = [i for i in range(data_size)]
# random.shuffle(index)
# iris.data = iris.data[index]
# iris.target = iris.target[index]
# test_size = #切分数据集
# x_train = iris.data[test_size:]
# x_test = iris.data[:test_size]
# y_train = iris.target[test_size:]
# y_test = iris.target[:test_size]
prodictions = []
for i in range(x_test.shape[]):
prodictions.append(knn(x_test[i],x_train,y_train,))
print(prodictions)
print(classification_report(y_test, prodictions))
print(confusion_matrix(y_test,prodictions))
#关于混淆矩阵可以看这篇博客,#https://www.cnblogs.com/missidiot/p/9450662.html
# 导入算法包以及数据集
from sklearn import neighbors
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
import random
# 载入数据
iris = datasets.load_iris()
#print(iris)
# 打乱数据切分数据集
# x_train,x_test,y_train,y_test = train_test_split(iris.data, iris.target, test_size=0.2) #分割数据0.2为测试数据,.8为训练数据 #打乱数据
data_size = iris.data.shape[]
index = [i for i in range(data_size)]
random.shuffle(index)
iris.data = iris.data[index]
iris.target = iris.target[index] #切分数据集
test_size =
x_train = iris.data[test_size:]
x_test = iris.data[:test_size]
y_train = iris.target[test_size:]
y_test = iris.target[:test_size] # 构建模型
model = neighbors.KNeighborsClassifier(n_neighbors=)
model.fit(x_train, y_train)
prediction = model.predict(x_test)
print(prediction)
print(classification_report(y_test, prediction))
这三个代码第一个,第二个是根据底层原理实现knn算法,第三个则是调用库函数处理数据。
下面一个代码是利用第三个代码中用到的库实现第一个代码功能,可以发现使用系统提供的库,简单许多
from sklearn import neighbors
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
import numpy as np
x_data = np.array([[,],
[,],
[,],
[,],
[,],
[,]])
y_data = np.array(['A','A','A','B','B','B'])
x_test1 = np.array([[,]])
x_train, x_test, y_train,y_test = train_test_split(x_data, y_data,test_size= 0.3)
model = neighbors.KNeighborsClassifier(n_neighbors=)
model.fit(x_train, y_train)
print(x_test1)
prediction = model.predict(x_test1)
print(prediction)
KNN算法和实现的更多相关文章
- 【Machine Learning】KNN算法虹膜图片识别
K-近邻算法虹膜图片识别实战 作者:白宁超 2017年1月3日18:26:33 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本系列文章是作者结 ...
- KNN算法
1.算法讲解 KNN算法是一个最基本.最简单的有监督算法,基本思路就是给定一个样本,先通过距离计算,得到这个样本最近的topK个样本,然后根据这topK个样本的标签,投票决定给定样本的标签: 训练过程 ...
- kNN算法python实现和简单数字识别
kNN算法 算法优缺点: 优点:精度高.对异常值不敏感.无输入数据假定 缺点:时间复杂度和空间复杂度都很高 适用数据范围:数值型和标称型 算法的思路: KNN算法(全称K最近邻算法),算法的思想很简单 ...
- 什么是 kNN 算法?
学习 machine learning 的最低要求是什么? 我发觉要求可以很低,甚至初中程度已经可以. 首先要学习一点 Python 编程,譬如这两本小孩子用的书:[1][2]便可. 数学方面 ...
- 数据挖掘之KNN算法(C#实现)
在十大经典数据挖掘算法中,KNN算法算得上是最为简单的一种.该算法是一种惰性学习法(lazy learner),与决策树.朴素贝叶斯这些急切学习法(eager learner)有所区别.惰性学习法仅仅 ...
- 机器学习笔记--KNN算法2-实战部分
本文申明:本系列的所有实验数据都是来自[美]Peter Harrington 写的<Machine Learning in Action>这本书,侵删. 一案例导入:玛利亚小姐最近寂寞了, ...
- 机器学习笔记--KNN算法1
前言 Hello ,everyone. 我是小花.大四毕业,留在学校有点事情,就在这里和大家吹吹我们的狐朋狗友算法---KNN算法,为什么叫狐朋狗友算法呢,在这里我先卖个关子,且听我慢慢道来. 一 K ...
- 学习OpenCV——KNN算法
转自:http://blog.csdn.net/lyflower/article/details/1728642 文本分类中KNN算法,该方法的思路非常简单直观:如果一个样本在特征空间中的k个最相似( ...
- KNN算法与Kd树
最近邻法和k-近邻法 下面图片中只有三种豆,有三个豆是未知的种类,如何判定他们的种类? 提供一种思路,即:未知的豆离哪种豆最近就认为未知豆和该豆是同一种类.由此,我们引出最近邻算法的定义:为了判定未知 ...
- Python 手写数字识别-knn算法应用
在上一篇博文中,我们对KNN算法思想及流程有了初步的了解,KNN是采用测量不同特征值之间的距离方法进行分类,也就是说对于每个样本数据,需要和训练集中的所有数据进行欧氏距离计算.这里简述KNN算法的特点 ...
随机推荐
- windows中无法访问共享问题
http://jingyan.baidu.com/article/456c463b66d9320a5831448b.html 很多情况下我们遇到我们设置的共享没有密码别人无法访问,为此为大家推荐几步操 ...
- scala 常用模式匹配类型
模式匹配的类型 包括: 常量模式 变量模式 构造器模式 序列模式 元组模式 变量绑定模式等. 常量模式匹配 常量模式匹配,就是在模式匹配中匹配常量 objectConstantPattern{ def ...
- DRF的三大认证组件
目录 DRF的三大认证组件 认证组件 工作原理 实现 权限组件 工作原理 实现 频率组件 工作原理 实现 三种组件的配置 DRF的三大认证组件 认证组件 工作原理 首先,认证组件是基于BaseAuth ...
- SonarQube代码质量扫描持续集成
1.安装JDK和配置JAVA_HOME和CLASSPATH 2.安装mysql数据库 3.创建数据库和用户 mysql -u root -p mysql> CREATE DATABASE son ...
- Task ProgressBar模拟现实完成后显示TextBox
private async void Form1_Load(object sender, EventArgs e) { progressBar1.Maximum = ; progressBar2.Ma ...
- COGS2356 【HZOI2015】有标号的DAG计数 IV
题面 题目描述 给定一正整数n,对n个点有标号的有向无环图进行计数. 这里加一个限制:此图必须是弱连通图. 输出答案mod 998244353的结果 输入格式 一个正整数n. 输出格式 一个数,表示答 ...
- curl 一个使用例子
#include <iostream> #define Main main #include <string> #include <assert.h> #inclu ...
- csps模拟8990部分题解
题面: 666: 重点在题意转化:每个数可以乘k,代价为k,可以减一,代价为1, 所以跑最短路即可 #include<iostream> #include<cstdio> #i ...
- csps模拟87888990部分题解
题面:https://www.cnblogs.com/Juve/articles/11752338.html https://www.cnblogs.com/Juve/articles/1175241 ...
- 手工编写JavaWeb项目
手工编写JavaWeb项目 一.打开Tomcat服务器 二.编写简单的web项目 三.访问项目 并且,tomcat服务器也是可以直接访问.txt的,其实就和其它的web服务器一样,什么都可以访问,和之 ...