Python爬虫:requests模块的基本使用
官方文档:https://requests.readthedocs.io/zh_CN/latest/
基本使用
基本结构
发送请求,获取响应:r = requests.get(url)
爬取网页的通用代码:

HTTP协议对资源的操作
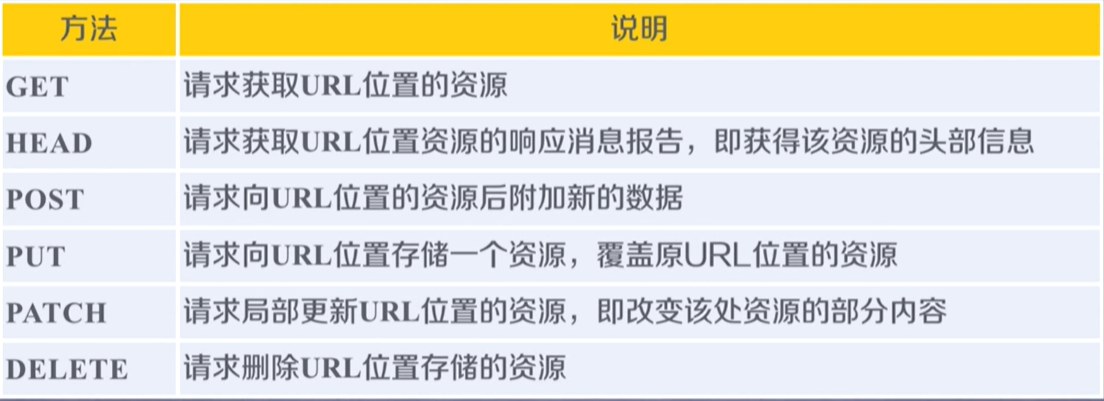
requests库的主要方法

其中request方法的结构为:

