HTTP请求过程和状态响应码
HTTP请求过程
我们在浏览器中输入一个URL,回车之后便可以在浏览器中观察到页面内容。实际上,这个过程是浏览器向网站所在的服务器发送了一个请求,网站服务器接收到这个请求后进行处理和解析,然后返回对应的响应,接着传回给浏览器。响应里包含了页面的源代码等内容,浏览器再对其进行解析,便将网页呈现了出来。
# 客户端发送request(请求)给服务器,服务器则会返回一个response(响应)给客户端
此处客户端即代表我们自己的PC或手机浏览器,服务器即要访问的网站所在的服务器。
为了更直观的说明这个过程,这里用Chrome浏览器的开发者模式下的Network监听组件来做下演示,它可以显示访问当前请求网页时发生的所有网络请求和响应。
打开Chrome浏览器,右击并选择"检查"项,即可打开浏览器的开发者工具。这里访问百度http://www.baidu.com/,输入该URL后回车,观察这个过程中发生了怎样的网络请求。可以看到,在Network页面下方出现了一个个的条目,其中一个条目就代表一次发送请求和接受响应的过程。
我们先观察第一个网络请求,即www.baidu.com,其中各列的含义如下。:
- 第一列Name:请求的名称,一般会将URL的最后一部分内容当作名称。
- 第二列Status:响应的状态码,这里显示为200,代表响应是正常的。通过状态码,我们可以判断发送了请求之后是否得到了正常的响应。
- 第三列type:请求的文档类型。这里为document,代表我们这次请求的是一个HTML文档,内容就是一些HTML代码
- 第四列initiator:请求源。用来标记请求是由哪个对象或进程发起的。
- 第五列size:从服务器下载的文件和请求的资源大小。如果是从缓存中取得的资源,则该列会显示fromcache
- 第六列time:发送请求到获取响应所用的总时间。
- 第七列waterfall:网络请求的可视化瀑布流
首先是general部分,request URL为请求的URL;request method为请求的方法,status code为响应状态码,remote address为远程的服务器的地址和端口,referrer policy为referraer判别策略。
再继续往下,可以看到,有response headers和request headers,这分别代表响应头和请求头。请求头里带有许多请求信息,例如浏览器标识、cookies、host等信息,这是请求的一部分,服务器会根据请求头内的信息判断是否合法,进而作出对应的响应。response headers就是响应的一部分,例如其中包含了服务器的类型、文档类型、日期等信息,浏览器接受到响应后,会解析响应内容,进而呈现网页内容。
请求
请求,由客户端向服务端发出,可以分为4部分内容:请求方法(request Method)、请求的网址(request URL)、请求头(request headers)、请求体(request Body)
请求方法
常见的请求方法有两种:get和post。
