Selenium_元素定位(2)
Selenium操作页面上的文本输入框、按钮、单选框、复选框等,凡是能在页面显示的任何元素都需要先对元素进行定位。
Selenium提供了以下方法来定位页面中元素:
- find_element_by_id:通过id属性值进行匹配查找,返回匹配到的第一个元素,未匹配到就报错
- find_element_by_name:通过name属性值进行匹配查找,返回匹配到的第一个元素,未匹配到就报错
- find_element_by_link_text:通过链接内容进行完全匹配查找,返回匹配到的第一个元素,未匹配到就报错
- find_element_by_partical_link_text:通过链接内容进行模糊匹配查找,返回匹配到的第一个元素,未匹配到就报错
- find_element_by_tag_name:通过html标签名称进行匹配查找,返回匹配到的第一个元素,未匹配到就报错
- find_element_by_class_name:通过class属性值进行匹配查找,返回匹配到的第一个元素,未匹配到就报错
- find_element_by_xpath:通过xpath进行匹配查找,返回匹配到的第一个元素,未匹配到就报错
- find_element_by_css_selector:通过CSS选择器进行匹配查找,返回匹配到的第一个元素,未匹配到就报错
上面方法只会匹配查找只会获取第一个元素。除了上面这些查找单个元素的方法之外,Selenium还定义查找多个元素的方法:
- find_elements_by_id:通过id属性值进行匹配查找,返回所有匹配到的元素列表,未匹配到返空列表
- find_elements_by_name:通过name属性值进行匹配查找,返回所有匹配到的元素列表,未匹配到返空列表
- find_elements_by_link_text:通过链接内容进行完全匹配查找,返回所有匹配到的元素列表,未匹配到返空列表
- find_elements_by_partical_link_text:通过链接内容进行模糊匹配查找,返回所有匹配到的元素列表,未匹配到返空列表
- find_elements_by_tag_name:通过html标签名称进行匹配查找,返回所有匹配到的元素列表,未匹配到返空列表
- find_elements_by_class_name:通过class属性值进行匹配查找,返回所有匹配到的元素列表,未匹配到返空列表
- find_elements_by_xpath:通过xpath进行匹配查找,返回所有匹配到的元素列表,未匹配到返空列表
- find_elements_by_css_selector:通过CSS选择器进行匹配查找,返回所有匹配到的元素列表,未匹配到返空列表
by_id
当知道元素的id属性后,可以使用该方法定位元素。
假如页面元素代码如下
<input id="username" type="text">
<input id="username" type="text">
可以这样定位元素
el = driver.find_element_by_id("username")
print(el)
els = driver.find_elements_by_id("username")
print(els)
打印定位的元素