其他的几个方法都是通过request来实现的
其中r是Response对象
Response对象常用的属性

Response对象的一些方法
获取响应的json格式数据:response.json()
requests库支持的连接异常
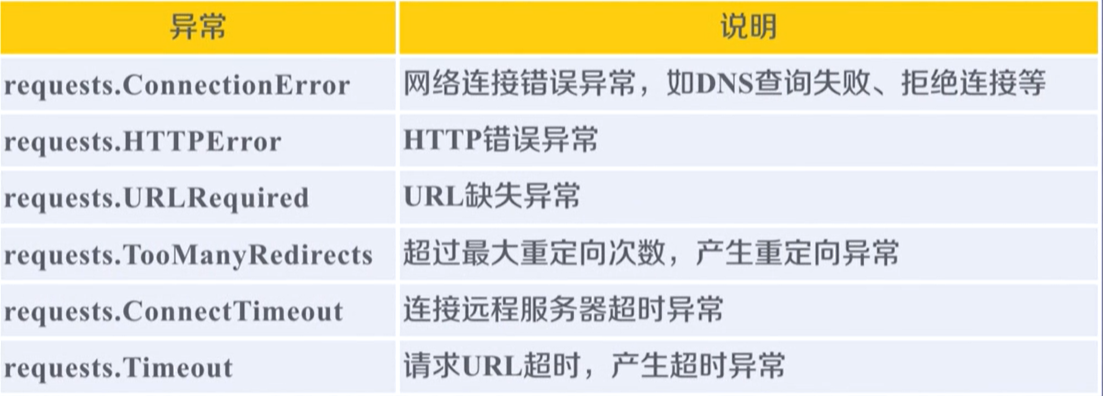
raise_for_status
r.raise_for_status:判断返回的状态码是不是200,不是则抛出一个异常requests.HTTPError
Python爬虫:requests模块的基本使用的更多相关文章
- python 爬虫 requests模块 目录
requests模块(response常用属性) 基于requests模块的get请求 基于requests模块发起ajax的get请求 基于requests模块发起ajax的post请求
- python爬虫requests模块
requests库的七个主要方法 1. requests.requests(method, url, **kwargs) 构造一个请求,支撑以下各方法的基础方法 method:请求方式,对应get/p ...
- python 爬虫 requests模块(response常用属性)
response常用属性 content获取的response对象中的二进制(byte)类型的页面数据response.content 返回响应状态码response.status_code 200 ...
- Python爬虫之使用Fiddler+Postman+Python的requests模块爬取各国国旗
介绍 本篇博客将会介绍一个Python爬虫,用来爬取各个国家的国旗,主要的目标是为了展示如何在Python的requests模块中使用POST方法来爬取网页内容. 为了知道POST方法所需要传 ...
- Python爬虫—requests库get和post方法使用
目录 Python爬虫-requests库get和post方法使用 1. 安装requests库 2.requests.get()方法使用 3.requests.post()方法使用-构造formda ...
- python爬虫 urllib模块url编码处理
案例:爬取使用搜狗根据指定词条搜索到的页面数据(例如爬取词条为‘周杰伦'的页面数据) import urllib.request # 1.指定url url = 'https://www.sogou. ...
- python 爬虫 urllib模块 目录
python 爬虫 urllib模块介绍 python 爬虫 urllib模块 url编码处理 python 爬虫 urllib模块 反爬虫机制UA python 爬虫 urllib模块 发起post ...
- Python之requests模块-hook
requests提供了hook机制,让我们能够在请求得到响应之后去做一些自定义的操作,比如打印某些信息.修改响应内容等.具体用法见下面的例子: import requests # 钩子函数1 def ...
- Python之requests模块-cookie
cookie并不陌生,与session一样,能够让http请求前后保持状态.与session不同之处,在于cookie数据仅保存于客户端.requests也提供了相应到方法去处理cookie. 在py ...
- Python之requests模块-session
http协议本身是无状态的,为了让请求之间保持状态,有了session和cookie机制.requests也提供了相应的方法去操纵它们. requests中的session对象能够让我们跨http请求 ...
随机推荐
- 使用imread()函数读取图片的六种正确姿势
OpenCV实践之路——使用imread()函数读取图片的六种正确姿势 opencv里的argv[1]指向的文件在哪里 测试 #include "opencv2/highgui/highgu ...
- java下载和环境变量配置
初学java,以前没有接触过这方面内容,所以简要记录一下我2个月的学习流程. 首先,我在慕课上学习java的基础,浙江大学翁恺老师的课程. 下载ECLIPSE-java 进入官网:https://ww ...
- 在UTF-8页面中引入编码为GBK的JavaScript文件乱码问题了
原文地址:http://js8.in/2009/12/11/%E5%AF%B9%E5%BC%95%E7%94%A8%E5%A4%96%E9%83%A8javascript%E9%A1%B5%E9%9D ...
- AcWing 873. 欧拉函数
//用定义直接求 #include<bits/stdc++.h> using namespace std; int main() { int n; cin>>n; while( ...
- 随笔js
js中的函数定义之后,函数名就是这个函数(JS中函数其实也是对象)的地址(句柄) js读取函数内存地址: 首先想读内存地址只有C或者C++,汇编抛开不谈,其他高级语言一般都封装起来了,不过我也不能确定 ...
- 2019牛客多校第四场A meeting 思维
meeting 题意 一个树上有若干点上有人,找出一个集合点,使得所有人都到达这个点的时间最短(无碰撞) 思路 就是找树的直径,找直径的时候记得要找有人的点 #include<bits/stdc ...
- Redis非关系型缓存数据库集群部署、参数、命令工具
<关系型数据库与非关系型数据库> 关系数据库:mysql.oracle.DB2.SQL Server非关系数据库:Redis(缓存数据库).MongodDB(处理海量数据).Memcach ...
- Django数据迁移时(或者新建模型时)报错:Did you install mysqlclient,解决后又报错:mysqlclient 1.3.13 or newer is required;you have 0.9.3
报错信息如下: 解决方法一: 给项目根目录下mysite应用下的__init__.py文件加入如下代码: 运行又报错: 报错信息是: mysqlclient版本太低 点击上图框中的链接进入到pyth ...
- Vue-移动端开发全家桶
内容:node.js,vue-cli,vuex,axios,postcss-pxtorem,lib-flexible,vant ,babel-plugin-import 1.安装脚手架工具: npm ...
- instrrev 和instr 区别vb
Private Sub Form_click() Dim temp As String temp = "c:\window\system" Print Mid(temp, InSt ...