在浏览器中直接输入URL并回车,这便发起了一个get请求,请求的参数会直接包含到URL里。例如,在百度中搜索Python,这就是一个get请求,链接为https://www.baidu.com/s?wd=python,其中URL中包含了请求的参数信息,这里参数wd表示要搜寻的关键字。post请求大多在表单的提交时发起。比如,对于一个登录表单,输入用户名和密码后,点击"登录"按钮,这通常会发起一个post请求,其数据通常以表单的形式传输,而不会体现在URL中。
get和post请求方法有如下区别:
GET请求中的参数包含在URL里面,数据可以在URL中看到,而post请求的URL不会包含这些数据,数据都是通过表单形式传输的,会包含在请求体中。
GET请求提交的数据最多只有1024字节,而post请求没有限制。
一般来说,登录时,需要提交用户名和密码,其中包含了敏感信息,使用get方式请求的话,密码就会暴露在URL里面,造成密码泄露,所以这里最好以post方式发送。上传文件时,由于文件内容比较大,也会选用post方式。
我们平时遇到的绝大部分请求都是get或post请求,另外还有一些请求方法,如head、put、delete、options、connect、trace等:
- get 请求页面,并返回页面内容
- head 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头
- post 大多用于提交表单或上传文件,数据包含在请求体中
- put 从客户端向服务器传送的数据取代指定文档中的内容
- delete 请求服务器删除指定的页面
- connect 把服务器当做跳板,让服务器代替客户端访问其他网页
- options允许客户端查看服务器的性能
- trace回显服务器收到的请求,主要用于测试或诊断
请求的网址,即统一资源定位符URL,它可以唯一确定我们想请求的资源。
请求头
请求头,用来说明服务器要使用的附加信息,比较重要的信息有 Cookie、Referer、User-Agent 等。下面简要说明一些常用的头信息。
- Accept:请求报头域,用于指定客户端可接受哪些类型的信息。
Accept-Language:指定客户端可接受的语言类型。
Accept-Encoding:指定客户端可接受的内容编码。
Host:用于指定请求资源的主机 IP 和端口号,其内容为请求 URL 的原始服务器或网关的位置。从 HTTP 1.1 版本开始,请求必须包含此内容。
Cookie:也常用复数形式 Cookies,这是网站为了辨别用户进行会话跟踪而存储在用户本地的数据。它的主要功能是维持当前访问会话。例如,我们输入用户名和密码成功登录某个网站后,服务器会用会话保存登录状态信息,后面我们每次刷新或请求该站点的其他页面时,会发现都是登录状态,这就是 Cookies 的功劳。Cookies 里有信息标识了我们所对应的服务器的会话,每次浏览器在请求该站点的页面时,都会在请求头中加上 Cookies 并将其发送给服务器,服务器通过 Cookies 识别出是我们自己,并且查出当前状态是登录状态,所以返回结果就是登录之后才能看到的网页内容。
Referer:此内容用来标识这个请求是从哪个页面发过来的,服务器可以拿到这一信息并做相应的处理,如做来源统计、防盗链处理等。
