减轻内存负担,在 pymysql 中使用 SSCursor 查询结果集较大的 SQL
前言
默认情况下,使用 pymysql 查询数据使用的游标类是 Cursor,比如:
import pymysql.cursors
# 连接数据库
connection = pymysql.connect(host='localhost',
user='user',
password='passwd',
db='db',
charset='utf8mb4')
try:
with connection.cursor() as cursor:
# 读取所有数据
sql = "SELECT `id`, `password` FROM `users` WHERE `email`=%s"
cursor.execute(sql, ('webmaster@python.org',))
result = cursor.fetchall()
print(result)
finally:
connection.close()
这种写法会将查询到的所有数据写入内存中,若在结果较大的情况下,会对内存造成很大的压力,所幸 pymysql 实现了一种 SSCursor 游标类,它允许将查询结果按需返回,而不是一次性全部返回导致内存使用量飙升。
SSCursor
官方文档的解释为:
Unbuffered Cursor, mainly useful for queries that return a lot of data,
or for connections to remote servers over a slow network.Instead of copying every row of data into a buffer, this will fetch
rows as needed. The upside of this is the client uses much less memory,
and rows are returned much faster when traveling over a slow network
or if the result set is very big.There are limitations, though. The MySQL protocol doesn't support
returning the total number of rows, so the only way to tell how many rows
there are is to iterate over every row returned. Also, it currently isn't
possible to scroll backwards, as only the current row is held in memory.
大致翻译为:无缓存的游标,主要用于查询大量结果集或网络连接较慢的情况。不同于普通的游标类将每一行数据写入缓存的操作,该游标类会按需读取数据,这样的好处是客户端消耗的内存较小,而在网络连接较慢或结果集较大的情况下,数据的返回也会更快。当然,缺点就是它不支持返回结果的行数(也就是调用 rowcount 属性将不会得到正确的结果,一共有多少行数据则需要全部迭代完成才能知道),当然它也不支持往回读取数据(这也很好理解,毕竟是生成器嘛)。
它的写法如下:
from pymysql.cursors import SSCursor
connection = pymysql.connect(host='localhost',
user='user',
password='passwd',
db='db',
charset='utf8mb4')
# 创建游标
cur = connection.cursor(SScursor)
cur.execute('SELECT * FROM test_table')
# 读取数据
# 此时的 cur 对内存消耗相对 Cursor 类来说简直微不足道
for data in cur:
print(data)
本质上对所有游标类的迭代都是在不断的调用 fetchone 方法,不同的是 SSCursor 对 fetchone 方法的实现不同罢了。这一点查看源码即可发现:
Cursor 类 fetchone 方法源码(可见它是在根据下标获取列表中的某条数据):
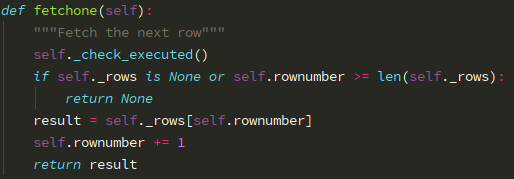
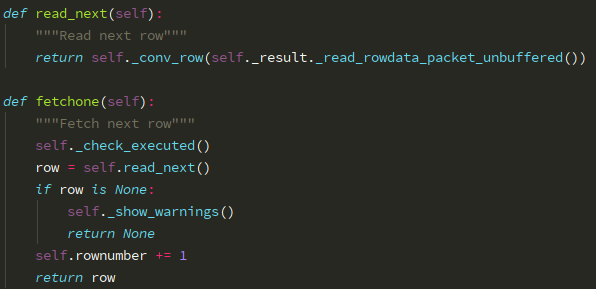
SSCursor 类 fetchone 方法源码(读取数据并不做缓存):
跳坑
当然,如果没有坑就没必要为此写一篇文章了,开开心心的用着不香吗。经过多次使用,发现在使用 SSCursor 游标类(以及其子类 SSDictCursor)时,需要特别注意以下两个问题:
1. 读取数据间隔问题
每条数据间的读取间隔若超过 60s,可能会造成异常,这是由于 MySQL 的 NET_WRITE_TIMEOUT 设置引起的错误(该设置值默认为 60),如果读取的数据有处理时间较长的情况,那么则需要考虑更改 MySQL 的相关设置了。(tips: 使用 sql SET NET_WRITE_TIMEOUT = xx 更改该设置或修改 MySQL配置文件)
2. 读取数据时对数据库的其它操作行为
因为 SSCursor 是没有缓存的,只要结果集没有被读取完成,就不能使用该游标绑定的连接进行其它数据库操作(包括生成新的游标对象),如果需要做其它操作,应该使用新的连接。比如:
from pymysql.cursors import SSCursor
def connect():
connection = pymysql.connect(host='localhost',
user='user',
password='passwd',
db='db',
charset='utf8mb4')
return connection
conn1 = connect()
conn2 = connect()
cur1 = conn1.cursor(SScursor)
cur2 = conn1.cursor()
with conn1.cursor(SSCursor) as ss_cur, conn2.cursor() as cur:
try:
ss_cur.execute('SELECT id, name FROM test_table')
for data in ss_cur:
# 使用 conn2 的游标更新数据
if data[0] == 15:
cur.execute('UPDATE tset_table SET name="kingron" WHERE id=%s', args=[data[0])
print(data)
finally:
conn1.close()
conn2.close()
参考
- Cursor Objects — PyMySQL 0.7.2 documentation
- Using SSCursor (streaming cursor) to solve Python using pymysql to query large amounts of data leads to memory usage is too high
减轻内存负担,在 pymysql 中使用 SSCursor 查询结果集较大的 SQL的更多相关文章
- php中mysqli 处理查询结果集的几个方法
最近对php查询mysql处理结果集的几个方法不太明白的地方查阅了资料,在此整理记下 Php使用mysqli_result类处理结果集有以下几种方法 fetch_all() 抓取所有的结果行并且以关联 ...