by_name
当知道元素的name属性后,可以使用该方法定位元素。
假如页面元素代码如下
<input type="text" name="username" id="username">
<input type="text" name="username" id="username">
可以这样定位元素
el = driver.find_element_by_name("username")
print(el)
els = driver.find_elements_by_name("username")
print(els)
by_link_text
当知道链接元素的内容后,可以使用该方法定位元素。该方法需要完全匹配链接中的内容,若只是部分匹配链接中的内容则定位不到该元素。
假如页面元素代码如下
<a href="#">标签a</a>
可以这样定位元素
el = driver.find_element_by_link_text("标签a")
print(el)
els = driver.find_elements_by_link_text("标签a")
print(els)
el = driver.find_element_by_link_text("标签") # 报错
print(el)
by_partical_link_text
当知道链接元素的内容后,可以使用该方法定位元素。该方法可以部分匹配链接中的内容。
假如页面元素代码如下
<a href="#">标签a</a>
<a href="#">标签b</a>
可以这样定位元素
el = driver.find_element_by_partial_link_text("标签") # 返回标签a元素
print(el)
els = driver.find_elements_by_partial_link_text("标签") # 返回标签a、标签b元素
print(els)
by_tag_name
通过html标签定位元素。
假如页面元素代码如下
<div>元素1</div>
<div>元素2</div>
可以这样定位元素
el = driver.find_element_by_tag_name("div")
print(el)
els = driver.find_elements_by_tag_name("div")
print(els)
by_class_name
通过class属性值定位元素。
假如页面元素代码如下
<div class="el">元素1</div>
<div class="el">元素2</div>
可以这样定位元素
el = driver.find_element_by_class_name("el")
print(el)
els = driver.find_elements_by_class_name("el")
print(els)
by_xpath
XPath 是一门在 XML 文档中查找信息的语言。基于XML的树状结构,XPath提供在数据结构树中找寻节点的能力。
使用chrome自带的xpath定位元素的方法如下:
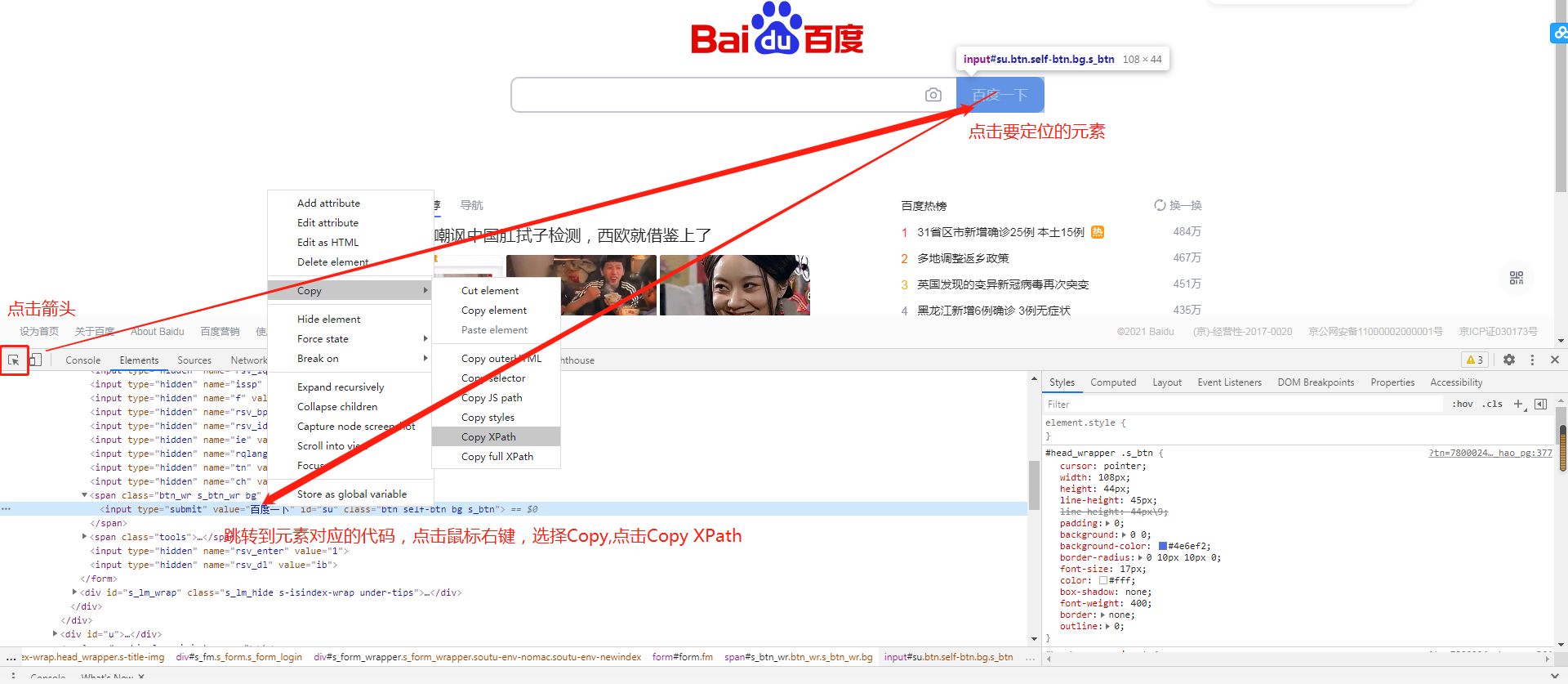
复制出来的XPath地址如下
//*[@id="su"] # 选取文档中id值为su的元素
说明:
- //*:选取文档中的所有元素。
- @:选取属性
selenium使用xpath定位效率上比上面的方法底,但胜在灵活性高。
使用xpath通过元素内容定位
假如页面元素代码如下
<a href="#">标签a</a>
可以这样定位元素
# 类似于by_link_text,通过参数值(标签a)精准匹配包含该值的元素
el1 = driver.find_element_by_xpath("//*[text()='标签a']")
print(el1) # 类似于by_partial_link_text,通过参数值(标签)模糊匹配包含该值的元素
el2 = driver.find_element_by_xpath("//*[contains(text(), '标签')]")
print(el2)
定位结果

使用xpath通过元素属性定位
假如页面元素代码如下
<input type="text" name="username" id="username" placeholder="用户名">
<div class="el">元素1</div>
可以这样定位
el1 = driver.find_element_by_xpath("//*[@name='username']") # 定位元素name属性值为"username"的元素
print(el1)
el2 = driver.find_element_by_xpath("//*[@placeholder='用户名']") # 定位元素placeholder属性值为"用户名"的元素
print(el2)
el3 = driver.find_element_by_xpath("//*[@class='el']") # 定位元素class属性值为"el"的元素
print(el3)
定位结果