User-Agent:简称 UA,它是一个特殊的字符串头,可以使服务器识别客户使用的操作系统及版本、浏览器及版本等信息。在做爬虫时加上此信息,可以伪装为浏览器;如果不加,很可能会被识别出为爬虫。
Content-Type:也叫互联网媒体类型(Internet Media Type)或者 MIME 类型,在 HTTP 协议消息头中,它用来表示具体请求中的媒体类型信息。例如,text/html 代表 HTML 格式,image/gif 代表 GIF 图片,application/json 代表 JSON 类型,更多对应关系可以查看此对照表:http://tool.oschina.net/commons。
请求体
请求体一般承载的内容是post请求中的表单数据,而对于get请求,请求体则为空。
在爬虫中,如果要构造post请求,需要使用正确的content-type,并了解各种请求库的各个参数设置时使用的是哪种content-type,不然可能会导致post提交后无法正常使用。
响应
响应,由服务端返回给客户端,可以分为三部分:响应状态码(response status code)、响应头(response headers)和响应体(response body)。
响应状态码
响应状态码表示服务器的响应状态,如 200 代表服务器正常响应,404 代表页面未找到,500 代表服务器内部发生错误。在爬虫中,我们可以根据状态码来判断服务器响应状态,如状态码为 200,则证明成功返回数据,再进行进一步的处理,否则直接忽略。下表列出了常见的错误代码及错误原因。
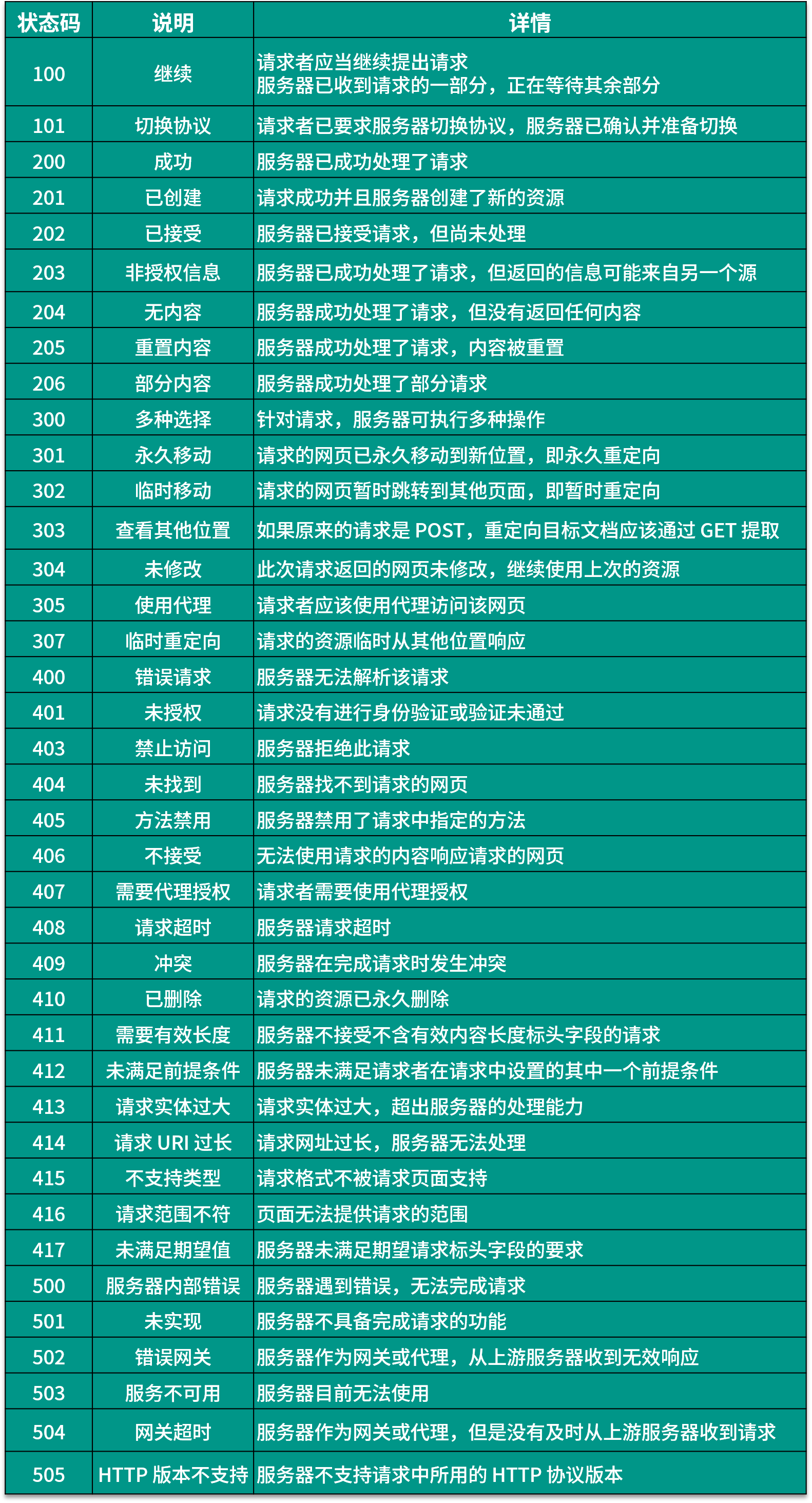
HTTP请求过程和状态响应码的更多相关文章
- HTTP协议中request报文请求方法和状态响应码
一个HTTP请求报文由4部分组成: 请求行(request line) 请求头部(header) 空行 请求数据 下图给出了请求报文的一般格式: 请求行中包括了请求方法,常见的请求方法有: GET:从 ...
- 简述HTTP报文请求方法和状态响应码
1. Method 请求方法,表明客户端希望服务器对资源执行的动作: 1.1 GET 向服务器请求资源. 1.2 HEAD 和GET方法的行为类似,但服务器在响应中只返回首部,不会返回实体的主体部分. ...
- HTTP 状态响应码 意思详解/大全
HTTP 状态响应码 意思详解/大全 转:http://blog.csdn.net/helin916012530/article/details/29842595 HTTP状态码(HTTP Statu ...
- HTTP状态响应码解析
# HTTP响应状态码 ## 1xx:临时响应 #### 表示临时响应并需要请求者继续执行操作的状态代码. 100 **继续**请求者应当继续提出请求.服务器返回此代码表示已收到请求的第一部分,正在等 ...
- http状态响应码对照表
1xx - 信息提示 这些状态代码表示临时的响应.客户端在收到常规响应之前,应准备接收一个或多个 1xx 响应. ·0 - 本地响应成功. · 100 - Continue 初始的请求已 ...