- php中mysqli 处理查询结果集总结
在PHP开发中,我们经常会与数据库打交道.我们都知道,一般的数据处理操作流程为 接收表单数据 数据入库 //连接数据库 $link = mysqli_connect("my_host&quo ...
- 在 SQL Server 数据库的 WHERE 语句中使用子查询
这是关于子查询语句的一系列文章中的第三篇.在这篇文章中我们将讨论WHERE语句中的子查询语句.其他的文章讨论了其他语句中的子查询语句. 本次课程中的所有例子都是基于Microsoft SQL Serv ...
- C/C++中的内存对齐 C/C++中的内存对齐
一.什么是内存对齐.为什么需要内存对齐? 现代计算机中内存空间都是按照byte划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定类型变量的时候经常在特 定的内存地址 ...
- C++反汇编第五讲,认识多重继承,菱形继承的内存结构,以及反汇编中的表现形式.
C++反汇编第五讲,认识多重继承,菱形继承的内存结构,以及反汇编中的表现形式. 目录: 1.多重继承在内存中的表现形式 多重继承在汇编中的表现形式 2.菱形继承 普通的菱形继承 虚继承 汇编中的表现形 ...
- 【Java并发编程】6、volatile关键字解析&内存模型&并发编程中三概念
volatile这个关键字可能很多朋友都听说过,或许也都用过.在Java 5之前,它是一个备受争议的关键字,因为在程序中使用它往往会导致出人意料的结果.在Java 5之后,volatile关键字才得以 ...
- volatile关键字解析&内存模型&并发编程中三概念
原文链接: http://www.cnblogs.com/dolphin0520/p/3920373.html volatile这个关键字可能很多朋友都听说过,或许也都用过.在Java5之前,它是一个 ...
- DELPHI编写服务程序总结(在系统服务和桌面程序之间共享内存,在服务中使用COM组件)
DELPHI编写服务程序总结 一.服务程序和桌面程序的区别 Windows 2000/XP/2003等支持一种叫做“系统服务程序”的进程,系统服务和桌面程序的区别是:系统服务不用登陆系统即可运行:系统 ...
- (转载)图解Java多态内存分配以及多态中成员方法的特点
图解Java多态内存分配以及多态中成员方法的特点 图解Java多态内存分配以及多态中成员方法的特点 Person worker = new Worker(); 子类实例对象地址赋值给父类类型引 ...
随机推荐
- Study Blazor .NET(三)组件
翻译自:Study Blazor .NET,转载请注明. 关于组件 blazor中组件的基础结构可以分为以下3部分, //Counter.razor //Directives section @pag ...
- 关于阿里云图标的使用 iconfont
iconfont 关于阿里云图标库使用的介绍 对于添加到网页中的iconfont可使用以下几种方式: 首先需要进入阿里云图标库官网进行对应的下载iconfont-阿里巴巴矢量图标库 将需要的图标加入到 ...
- Golang - 关于 proto 文件的一点小思考
目录 前言 helloworld.proto 小思考 小结 推荐阅读 前言 ProtoBuf 是什么? ProtoBuf 是一套接口描述语言(IDL),通俗的讲是一种数据表达方式,也可以称为数据交换格 ...
- Feed系统设计分析(类似微博的用户动态分享问题)
Feed系统 最近在研究一个个人动态分享平台,对动态的推送方式有些疑惑,于是研究到了以下结果. 简介 在信息学里面,Feed其实是一个信息单元,比如一条朋友圈状态.一条微博.一条资讯或一条短视频等,所 ...
- 洛谷 P4564 [CTSC2018]假面(期望+dp)
题目传送门 题意: 有 \(n\) 个怪物,第 \(i\) 个怪物初始血量为 \(m_i\).有 \(Q\) 次操作: 0 x u v,有 \(p=\frac{u}{v}\) 的概率令 \(m_x\) ...
- Codeforces Round #691 (Div. 2) 题解
A 不多说了吧,直接扫一遍求出 \(r_i>b_i\) 的个数和 \(r_i<b_i\) 的个数 B 稍微打个表找个规律就可以发现,当 \(n\) 为奇数的时候,答案为 \(\dfrac{ ...
- Codeforces 986E - Prince's Problem(树上前缀和)
题面传送门 题意: 有一棵 \(n\) 个节点的树,点上有点权 \(a_i\),\(q\) 组询问,每次询问给出 \(u,v,w\),要求: \(\prod\limits_{x\in P(u,v)}\ ...
- 记一次VS2010和VS2015自定义颜色的过程
首先,是遇到的问题: 一天,使用VS2010看新项目代码时候,发现选中某个变量后,其它位置高亮显示的变量颜色太淡,不利于阅读代码,如下图.所以想修改这个颜色. 后来网上找了一遍,可以这样设置:工具-- ...
- 【机器学习与R语言】1-机器学习简介
目录 1.基本概念 2.选择机器学习算法 3.使用R进行机器学习 1.基本概念 机器学习:发明算法将数据转化为智能行为 数据挖掘 VS 机器学习:前者侧重寻找有价值的信息,后者侧重执行已知的任务.后者 ...
- cpu的性能测试
#!/bin/bash #user%加上sys%是性能的评判标准 User_sys_a=`sar -u 1 3 |tail -1 |awk '{print $3"+"$5}'|bc ...