使用xpath层级定位
假如页面代码如下
<div class="el">
<span><a href="#">元素1</a></span>
<span id="me"><a href="#">元素2</a></span>
</div>
可以这样定位
# 定位子级元素
el = driver.find_element_by_xpath("//*[@id='me']/a") # 定位id值为me下的a标签
print(el)
# 通过已定位元素定位子级元素
el_me = driver.find_element_by_id("me")
el1 = el_me.find_element_by_xpath("a") # 定位该元素下的a标签
print(el1) # 定位父级元素
el = driver.find_element_by_xpath("//*[@id='me']/..")
print(el)
# 通过已定位元素定位父级元素
el = el_me.find_element_by_xpath("..")
print(el) # 定位同级元素
el = driver.find_element_by_xpath("//*[@id='me']/../span[1]")
print(el)
# 通过已定位元素定位同级元素
el = el_me.find_element_by_xpath("../span[1]") # 如果一个元素有多个相同标签,可以通过索引定位指定标签,索引值从1开始
print(el)
定位结果

使用xpath定位包含某属性的所有元素
假如页面代码如下
<div class="el">
<span><a href="#">元素1</a></span>
<span id="me"><a href="#">元素2</a></span>
</div>
可以这样定位
els = driver.find_elements_by_xpath("//*[@href]")
print(f"包含href属性的元素个数为:{len(els)}")
定位结果

by_css_selector
css_selector和xpath类似,该方法是基于css选择器对元素进行定位。
使用css_selector通过属性id定位元素
假如页面代码如下
<input type="text" name="username" id="username" placeholder="用户名">
可以这样定位
el = driver.find_element_by_css_selector("#username") # 井号表示属性id
print(el)
使用css_selector通过属性class定位元素
假如页面代码如下
<div class="el">元素1</div>
可以这样定位
el = driver.find_element_by_css_selector(".el")
print(el)
使用css_selector通过指定属性定位元素
假如页面代码如下
<input type="text" name="username" id="username" placeholder="用户名">
可以这样定位
# 通过属性定位
el = driver.find_element_by_css_selector("[placeholder='用户名']") # 匹配元素的placeholder属性值为'用户名'的元素
print(el) # 通过标签+属性定位
el = driver.find_element_by_css_selector("input[placeholder='用户名']") # 匹配元素的标签为input且其placeholder属性值为'用户名'的元素
print(el) # 通过多属性定位
el1 = driver.find_element_by_css_selector("#username[placeholder='用户名'][type='text']")
el2 = driver.find_element_by_css_selector("input#username[placeholder='用户名'][type='text']")
print(el1 == el2)
定位结果

使用css_selector通过模糊匹配属性值定位元素
假如页面代码如下
<input type="text" name="username" id="username" placeholder="用户名">
可以这样定位
# 模糊匹配
el = driver.find_element_by_css_selector("[name^=user]") # 匹配name属性以user开头的元素
print(el)
el = driver.find_element_by_css_selector("[id$=name]") # 匹配id属性以name结尾的元素
print(el)
el = driver.find_element_by_css_selector("[placeholder*=户]") # 匹配placeholder属性包含户字的元素
print(el)
定位结果

使用css_selector层级定位
假如页面代码如下
<div class="el">
<span><a href="#">元素2</a></span>
<span id="me"><a href="#">元素2</a></span>
</div>
可以这样定位
# 定位子级元素
# 直接定位子集元素
el = driver.find_element_by_css_selector("#me > a:nth-child(1)") # 定位id为me元素下的第一个a标签,若有且只有1个a标签可以不写:后的内容
print(el)
el = driver.find_element_by_css_selector("#me a:nth-child(1)") # 定位id为me元素下的第一个a标签,若有且只有1个a标签可以不写:后的内容
print(el) # 通过已知元素定位子级元素
el_me = driver.find_element_by_id("me")
el = el_me.find_element_by_css_selector("a:nth-child(1)")
print(el)
注:层级与层级之间以大于号>或空格分层,查找元素定位必须一层一层往下写,有多个则匹配多个
定位结果