- http请求返回响应码的意思
HTTP 状态响应码 意思详解/大全 HTTP状态码(HTTP Status Code)是用以表示网页服务器HTTP响应状态的3位数字代码.它由 RFC 2616 规范定义的,并得到RFC 2518. ...
- HTTP 笔记与总结(2 )HTTP 协议的(请求行的)请求方法 及 (响应行的)状态码
(请求行的)请求方法 包括: GET,POST,HEAD,PUT,TRACE,DELETE,OPTIONS 注意:这些请求方法虽然是 HTTP 协议规定的,但是 Web Server 未必允许或支持这 ...
- HTTP状态码(响应码)
HTTP状态码(响应码)用来表明HTTP请求是否已经成功完成.HTTP响应类型一共分五大类:消息响应,成功响应,重定向,客户端错误,服务器端错误. 下表列出了所有HTTP状态码,以及他们各自所代表的含 ...
- http请求返回响应码及意义
http 响应码及意义 HTTP状态码(HTTP Status Code)是用以表示网页服务器HTTP响应状态的3位数字代码.它由 RFC 2616 规范定义的,并得到RFC 2518.RFC 281 ...
随机推荐
- 使用Hot Chocolate和.NET 6构建GraphQL应用(3) —— 实现Query基础功能
系列导航 使用Hot Chocolate和.NET 6构建GraphQL应用文章索引 需求 在本文中,我们通过一个简单的例子来看一下如何实现一个最简单的GraphQL的接口. 实现 引入Hot Cho ...
- C++ STL:std::unorderd_map 物理结构详解
拉链法的 unordered_map 和你想象中的不一样 根据数组+拉链法的描述,我们很快能想到下面这样的拉链法实现的哈希表,但真的是这样吗?一起看下源码里的实现是怎么样的. 深入STL源码 代码不会 ...
- GAN入门
1 GAN基本概念 1.1 什么是生成对抗网络? 生成对抗网络(GAN, Generative adversarial network) 在 2014 年被 Ian Goodfellow 提出. GA ...
- python 小兵面向对象
Python 面向对象 Python从设计之初就已经是一门面向对象的语言,正因为如此,在Python中创建一个类和对象是很容易的.本章节我们将详细介绍Python的面向对象编程. 如果你以前没有接触过 ...
- 在java中静态方法与非静态方法
在java中public void与public static void有什么区别 ? public void 修饰是非静态方法,该类方法属于对象,在对象初始化(new Object())后才能被调用 ...
- element-ui 使用 Select 组件给 value 属性绑定对象类型
qq_36437172 2020-06-28 22:38:49 778 收藏 分类专栏: element-ui 文章标签: element-ui Select 组件 value 属性 绑定 对象类 ...
- Jenkins敏捷开发 自动化构建工具
一.序言 Jenkins 是一款自动化构建工具,能够基于 Maven 构建后端 Java 项目,也能够基于 nodejs 构建前端 vue 项目,并且有可视化 web 界面. 所谓自动化构建是按照一定 ...
- 编译安装基于fastcgi模式的多虚拟主机的wordpress和discuz的LAMP架构
一.环境准备 两台主机: httpd+php(fastcgi模式) mariadb 服务器 软件版本: mariadb-10.2.40-linux-x86_64.tar.gz apr-1.7.0.ta ...
- mysql查询的时候没有加order by时的默认排序问题
有时候我们执行MySQL查询的时候,查询语句没有加order by,但是发现结果总是已经按照id排序好了的,难道MySQL就是为了好看给我们排序 如上图数据,是我查询了语句 SELECT * from ...
- 9、Linux基础--编译安装、压缩打包、定时任务
笔记 1.晨考 1.搭建yum私有仓库的步骤 1.安装工具 yum install createrepo yum-utils nginx -y 2.创建目录 mkdir /opt/test 3.创建包 ...