使用css_selector定位包含某属性的所有元素
假如页面代码如下
<div class="el">
<span><a href="#">元素1</a></span>
<span id="me"><a href="#">元素2</a></span>
</div>
可以这样定位
els = driver.find_elements_by_css_selector("[href]")
print(f"包含href属性的元素个数为:{len(els)}")
定位结果
Selenium_元素定位(2)的更多相关文章
- selenium元素定位篇
Selenium webdriver是完全模拟用户在对浏览器进行操作,所有用户都是在页面进行的单击.双击.输入.滚动等操作,而webdriver也是一样,所以需要我们指定元素让webdriver进行单 ...
- Uiautomator--Uiselector元素定位
一.UiSelector作用 按照一定的条件(例如控件的text值,资源id),定位界面上的元素.UiSelector对象的最终目的是去构造一个UiObject对象. 二.元素定位 1.根据text定 ...
- selenium使用笔记(三)——元素定位
selenium进行自动化测试的一个很重要的东西那就是元素定位,如果元素都没法定位就无法操作它,也就无法进行自动化测试了.网上对于元素定位有很多的介绍,很详细很详细的,但是依然有很多新手总是会遇到无法 ...
- java selenium (五) 元素定位大全
页面元素定位是自动化中最重要的事情, selenium Webdriver 提供了很多种元素定位的方法. 测试人员应该熟练掌握各种定位方法. 使用最简单,最稳定的定位方法. 阅读目录 自动化测试步骤 ...
- CSS元素定位6-10课
<精通CSS.DIV网页样式与布局>视频6-10课总结图: 元素定位 (1)float:left/right; 左浮动:脱离普通文档流向左浮动(即向左对齐):float属性必须应用在块级元 ...
- python学习之——selenium元素定位
web自动化测试按步骤拆分,可以分为四步操作:定位元素,操作元素,获取返回结果,断言(返回结果与期望结果是否一致),最后自动出测试报告. 其中定位元素尤为关键,此篇是使用webdriver通过页面各个 ...
- python + selenium相关事件和元素定位
女友由于工作上的失误,将公司RDM中的某一字段的2000条数据给删除了.....就算是重新添加字段,但是与其他数据的关联性已经不在了.由于每天的数据修改量大,有关部门不愿意恢复数据库,因此只能一条条的 ...
- Selenium定位一 --单个元素定位方法
Selenium-Webdriver 提供了强大的元素定位方法,支持以下三种方法. 单个对象的定位方法 多个对象的定位方法 层级定位 定位单个元素在定位单个元素时,selenium-webdriver ...
- Selenium2+python自动化6-八种元素元素定位(Firebug和firepath)
前言 自动化只要掌握四步操作:获取元素,操作元素,获取返回结果,断言(返回结果与期望结果是否一致),最后自动出测试报告.本篇主要讲如何用firefox辅助工具进行元素定位. 元素定位在这四个环节中是至 ...
随机推荐
- JSP中session、cookie和application的使用
一.session (单用户使用) 1.用处:注册成功后自动登录,登录后记住用户状态等 使用会话对象session实现,一次会话就是一次浏览器和服务器之间的通话,会话可以在多次请求中保存和使用数据. ...
- ASP.NET Core中使用滑动窗口限流
滑动窗口算法用于应对请求在时间周期中分布不均匀的情况,能够更精确的应对流量变化,比较著名的应用场景就是TCP协议的流量控制,不过今天要说的是服务限流场景中的应用. 算法原理 这里假设业务需要每秒钟限流 ...
- DT10功能介绍--DT10多波示波器
功能介绍 有些嵌入式软件方面的问题,利用传统的调试器可能无法解决,而通过逻辑分析器则能有效地解决.请仔细阅读本文, 看我们如何一步一步地讲解在这种情况下所需的配置. 但是,从传统意义上讲,逻辑分析器是 ...
- Python matplotlib绘制圆环图
一.语法和参数简介 plt.pie(x2,labels=labels, autopct = '%0.2f%%', shadow= False, startangle =0,labeldistance= ...
- python解释器安装指导教程
python解释器安装指导教程 1.官网下载 进入官网https://www.python.org/,在download下选择符合操作系统的版本 在找到合适的版本后选择相应的安装文件下载 2.进行安装 ...
- linux小应用 —— 日志过滤
先说问题,统计一个日志文件中去重之后的ip地址的个数.其实这是一个非常常见也比较简单的问题,其中我个人认为最主要的应该是匹配ip地址是这个问题的核心.剩下的就是对linux命令的熟练程度的问题了.首先 ...
- 转:Android控件属性
Android功能强大,界面华丽,但是众多的布局属性就害苦了开发者,下面这篇文章结合了网上不少资料,花费本人一个下午搞出来的,希望对其他人有用. 第一类:属性值为true或false android: ...
- USACO 2021 Contest 1 Bronze 题解
蒟蒻第一次打 USACO,只打了 Bronze 就跑路了.不得不说也有很有意思的题目.接下来就看看题目吧. 由于现在还看不到题目,只给出加工后的题目大意. T1 Lonely Photo Conten ...
- CF1569A Balanced Substring 题解
Content 给定一个长度为 \(n\) 且仅包含字符 a.b 的字符串 \(s\).请找出任意一个使得 a.b 数量相等的 \(s\) 的子串并输出其起始位置和终止位置.如果不存在请输出 -1 - ...
- java 图形化小工具Abstract Window Toolit
老掉牙的历史 Java1.0在发布的时候,就为我们提供了GUI操作的库,这个库系统在所有的平台下都可以运行,这套基本的类库被称作抽象窗口工具集(Abstract Window Toolit),简称 ...